

Un moteur de recherche comme Google ou Bing est loin d'être un système simple pouvant être expliqué en quelques lignes. Il est au contraire l'addition de plusieurs technologies souvent assez complexes, lui permettant de renvoyer à l'internaute qui l'utilise les résultats les plus pertinents. Cette série d'articles vous explique donc quelles sont les différentes briques d'un moteur et vous dévoile les arcanes qui constituent leurs entrailles. Après nos précédents articles sur les technologies de crawl, l'index inversé, le duplicate content, le PageRank thématique et la pertinence, nous abordons ce mois-ci la notion d'analyse et d'éventuelle reformulation de la requête de l'internaute. Comment le moteur prend-il en compte les mots clés tapés par ses utilisateurs et quels sont les traitements effectués pour mieux comprendre leur intention de recherche ? Explications...


 Par Guillaume Peyronnet, Sylvain Peyronnet et Thomas Largillier
Par Guillaume Peyronnet, Sylvain Peyronnet et Thomas Largillier
Ce mois-ci, nous allons voir une étape particulièrement importante, à tel point qu’on pourrait la qualifier de cruciale, du fonctionnement d’un moteur de recherche : il s’agit de l’analyse et la modification de la requête. En effet la requête “brute” fournie par l’utilisateur est souvent insuffisante pour qu’un moteur puisse répondre de manière pertinente et rapide.
Nous allons voir qu’une requête est “travaillée” de différentes manières et qu’un certain nombres de pré-calculs sont effectués par le moteur de recherche pour pouvoir répondre en temps réel ou presque aux demandes des internautes utilisateurs.
Lorsqu’on évoque différents “travaux” sur une même requête, c’est surtout parce que la notion de requête intervient à plusieurs moments de la vie du moteur de recherche. Tout d’abord, la requête a un impact sur la popularité des pages à travers la notion de PageRank thématique. Pour mesurer cet impact, il faut avoir une idée de la catégorisation thématique de chaque requête.
Ensuite, la requête est associée à un certain nombre de signaux de pertinence, car il faut aller au-delà du cosinus de Salton ou de BM25 pour obtenir des résultats de qualité suffisante.
Enfin, pour mieux comprendre la requête, le moteur va tantôt l’étendre, tantôt la reformuler, voire faire les deux opérations, et cette reformulation aura un impact sur une partie des signaux précédemment définis. Nous y reviendrons plus tard, mais ces “travaux” sont nécessaires au moteur pour fournir des SERP de qualité en partie à cause de la brièveté des requêtes qui rend difficile leur compréhension pour le moteur.
La catégorisation de la requête
Nous avions évoqué dans la lettre d’Abondance du mois de mars dernier le concept de PageRank thématique mis au point par Taher Haveliwala (voir la référence [1] pour plus d’information). Cet algorithme a pour but d’affiner la notion de popularité pour améliorer la qualité des SERP proposées.
La figure 1 ci-dessous résume le fonctionnement de ce PageRank thématique. Sur le visuel, on peut observer que la requête, ici “jaguar”, se voit attribuer des pourcentages d’adéquation thématique : 70% à la thématique “animaux” et 30% à la thématique “auto”. Cette attribution permet au moteur de mieux classer les pages en réalisant une forme de filtrage favorisant les pages portant sur les thématiques les plus en adéquation avec la requête.
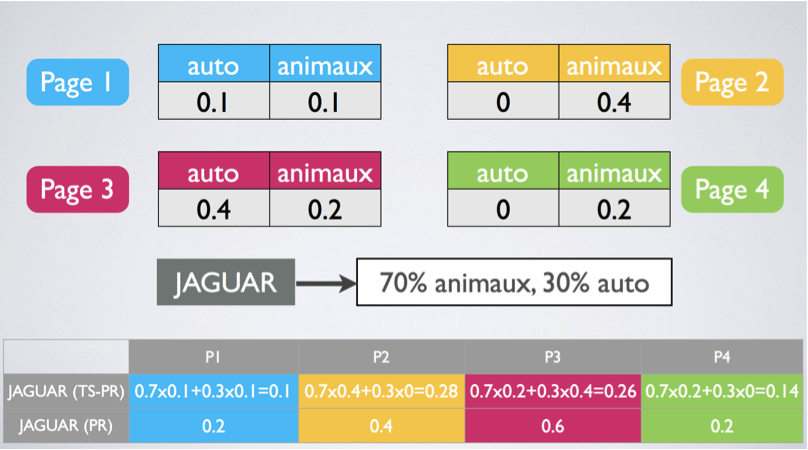
Fig. 1 : le PageRank thématique et l’attribution de la requête à des catégories.
La question qui nous intéresse est de savoir comment est calculée cette adéquation thématique. Ce calcul est loin d’être simple, principalement parce qu’une requête représente un ensemble de très peu de mots, et dans les faits, de bien trop peu de mots. Pour mieux comprendre la requête, il va falloir utiliser une information tierce, et la seule qui va être disponible est celle du jugement humain déformé au travers du prisme des résultats du moteur de recherche.
Pour déterminer la catégorisation d’une requête, on va donc construire une page de résultats de moteur de recherche (SERP) pour cette requête, et on va observer le comportement des humains sur celle-ci (ou bien on fera appel à des Quality Raters). Grâce au comportement des internautes, on va pouvoir déterminer quelles sont les pages qui donnent des résultats qualitatifs pour cette requête.
L’étape suivante consiste à déterminer à quelle catégorie appartient chaque page pertinente, puis à calculer la catégorisation de la requête à partir des résultats qui lui correspondent. Après plusieurs itérations de ce procédé, on obtiendra une catégorisation correcte de la requête, et des résultats qui seront de bonne qualité, même en introduisant de nouvelles pages dans l’index.
Il est intéressant de voir que ce travail est l’inverse de celui que l’on pourrait attendre d’un moteur, en effet il n’utilise pas la catégorisation de la requête pour fournir des pages pertinentes aux utilisateurs mais utilise l’information des pages jugées pertinentes par les utilisateurs pour comprendre la catégorisation d’une requête.
Exemple : la requête “jaguar”
Dans un premier temps nous n’avons pas de catégorisation pour la requête et nous créons une SERP sans utiliser ce type d’information. Imaginons que nous avons trois pages considérées comme pertinentes par les internautes. La première parle à 100% de voitures, la deuxième aborde le sujet des jaguars au Paraguay (il s’agit donc de l’animal) à 90% et explique qu’il accélère moins vite que la voiture (10%) et enfin la troisième est sur la protection des jaguars et leur extinction (100% animal donc).
Au final, on va pouvoir catégoriser la requête en pondérant chacun de ces scores. Sur la thématique "voiture", le score d’adéquation sera de (100+10+0)/3 soit 36,7% et don,c sur la thématique animaux, nous aurons un score de 63,3%. Bien évidemment, en itérant le processus, on obtiendra une caractérisation de plus en plus fine et de plus en plus “juste” de la requête.
Il reste donc maintenant à voir comment on fait pour catégoriser les pages elles-mêmes. Cette tâche est en fait très simple à réaliser. On décide de prendre un échantillon de textes catégorisés par des humains dans des rubriques prédéfinies (sport, actualités, voiture, animaux, etc.) et on fait le choix d’utiliser un algorithme de machine learning afin de créer un classifieur basé sur l’utilisation de termes spécifiques avec une certaine fréquence. Pour parvenir à cela, une grande quantité d’algorithmes sont tout à fait valables, depuis les très connus k-voisins ou C5.0 jusqu’au plus récent RNNs (Recurrent Neural Networks). Avec ces derniers, on a des taux de réussite dépassant très largement les 90% en matière de catégorisation.
Le lecteur désirant en savoir plus sur les algorithmes classiques peut se référer aux livres [2] et [3].
Les signaux et la requête
Nous avons vu dans notre précédent article, le mois dernier, que la pertinence des pages web pour une requête donnée n’était pas faite avec le cosinus de Salton mais avec la fonction BM25.
Nous n’allons pas détailler en profondeur BM25, mais il est utile de savoir que la fonction va utiliser plusieurs fréquences respectives pour chaque mot de l’index. L’une des fréquences correspond à la fréquence dans le document (comme pour la TF-IDF), tandis que l’autre est la fréquence d’apparition du terme dans la requête.
Ces deux fréquences ne sont pas utilisées de la même manière, contrairement à ce qui se passe lorsqu’on utilise le cosinus de Salton. La fréquence des termes dans la requête a un poids beaucoup plus important pour calculer la valeur de BM25 que la fréquence dans le document. C’est très intuitif, étant donné qu’une requête contient peu de mots.
Nous allons voir qu’au-delà de BM25, des algorithmes de reformulation modifient la requête choisie par l’internaute et peuvent aller jusqu'à créer une requête sensiblement différente. C’est pour cela que la plupart des moteurs vont se permettre d’ajouter des signaux assez simplistes pour continuer à s’accrocher aux mots demandés par l’utilisateur malgré la reformulation. On va par exemple avoir des critères du type :
- Quel est le nombre de mots de la requête qu’on trouve dans le document (en % de la taille de la requête) ;
- Quelle est la TF-IDF des mots de la requête ;
- Est-ce que la requête est présente de manière exacte dans le document ? Si oui combien de fois ?
- Où se trouvent les mots de la requête au sein du document ? à quelle distance les uns des autres ?
On le voit, les signaux peuvent être très simples, ou plus compliqués (avec BM25). On trouve au niveau du moteur de recherche une fonction de classement qui agrège tous les signaux, et ce qui fait la spécificité d’un moteur par rapport à un autre est plus souvent les paramètres de cette fonction (et l’index qui a été crawlé) que les algorithmes en eux-même. Les moteurs les plus performants ajustent en permanence les paramètres via un processus automatique qui prend en entrée les SERP et les signaux utilisateurs pour modifier le paramétrage en temps réel.
Expansion et reformulation de la requête
Le moteur de recherche doit “comprendre” la requête, parfois même mieux que l’être humain qui va la formuler. Vous le savez déjà, cette tâche passe principalement par une expansion de requête. Pourquoi ? parce que les requêtes qu’un internaute utilise pour interagir avec un moteur de recherche sont courtes (entre trois et cinq mots généralement), sont ambigües (homonymie par exemple), et enfin sont parfois trop spécifiques (et privent donc de résultats plus larges qui pourraient tout de même faire l’affaire). Pour “comprendre” au mieux la requête, le moteur va utiliser le comportement de ses utilisateurs afin de mieux situer la requête au “centre” des pages qui lui sont pertinentes.
Rétropropagation de la pertinence
Les algorithmes d’expansion de requête sont pour la plupart basés sur un mécanisme de Rétropropagation de la Pertinence (RP) ou de la pseudo-RP. L’idée de cette rétropropagation est la suivante :
- L’utilisateur tape une requête.
- Le moteur renvoie une SERP pour cette requête.
- L’utilisateur va estimer la qualité de certains documents comme étant pertinents ou non pertinents.
- L’algorithme de RP va créer une meilleure représentation de l’information, dans le but d’obtenir des résultats plus proches de ceux que l’humain a validé.
- Le moteur peut renvoyer une SERP modifiée.
Ce processus est bien entendu itératif et on peut le reproduire pour raffiner de plus en plus les résultats. L’intuition derrière ce type d’approche est très simple : il est plus difficile de formuler clairement son besoin informationnel que de déterminer si des documents correspondent à ce besoin i.e. il est quasiment impossible pour l’utilisateur de fournir au moteur la requête que celui-ci aurait choisi pour le besoin informationnel mais il lui est très aisé de sélectionner les documents qui répondent à sa question.
Quand on veut faire des économies sur l’interaction humaine, on fait du pseudo-RP, pour cela on va faire de l’écrémage : on va considérer que les derniers X% du classement sont de mauvaise qualité et faire comme si un être humain avait validé les premiers (100-X)% comme étant pertinents.
L’algorithme de rétropropagation de la pertinence le plus connu (et l’un des plus anciens) a été vu le mois dernier dans la lettre d’Abondance, il s’agit de l’algorithme de Rocchio. Pour rappel, la méthode de Rocchio va calculer un nouveau vecteur en modifiant le vecteur de la requête selon une rétropropagation de la pertinence. On va donc demander à un certain nombre d’utilisateurs de noter les documents du classement en deux ensembles : les documents pertinents, et ceux non pertinents. On va ensuite modifier le vecteur de la requête de la manière suivante :
V’ = a * V + b * centre(documents pertinents) - c * centre(documents non pertinents)
Que signifie cette formule ? Tout d’abord, V est le vecteur de la requête avant reformulation, V’ le vecteur après reformulation, a, b et c sont des paramètres à choisir “pour que ça marche” et centre(X) est le centre de gravité des vecteurs de l’ensemble X.
La méthode de Rocchio va donc créer une requête virtuelle qui contient en plus des mots de la requête réelle des mots qui sont dans le champ lexical des pages que les internautes considèrent pertinentes pour la requête. Cette requête étendue va permettre au moteur de mieux comprendre le besoin informationnel de l’utilisateur et de lui fournir des résultats plus pertinents.
Il existe bien d’autres algorithmes de RP. On peut par exemple faire de la RP probabiliste. Pour cela, on décide, plutôt que de modifier géométriquement le vecteur de la requête, de créer un classifieur qui va estimer la probabilité d’apparition de chaque terme dans un document par rapport à une pertinence estimée par un humain. Cette estimation est possible en comptant le nombre de documents pertinents contenant un terme donné et en divisant ce nombre par le nombre de documents qui sont dans le cluster des documents pertinents.
Le lecteur attentif remarquera ce mot de cluster : l’hypothèse fondamentale des algorithmes de RP est que les documents pertinents sont clusterisables. C’est une hypothèse forte, qui signifie que les champs lexicaux sont très proches entre deux documents pertinents pour une même requête. Une discussion sur ce sujet dépasse largement le cadre de cet article, mais le choix de la fonction de pondération dans le modèle vectoriel va impacter très fortement cette hypothèse de clusterisation.
Pour finir sur l’expansion de requête, il est important de dire que les tous derniers algorithmes, embarqués dans ce qui semble s’appeler Rankbrain, sont principalement du ressort de la rétropropagation de la pertinence. Nous en avons parlé dans un précédent article, mais pour cet algorithme, le moteur commence par calculer (en back-office) les vecteurs correspondant à toutes les requêtes qu’il connaît. Ce calcul est fait avec une méthode de type word2vec (réseaux de neurones).
Ensuite, quand un utilisateur tape une requête :
1. Le moteur transforme la requête en un vecteur grâce à un réseau de neurones.
2. Si cette requête n’a jamais été vue, elle est rajoutée dans la base.
3. Le moteur cherche les vecteurs proches de celui de l’utilisateur dans sa base de vecteurs pré-calculés.
4. La requête de l’utilisateur est enrichie avec les mots présents dans les vecteurs proches qui ne sont pas dans le vecteur de l’utilisateur.
5. Cette nouvelle requête est utilisée pour fournir des résultats qui sont, a priori, bien meilleurs.
On remarque donc que cette méthode est très similaire aux précédentes, sa seule différence étant qu’elle utilise des réseaux de neurones.
Reformulation de la requête
La reformulation de la requête est une tâche différente : plutôt que de construire une requête totalement nouvelle, on va en réécrire une partie. cette réécriture se faisant principalement en remplaçant certains mots. Bien sûr, cette approche n’est pas à opposer à l’expansion de requête et est utilisée conjointement à celle-ci par le moteur.
Il existe plusieurs types de techniques pour faire cette reformulation, mais les grands classiques poursuivent les buts suivants :
• Reformulation d’une requête en utilisant des synonymes pour certains termes ;
• Reformulation par relation conceptuelle ;
• Reformulation par proximité, statistiques, etc. Pour lever des ambiguïtés on va utiliser une information contextuelle. Par exemple, le mot "orange" dans la requête « SAV orange » va correspondre à l’opérateur de téléphonie, tandis que dans la requête « orange pressée » il s’agira du fruit ;
• Reformulation par modification morphologique. Il s’agit ici de transformer les mots en des versions morphologiquement proches. Il peut s’agir de morphologie flexionnelle (deux formes d’un même verbe) ou lexicale (rappeur comme extension du mot rap). Ici on est dans une approche linguistique, difficile à mettre en œuvre pour un moteur.
Nous n’allons pas décrire ici de façon exhaustive tous les algorithmes existant, mais simplement évoquer une approche possible, celle de l’utilisation de mots de substitutions, pour laquelle Google a déposé un brevet au début des années 2010 (voir la référence [4]).
Le principe de cette méthode est de déterminer des termes de remplacement pour élargir le spectre de la recherche en termes de documents. En effet, un problème pour Google est que l’internaute va choisir un mot pour caractériser sa recherche parmi de nombreux mots possibles : on choisit d’écrire « voiture », mais on aurait pu taper « automobile », « bagnole », « caisse », etc.
Le moteur va donc chercher des termes qui sont des bons substituts, de manière statistique. Il ne s’agit pas à proprement parler de synonyme puisque ce sont plutôt des données d’usage. Au contraire, il s’agit de trouver les termes qui apparaissent comme étant très présents dans les résultats pour la requête de base, puis de considérer ces termes comme étant de possibles substituts, ce que l’on peut vérifier statistiquement en regardant les requêtes qui utilisent ces termes.
Cette approche se retrouve également, au moins dans son principe, dans ce que Bill Slawski avait appelé « le brevet hummingbird » et dont le nom est « Synonym identification based on co-occurring terms » (voir les références [5] et [6]). L’idée d’utiliser la co-occurrence n’est pas neuve chez Google. Elle est d’ailleurs très classique en information retrieval, avec des brevets par Xerox et NEC avant 2000, et même un article scientifique datant de 1977 sur le sujet de la co-occurrence (référence [7]).
Cette méthode va permettre d’analyser les termes qui sont présents ensemble et inférer le sens des termes grâce à cette information. Le terme « voiture » est par exemple ambigu : il peut avoir le sens d’« automobile » ou le sens de « wagon », il doit donc être traité pour lever l'ambiguïté lorsque le moteur le rencontre.
Ainsi, lorsque l’internaute saisit la requête « Quel est le numéro de la voiture bar dans le train ? », le moteur va regarder d’une part la probabilité d’avoir les mots « wagon », « bar » et « train » ensemble dans un texte, et d’autre part la probabilité d’avoir « automobile », « bar » et « train » ensemble. De cette façon, il va inférer que l’internaute cherche le numéro d’un wagon d’un train, qui contient le bar.
Cela paraît simple, et ça l’est, et c’est également très efficace. Cela reste cependant basé sur des informations statistiques.
Conclusion
L’expansion et la reformulation de requête sont deux briques incontournables pour un moteur de recherche moderne qui veut atteindre un niveau de qualité satisfaisant. En matière de référencement, ces algorithmes légitiment le travail sur le contenu, en particulier sur la création de contenu de qualité, avec des informations factuelles très pertinentes. Si vous soignez plus particulièrement la qualité de vos textes sur le Web, vous êtes sur le bon chemin...
Références
[1] Haveliwala, T. H. (2003). Topic-sensitive PageRank: A context-sensitive ranking algorithm for web search. Knowledge and Data Engineering, IEEE Transactions on, 15(4), 784-796.
http://ilpubs.stanford.edu:8090/750/1/2003-29.pdf
[2] Hastie T., Tibshirani R., Friedman J. (2001) The Elements of Statistical Learning, Data Mining, Inference, and Prediction, Springer.
[3] Manning C.D., Raghavan P., and Schütze H., Introduction to Information Retrieval, Cambridge University Press. 2008.
[4] Ikeda, Daisuke, and Ke Yang. "Evaluation of substitute terms." U.S. Patent No. 8,504,562. 6 Aug. 2013.
https://www.google.com/patents/US8504562
[5] Slawski, B. (2013). The Google Hummingbird Patent?
http://www.seobythesea.com/2013/09/google-hummingbird-patent/
[6] Mahabal, Abhijit A., et al. "Synonym identification based on co-occurring terms." U.S. Patent No. 8,538,984. 17 Sep. 2013.
https://www.google.com/patents/US8538984
[7] Van Rijsbergen, C. J. (1977). A theoretical basis for the use of co-occurrence data in information retrieval. Journal of documentation, 33(2), 106-119.
http://www.emeraldinsight.com/doi/abs/10.1108/eb026637
![]() Thomas Largillier, Guillaume Peyronnet et Sylvain Peyronnet sont les fondateurs de la régie publicitaire sans tracking The Machine In The Middle (http://themachineinthemiddle.fr/).
Thomas Largillier, Guillaume Peyronnet et Sylvain Peyronnet sont les fondateurs de la régie publicitaire sans tracking The Machine In The Middle (http://themachineinthemiddle.fr/).

 de nous rejoindre
de nous rejoindre