
![]()
Depuis que le Web existe, on dit que le contenu est roi ("Content is King") et cette tendance s'est renforcée au fil des ans. Aujourd'hui, le travail sur les champs lexicaux d'un contenu est devenu indispensable et de nombreux outils (souvent développés par des entreprises françaises) voient le jour. Parmi eux, SEOQuantum a pour vocation d'aider les rédacteurs web à rédiger des textes ayant une meilleure richesse sémantique en s'aidant des dernières avancées algorithmiques du domaine. Leur but ? Plaire bien sûr aux internautes et... à Google !
 Par Anthony Techer
Par Anthony Techer
Longtemps, on a pensé que l’optimisation sémantique pour le référencement naturel se limitait à l’écriture des balises title, et Hn. Depuis l’avènement de Google Panda, visant à sanctionner les sites de faible qualité, le contenu est devenu l’une des préoccupations majeures des SEO. Désormais, le moteur de recherche prend en considération la richesse sémantique intrinsèque liée au mot-clé cible. D'où notre envie de développer un outil allant dans ce sens pour aider les réacteurs web à proposer de textes de meilleure qualité qu'auparavant.
Cette aventure démarre donc en 2016. Le monde du référencement a évolué ces dernières années, notamment sur l’optimisation « on-site ». Sans une analyse des champs lexicaux, les contenus se positionnent plus difficilement. Au sein de notre agence, nous l’avons constaté très tôt et une question de rentabilité s’est vite posée : comment produire des contenus de qualité et surtout efficaces d’un point de vue SEO ? Comment le moteur de recherche perçoit-il ce contenu ? Que souhaite-t-il réellement ?
Un outil pour mieux se positionner
De ces questionnements, nous avons fait naitre un outil : SEOQuantum. Il s’agit d’un outil d’aide décisionnelle à la rédaction de contenu. Mais comment fonctionne-t-il ?
Afin d’être le plus pertinent possible, le moteur de recherche considère la qualité perçue par les internautes lors des visites des sites web, notamment à travers le pogosticking. Mais cela est une autre histoire… Le souhait de Google est avant tout de mettre en avant des contenus de qualité, afin de répondre à l’attente de l’internaute. De ce constat, nous avons décidé d’étudier ce qui plait à Google et d’analyser les pages que l’on trouve dans le TOP des SERP afin d’en extraire les principaux champs lexicaux.
Les résultats fournit par les SERP sont en effet une mine d’informations à exploiter. Dès lors, nous avons développé un crawler capable d’extraire le contenu textuel des pages des sites web. Ce n’est pas une mince affaire et nous avons à cette occasion compris les difficultés rencontrées par le moteur lorsqu’il consulte un site afin de l’analyser (mauvais encodage, balises HTML invalides, spam, etc.).
Comment améliorer le positionnement sur mon mot-clé ?
Nous avons inventé un concept sémantique appelé le WordPrint. Les Wordprints sont des notions sémantiques SEO propres à chacun de vos mots-clés : c'est "l'ADN" unique de votre mot clé. Il correspond aux "attentes" de Google en termes de champs lexicaux.
Prenons l’exemple d’un site souhaitant optimiser son contenu sur le mot-clé « comparateur d’assurance ».
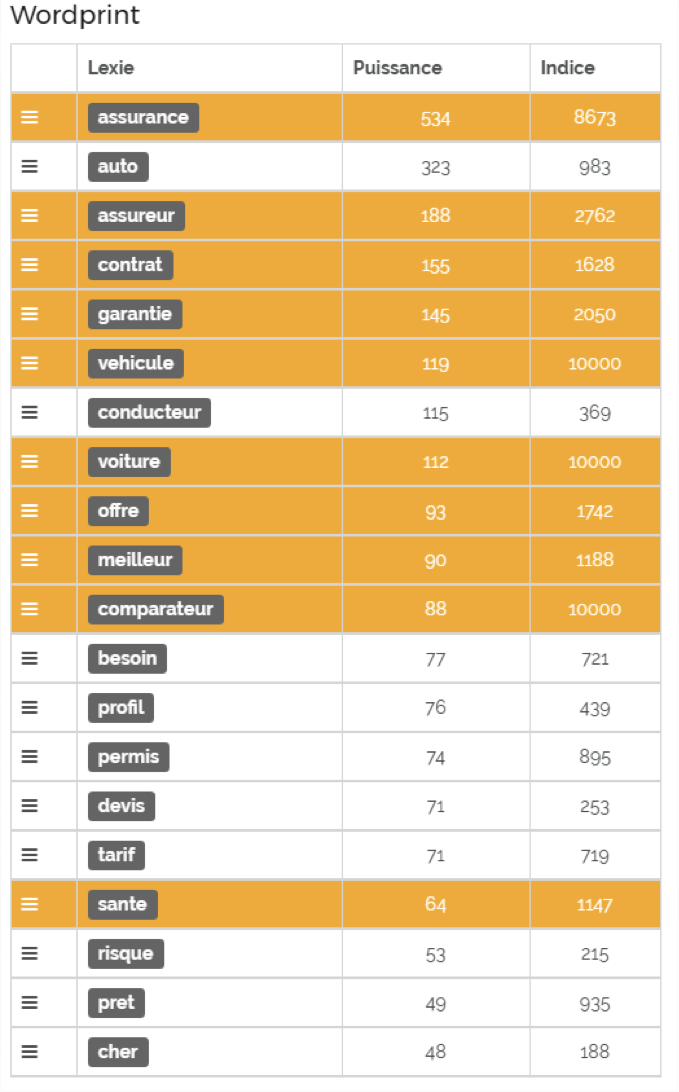
Fig. 1. Wordprint pour "comparateur assurance".
Le WordPrint consiste en une liste de termes identifiés pour la requête « comparateur assurance », avec les deux colonnes suivantes :
- Puissance : nombre de fois où la lexie (le terme) a été trouvée dans notre analyse, il s’agit de la fréquence (aspect quantitatif).
- Indice : L'indice est basé sur BM25, une version évoluée du TF*IDF. Les lexies incontournables sont signalées en surbrillance (fond orange). Ces lexies ont été identifiées comme omniprésentes dans l'analyse.
L'idée est alors de demander aux rédacteurs d’utiliser les lexies proposées dans le tableau dans leur rédaction de contenu. Les lexies surlignées en orange sont très importantes (voire indispensables). Elles apparaissent sur la plupart des résultats (même à faible fréquence).
L'inconvénient est qu'avec cette technique, on peut très vite se retrouver à suroptimiser les pages avec un ensemble de mots. Nous avons donc dû faire évoluer notre analyse pour enrichir nos contenus sans suroptimisation.
L’approche par le Word embedding
Le choix d’une bonne méthode d’analyse des mots est souvent indispensable pour mener à bien des tâches d’optimisation de contenu. La représentation par fréquence des mots est la plus couramment utilisée (voir WordPrint). Cependant, cette représentation a pour défaut de ne capturer que peu d’informations sur le contexte du mot et leur relation entre eux.
Depuis la fin des années 2000, les techniques s’appuyant sur des réseaux de neurones artificiels se sont imposées (deep learning). Il s’agit notamment du Word embedding (voir l'article à ce sujet dans la lettre Réacteur d'avril 2016).
Au sein d’un corpus, un mot n’est en effet pas utilisé de n’importe quelle manière, il est contextualisé, donc en relation avec les autres mots. Cette approche permet de représenter un mot par un vecteur en fonction de sa position dans le corpus. Les méthodes de Word Embedding construisent, pour chaque mot, une fenêtre de contexte. Nous utilisons des vecteurs de contexte afin de représenter chaque mot à travers une matrice. C’est une notion importante chez Google, notamment depuis l’arrivée de RankBrain.
Tout d’abord, identifier l’intention de l’internaute
Une question essentielle à se poser avant de rédiger un contenu est d’identifier l’intention de l’internaute cachée derrière le mot clé. Plus vous serez en adéquation avec l’intention, plus vous vous positionnerez facilement (n’oubliez pas que Google souhaite répondre aux besoins de l’internaute).
Ce qui est fascinant avec le deep learning, c'est que l'on peut "percevoir" l'intention derrière le mot. C’est une méthode très utile pour donner un "sens" aux rédacteurs. Grâce au Deep Learning, les outils comme SEOQuantum permettent de comprendre et de normaliser ce que désire l'utilisateur.
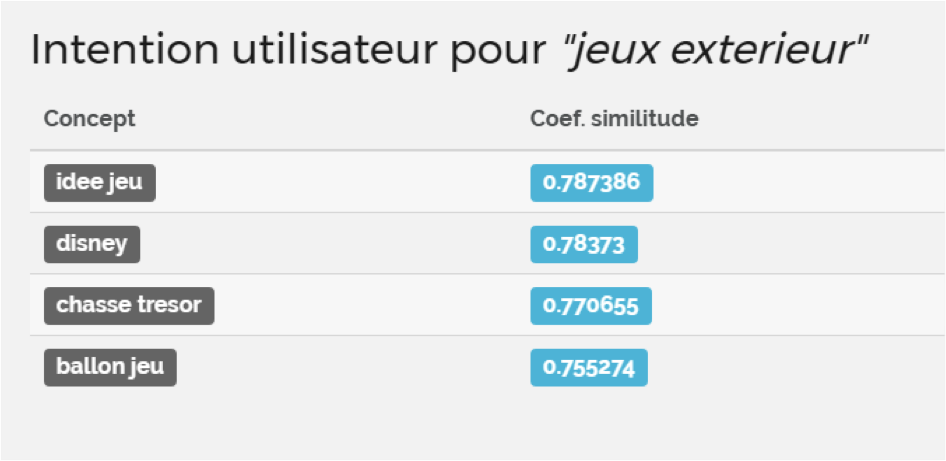
Fig. 2. Ici, pour « jeux d’extérieur » l’internaute souhaite trouver des idées de jeux
(chasse aux trésors, jeux de ballons,…) et non pas des structures de jeux d’extérieurs (tobbogan, balançoire…).
Le coefficient de similitude (de 0 à 1) représente le rapprochement entre la requête et l’intention de l’utilisateur.
Et les contextes dans tout ça ?
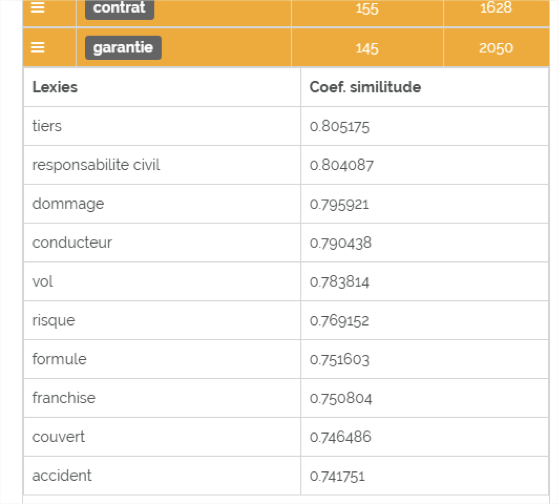
Fig. 3. Affiliation d'une lexie.
Pour connaitre l’affiliation d’une lexie (son contexte), il suffit de cliquer sur les 3 barres horizontales à gauche de la lexie.
Google sait qu'il existe une « fenêtre logique » d'utilisation des lexies dans un corpus. Reprenons notre exemple sur l’analyse de « comparateur d’assurance », pour le mot "garantie" (voir figure 3). Dans le contexte, Google prédit alors une forte probabilité de trouver "tiers", "responsabilité civile", "dommage". Si ces termes ne sont pas utilisés de la sorte, la note sémantique de la page baisse.
Aller encore plus loin avec le deep learning sémantique
Google est un monstre assoiffé de données. Nous nous sommes très vite demandé comment utiliser le « deep learning sémantique » pour être toujours plus pertinent. Début 2017, une idée folle nait dans nos esprits : la clusterisation des champs lexicaux par l’intention de l’utilisateur. Cette méthode est très proche du concept du cocon sémantique qui cherche à répondre à l’attente de l’internaute par la création de contenu.
Il s’agit encore d’une version bêta, mais en voici l’approche :
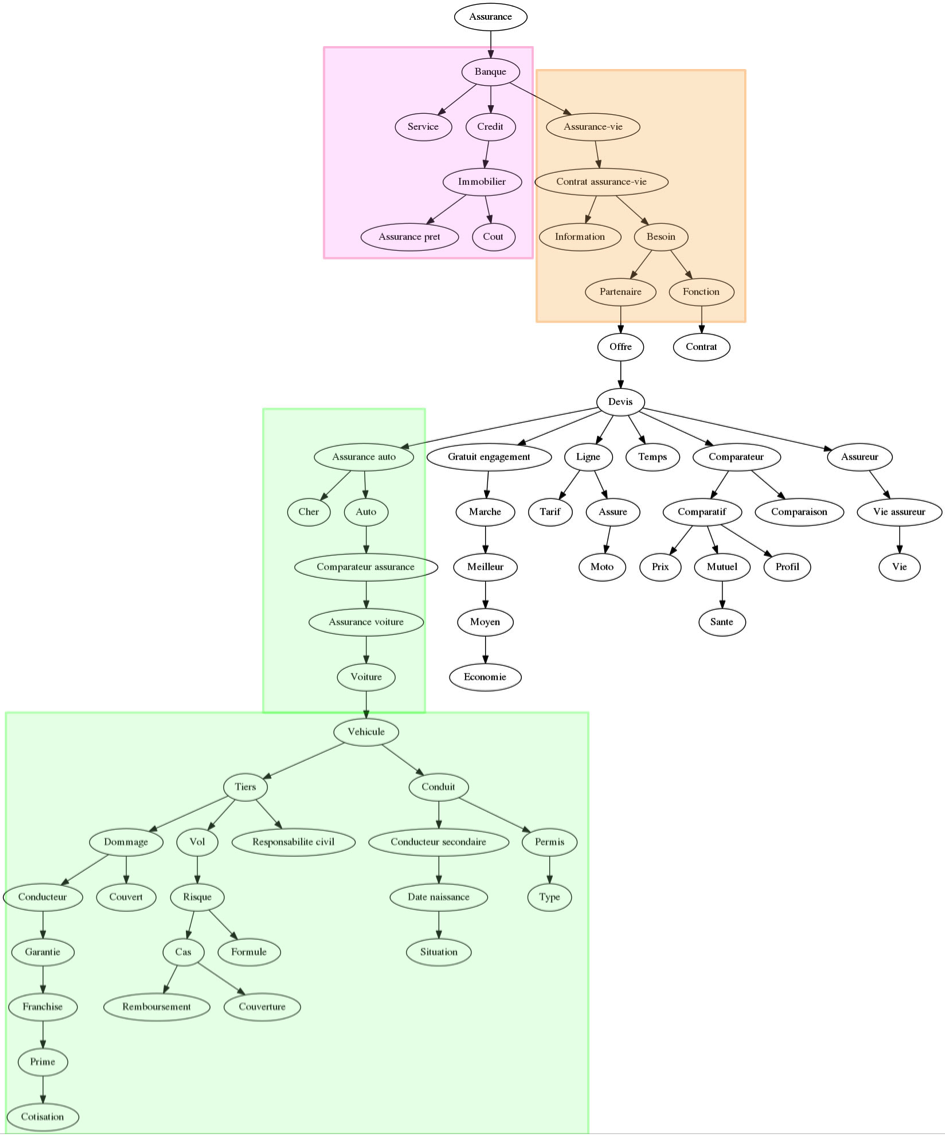
Fig. 4. Arbre des similitudes.
Cet arbre a deux fonctions. La première est une aide rédactionnelle décisionnelle, qui permet de lier une lexie à son environnement. Par exemple, dans quel cas dois-je utiliser le terme « responsabilité civile » ? Ici, le mot est lié à « tiers », lui-même lié à « véhicule ». Il s’agit donc plutôt d’assurance de véhicule.
La seconde fonction de l’arbre est le regroupement des intentions utilisateurs. Nous pouvons regrouper les différentes branches par intention : en rose à assurance prêt ; en orange à assurance vie ; en vert à assurance véhicule.
Lorsque vous avez une page optimisée pour un certain mot-clé et que la compétition sur celui-ci est très importante, il est recommandé d’utiliser des pages à contenus proches afin de « pousser » et soutenir la page principale (il s’agit de l’un des principes du cocon sémantique).
Pour ce faire, SEOQuantum peut réunir les champs lexicaux par grandes attentes des utilisateurs. Les clusters sont alors représentés sous forme de tableaux regroupant les lexies à utiliser. Si la requête est très concurrentielle, nous créons une page par cluster, si elle l’est moins, nous créons un paragraphe par cluster.
Reprenons notre cas de « comparateur d’assurance », nous déployons :

Fig. 5. Différents clusters envisagés.
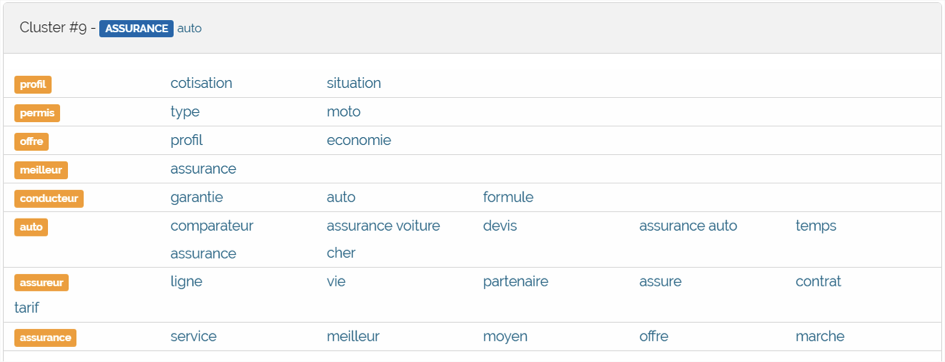
Fig. 6. Une page « assurance véhicule », ici le cluster n°9.
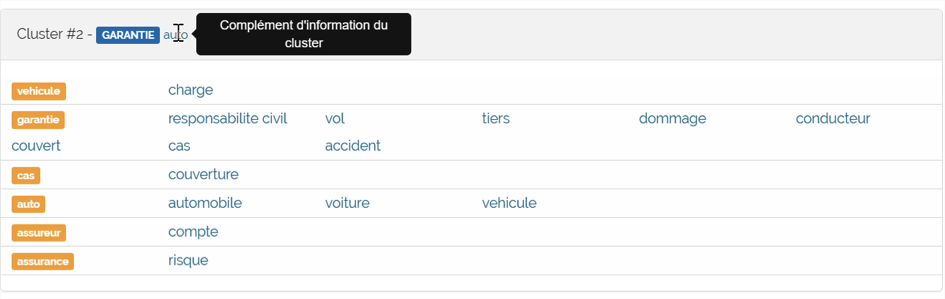
Fig. 7. Une page sur les « garanties des assurances ».
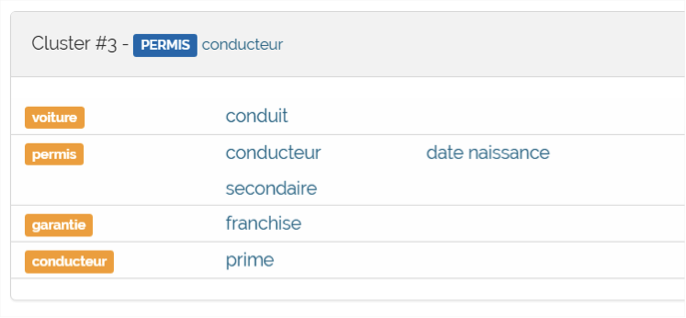
Fig. 8. Et enfin une page sur « les conducteurs ».
NOTE : le nommage des clusters est encore actuellement en version bêta, celui-ci peut ne pas être pertinent, il faut toujours se fier aux champs lexicaux regroupés au sein du cluster.
Et le maillage interne dans tout ça ?
En suivant le principe du cocon : chaque nouvelle page a un lien contextualisé vers la page principale et des liens entre elles. Pour ce faire, nous utilisons le « graph 3D Clustering » qui est une représentation spatiale des clusters. Il suffit de regarder quels clusters se croisent ou sont très proches pour déterminer les ancres de liens.
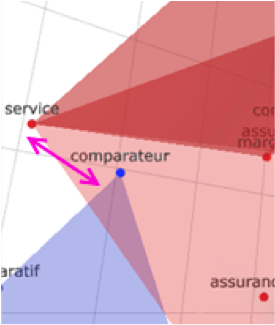
Fig.9. En bleu le cluster « comparateur », en rouge le cluster n°9 « assurance auto », le glissement se fait sur les termes « service » et « comparateur ».
Bonus : test de vos contenus
Fin mars 2017, nous avons sorti une nouvelle fonctionnalité qui permet de tester les textes directement dans SEOQuantum. L’outil attribue un score sémantique à chacune des phrases. Ce score correspond à la probabilité de retrouver la phrase de l’analyse.
Reprenons l’exemple du « comparateur d’assurance » :
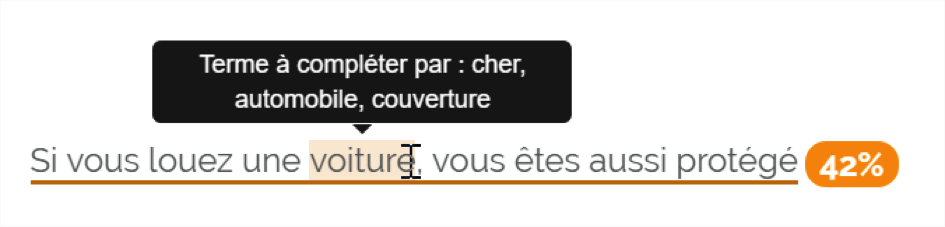
Fig. 10. Phrase non optimisée.
La phrase de la figure 10 a une probabilité de 42% de se trouver dans le modèle d’analyse. Grâce à la fenêtre de contexte, l’outil suggère l’utilisation des termes « automobile », ou « couverture » pour enrichir la sémantique de la phrase. Cela signifie que « voiture » est lié aux lexies « automobile » et « couverture ». Nous remplaçons donc « protégé » par « couvert » comme l’indique l’outil.

Fig. 11. Phrase optimisée.
Les deux lexies concordent, la note sémantique de la phrase augmente. Il en est de même avec la suroptimisation de vos contenus. L’outil souligne les phrases en rouge lorsque trop de mots sont employés au sein d’une même phrase.

Fig. 12. Phrase sur-optimisée.
Conclusion
Le monde du SEO est en perpétuelle évolution. L'émergence du « deep learning » et du word embedding auront d’importantes conséquences dans notre travail de référenceur. Cependant, cela ne sonne pas le glas du référencement naturel. Nous devons nous adapter, adapter notre méthodologie et outils. SEOQuantum est un outil gratuit en version bêta, qui a cette vision d'avenir et qui ne demande qu’à grandir, n'hésitez pas à tester et à nous faire des retours.
![]() Anthony Techer, concepteur de l'outil SEOQuantum (http://www.seoquantum.com/) et co-créateur de l'agence Allorank (http://www.allorank.fr/)
Anthony Techer, concepteur de l'outil SEOQuantum (http://www.seoquantum.com/) et co-créateur de l'agence Allorank (http://www.allorank.fr/)

 de nous rejoindre
de nous rejoindre