

Le googler Gary Illyes a indiqué il y a quelques semaines dans une interview que Google 'labellisait' les liens qu'il identifiait sur le Web, en fonction de leur emplacement, de leur caractère éventuellement spammy, etc. Ceci n'est pas une surprise totale, même si cette mention était pour la première fois faite de façon ofifcielle. Comment et pourquoi Google donne-t-il des labels aux liens ainsi découverts et à quoi cela peut-il lui servir ? Et qu'est-ce que cela change dans nos habitudes de SEO ?...
 Par Philippe Yonnet
Par Philippe YonnetLors d'une interview menée par Barry Schwartz, diffusée le 14 octobre dernier sur Marketing Land, le googler Gary Illyes a révélé plusieurs informations à propos de Penguin. Il a notamment révélé que les informations de ce filtre Penguin (qui est maintenant intégré dans le coeur de l'algorithme) font partie d'un ensemble d'étiquettes associées aux liens.
Cela fait quelques années que l'on soupçonne Google d'"annoter" les backlinks. Ces soupçons proviennent de rares informations qui ont "fuité" de la part de certains employés de Google concernant leur interface de travail. Mais aussi parce que de nombreux brevets déposés par Google portaient sur des systèmes d'étiquetages de liens à des fins diverses : lutte contre le spam, mesure de la topicalité, qualité ou popularité.
Mais que sait-on exactement sur ce système d'étiquettes ? A quoi sert-il ? Et qu'est-ce que cela peut changer aux techniques d'optimisation et de netlinking ?

Fig. 1. Gary Illyes est Webmaster Trends Analyst chez Google,
et l'un des principaux porte-parole de la firme de Mountain View vers les éditeurs de site.
A l'origine, Google exploitait une information basique sur les liens
Dans l'article d'origine (daté de 1998) décrivant le moteur de recherche Google, Page et Brin ont décrit le système de stockage des informations sur les liens hypertextes. Les deux seules informations conservées étaient :
- Les "couples (DocId1,DocId2)" : c'est-à-dire l'information sur l'existence d'un lien hypertexte depuis la page 1 vers la page 2. Comme les liens hypertextes constituent ce qu'on appelle un "graphe orienté", cette notion correspond à la notion d'arc, c'est-à-dire une arête dotée d'une orientation (de Doc1 vers Doc2 ou de Doc2 vers Doc1).
- Les "textes d'ancres" : indexés avec le contenu des pages de destination.
L'information sur le graphe des liens était ensuite utilisée pour calculer le Pagerank d'une URL.
Link label : un "faux ami"
Remarquons au passage que les anglo-saxons utilisent souvent le terme "link label" (étiquette de liens) pour désigner un "texte d'ancre", ce qui peut créer de la confusion quand on lit des articles sur le traitement des liens hypertextes.
Dans la suite de cet article, lorsque nous parlerons de "label" ou d'étiquette, il ne s'agira pas des textes d'ancre, mais bien d'une logique d'association entre un lien et un attribut.
Le Pagerank, et le surfeur aléatoire
Comme tous les moteurs de recherche généralistes, Google fait une utilisation intensive de l'information extraite des liens hypertexte dans son algorithme de classement. C'est notamment le cas de la note de popularité tirée de l'analyse du graphe des liens qui a fait son succès initial : le Pagerank.
Au départ, le Pagerank était présenté comme la mesure des "votes" des webmasters, exprimés sous forme de liens, au profit des pages de destination de ces liens : le fait de placer un lien sur une page de son site étant considéré comme une "recommandation" du webmaster.
Dans la pratique, cette notion de "vote" s'est vite révélée être déconnectée de la réalité. Un grand nombre de liens sont créés par des programmes plutôt que par des humains. Et les liens sont créés pour de multiples raisons, le plus souvent éloignées de cette notion désintéressée de "vote" : le motif commercial étant relativement fréquent. Néanmoins, dans les premières années de fonctionnement du moteur, la forme originelle du Pagerank s'est révélée particulièrement efficace pour améliorer la pertinence du moteur.
En fait, lorsque les chercheurs dans le domaine de l'"information retrieval" ont cherché à donner des bases théoriques au Pagerank, ils se sont rendu compte que cette "note" mesurait en fait plutôt autre chose. Le Pagerank d'une URL mesure en effet la probabilité pour qu'un internaute qui surfe sur le Web en cliquant sur des liens au hasard finisse par cliquer sur l'URL. C'est ce qu'on a appelé le modèle du "surfeur aléatoire" (le "random surfer").
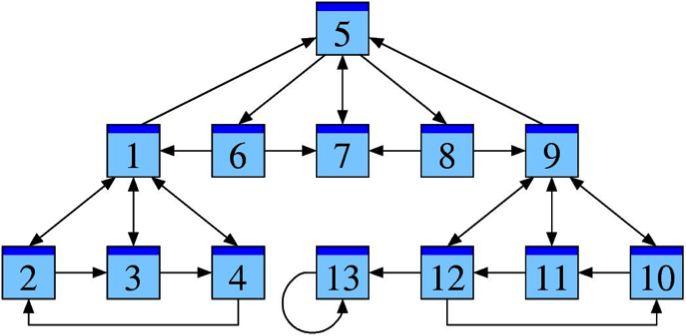
Fig. 2. Un exemple de parcours possible d'un « surfeur aléatoire » sur le web : dans tous les cas, le parcours s'arrête sur la page numéro 13. Dans le modèle utilisé par Page et Brin pour leur Pagerank, dans un tel cas, le surfeur aléatoire peut être téléporté de temps en temps dans une autre zone du Web pour continuer son exploration.
Le "surfeur aléatoire" : un modèle incomplet
Le modèle du "surfeur aléatoire" a été très vite critiqué par les chercheurs en recherche d'information pour trois raisons principales. Tout d'abord, ce modèle ne correspond pas à un comportement "réel" de l'internaute. Les "surfeurs" ne cliquent pas au hasard sur les pages : ils choisissent les liens sur lesquels ils cliquent. Par conséquent, la note est "biaisée", un site à fort Pagerank peut ne pas être réellement important, et la réciproque est vraie également.
Ensuite, le modèle est facilement manipulable. Il suffit de créer des liens depuis des pages contrôlées par le webmaster (parce qu'on les a hackées, ou créées artificiellement, ou parce qu'on arrive à convaincre les propriétaires de ces pages de faire un lien vers son site, en les rémunérant) pour augmenter cette note de popularité.
Enfin, le modèle ne tient pas compte de l'âge des liens ! Un site qui fût important sur le Net, mais ne l'est plus, conserve son Pagerank. Ce qui au fil des années qui passaient a rendu obligatoire une approche différente.
Du surfeur aléatoire au "surfeur intelligent" ou "raisonnable"
Google (et d'autres équipes qui géraient des moteurs comme Yahoo! Ou Microsoft) s'est vite rendu compte qu'il fallait améliorer l'algorithme, en collant au plus près à la réalité. Et notamment tenir compte du fait que tous les liens ne se valent pas.
De nombreux spécialistes ont donc proposé des modèles alternatifs plus solides car moins sensibles au spam. On les retrouve dans la littérature sur l'Information Retrieval sous des noms comme "Surfeur Intelligent" (Intelligent Surfer), "Surfeur Prudent" (Cautious Surfer, un modèle axé sur la notion de transmission d'une note de confiance "trust") ou "Surfeur Raisonnable" (Reasonable Surfer). Cette dernière appellation est celle qui est la plus fréquemment utilisée dans les papiers des chercheurs de Google.
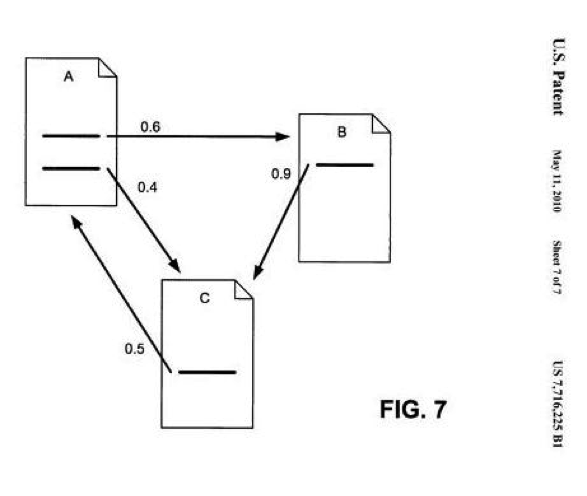
Fig. 3. Un schéma issu d'un brevet de Google protégeant une méthode d'analyse des liens compatible avec le modèle du « reasonable surfer ».
Des modèles qui s'appuient sur l'annotation des liens
Le principe d'annoter les liens en les associant à des étiquettes apparait dans plusieurs brevets de Google qui font allusion au modèle du "Reasonable Surfer".
Les méthodes décrites dans les brevets partent toutes du même principe : pour décider de la valeur d'un lien, et quelle valeur de signal il doit transmettre (Pagerank, trust, topicalité, spam etc…), il faut tenir compte de plusieurs critères à la fois. C'est l'analyse de ces multiples facteurs qui permet de prendre une décision, ou d'évaluer le niveau de signal transmis.
Et pour stocker l'information, l'idée est d'associer aux liens hypertextes découverts lors de la phase d'exploration des informations supplémentaires sous formes d'étiquettes (des "labels" ou des "tags"). Ces étiquettes sont ajoutées au fur et à mesure que certaines données sont analysées (parsées) ou collectées.
Remarquons que souvent les approches conduisent à annoter non seulement les liens, mais également les documents et/ou leur contenu, selon des logiques similaires.
Quelles informations pourrait-on stocker dans les attributs ?
L'analyse des différents brevetsobtenus par Google permet de découvrir toute une série d'attributs jugés intéressants à stocker sous formes d'étiquettes ou de couples attributs-valeur pour aller vers le modèle du "surfeur raisonnable". Est-ce qu'ils sont tous réellement exploités sous cette forme ? Pas forcément.
Il faut rappeler ici que si une méthode est décrite dans un brevet déposé par Google, cela ne signifie pas que cette approche est réellement utilisée dans le moteur. Mais les exemples qui suivent donnent probablement une bonne idée de ce que Google cherche vraiment à faire avec son système d'étiquettes. Voici un résumé des principaux critères évoqués dans ces brevets, dont on trouvera les plus intéressants en référence à la fin de cet article :
- La temporalité : la date de première découverte du lien par exemple ;
- L'emplacement du lien : le lien a t-il été découvert dans le header ? le footer ? au sein de la zone où figure le contenu de la page ? Dans la colonne de droite ? Dans la zone des menus ? ;
- La visibilité du lien : quelle police est utilisée ? quelles couleurs ? quelle taille de caractère ? ;
- La position du lien dans une liste ;
- Le voisinage du lien : le lien est il entouré d'autres liens considérés comme spammy ? Ou non ? ;
- Le type de lien hypertexte : lien classique ? lien hypertexte trouvé dans un pdf ? Du code flash ? Du code javascript ? Un lien généré en Javascript ? Un lien trouvé sur une image, une iframe ? ;
- Les attributs du lien lui même : en particulier la présence du nofollow ;
- La page de destination : le lien pointe-t-il vers une page de destination bloquée par un robots.txt ? ;
- Les redirections : est-on redirigé si on clique sur le lien ? et y a-t-il des redirections mutiples ? ;
- Le contexte du lien ("topicalité") : le sujet de la page de départ, ou le thème du site, est-il en rapport avec le sujet de la page de destination ou le thème du site de destination ? ;
- La répétition du lien : le lien est-il présent de multiples fois sur les pages d'un même site ? Le même lien, avec la même ancre est-il présent de nombreuses fois sur différents domaines ?
- Les caractéristiques du texte d'ancre : absence d'ancre ? ancre riche ? ancre "exacte" ? ancre probablement peu cliquée ? ;
- Le "trust : le lien émane-t-il d'une page/d'un site "de confiance" ? ;
- L'indépendance de la source du lien : la page sur laquelle on trouve le lien appartient-elle à un site indépendant, ou contrôlé par l'éditeur du site de la page de destination ? Le lien se trouve-t-il dans un espace communautaire : commentaire de blogs, forum etc. ?
Et bien sûr:
- L'identification du webspam et du linkspam : le lien provient-il d'une page identifiée comme "spammy" ? Le lien pointe-t-il vers une page identifiée comme spammy ?
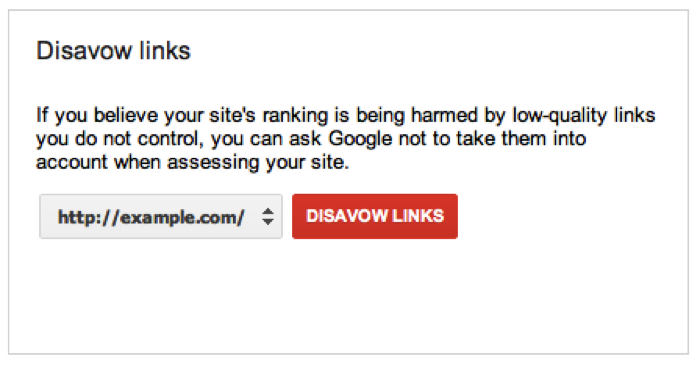
Fig. 4. La présence du lien dans un fichier de désaveu est l'une des sources d'information
utilisable pour « étiqueter » un lien.
Tous ces attributs sont-ils exploités sous forme d'"étiquettes" par Google ? Certains oui, d'autres non. Jusqu'à une époque récente, l'existence de ce système de "tags" ou d'étiquettes n'était pas confirmé, et nous avons peu d'informations officielles, à part les informations communiquées par Gary Illyes.
Les étiquettes évoquées par Gary Illyes
Les informations données par Gary Illyes sont donc une première confirmation de l'existence d'un système de labels attachés aux liens. Voici les attributs qu'il a mentionnés (il en existe sans doute beaucoup d'autres réellement utilisés), et dont l'utilisation est confirmée :
- Footer link : lien placé dans un pied de page ;
- Penguin Links : lien flaggé dans la logique de l'ancien filtre Penguin ;
- Disavowed Links : lien mentionné dans un fichier de désaveu.
Quel est l'impact de cette information pour le SEO ?
L'existence de ce système d'étiquettes autour des liens (mais rappelons qu'un système similaire existe probablement aussi pour les documents), ne constitue pas du tout une révolution qui appelle des changements dans les bonnes pratiques de netlinking. C'est par contre la confirmation que Google a commencé depuis des années à sophistiquer son approche concernant la prise en compte des liens dans son algorithme. Et ce système en est l'une des expressions connues.
Tous les liens ne se valent pas, et Google cherche à accumuler de l'information sur les liens permettant de mieux arbitrer lesquels doivent être pris en compte dans l'algorithme et, pour ceux pris en compte, quelle part des "notes" transmises par les liens doivent être transmises à la page de destination.
Certaines de ces "étiquettes" permettent donc d'annuler la valeur des liens envoyés vers votre site depuis des pages "spammy", qu'elles aient été identifiées par le filtre Penguin ou par d'autres méthodes. D'autres servent à pondérer plus exactement le trust, la popularité, la topicalité etc. des documents, grâce à des algorithmes reprenant le modèle du "surfeur raisonnable".
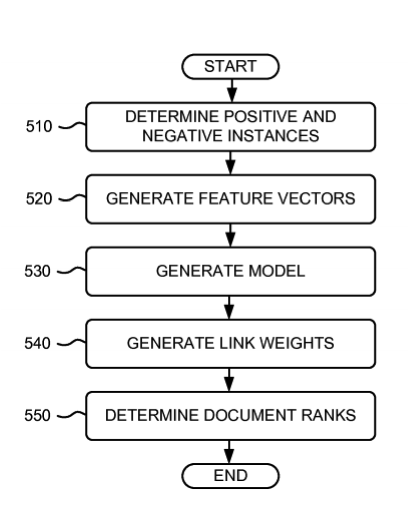
Fig. 5. Un schéma issu d'un brevet décrivant une méthode d'analyse des liens suivant le modèle du surfeur raisonnable : le système génère des poids pour les liens qui prennent en compte de multiple facteurs qui prédisent soit la probabilité qu'un lien soit cliqué, soit qu'il soit manipulé.
Cela signifie également que quelqu'un de l'équipe qualité de recherche chez Google peut consulter facilement ces étiquettes pour se faire une idée du caractère "sain" ou "non naturel" (factice) du profil des backlinks d'un site. Et décider derrière d'une éventuelle pénalité infligée au site pour liens non naturels (sortants ou entrants).
Mais maintenant que vous connaissez les critères connus, ou probables, derrière ce système d'étiquetage des liens, rien n'interdit évidemment de vous demander quelles étiquettes vous ajouteriez vous même aux liens figurant dans le profil de backlinks de votre site. Ce qui constitue une approche qui en vaut bien d'autres dans la préparation d'un fichier de désaveu couvrant tous les liens à problème, mais uniquement les liens à problème...
Et maintenant vous êtes avertis : les liens inclus dans vos fichiers de désaveu sont affublés de l'étiquette "lien désavoué"... Et cette information est réutilisée dans les outils d'analyse des liens de Google.
Mais ça, on s'en doutait déjà…
Bibliographie et liens utiles
Le podcast sur Marketingland avec Gary Illyes et la transcription.
Le post de Matt Cutts présentant le filtre Penguin en 2012 sur le blog de Google pour les webmasters.
Un article décrivant le concept du "surfeur prudent", qui s'appuie sur la notion de trustrank.
Les brevets :
L'une des dernières versions des brevets à propos du reasonable surfer :
Ranking documents based on user behavior and/or feature data
Invented by Jeffrey A. Dean, Corin Anderson and Alexis Battle
Assigned to Google Inc.
United States Patent 7,716,225
Granted May 11, 2010
Filed: June 17, 2004
Et un brevet complémentaire, plus récent (avec de nouveaux critères évoqués)
Ranking documents based on user behavior and/or feature data
Inventors: Jeffrey A. Dean, Corin Anderson, and Alexis Battle
Assigned to: Google
US Patent 9,305,099
Granted April 5, 2016
Filed: January 10, 2012
Determining quality of linked documents
Inventors: Bharat; Krishna (San Jose, CA), Singhal; Amit (Palo Alto, CA), Haahr; Paul (San Francisco, CA)
Assignee: Google Inc. (Mountain View, CA)
Family ID: 42583427
Appl. No.: 10/879,520
Filed: June 30, 2004
Ranking nodes in a linked database based on node independence
Invented by Paul Haahr, Martin Kaszkiel, Amit Singhal
Assigned to Google Inc.
US Patent 8,719,276
Granted May 6, 2014
Filed January 4, 2011
Content entity management
Invented by Mayur Datar and Ashutosh Garg, Assigned to Google
US Patent 8,176,055
Granted May 8, 2012
Filed: March 27, 2007
![]() Phlippe Yonnet
Phlippe Yonnet
Directeur Général de l'agence Search-Foresight, groupe My Media (http://www.search-foresight.com)