

Au travers d'une (longue) suite de 7 articles sur la refonte de site web dans les précédents numéros de cette lettre, nous avons passé en revue la méthodologie à appliquer pour que la mise en place d'un nouveau site web ait un impact positif sur le SEO. Nous allons voir dans cet article final les étapes à ne pas négliger en prévision de la mise en production d'un nouveau site, afin d'éviter un effet négatif sur le trafic organique, ainsi que le suivi de différents KPI post-migration pour les corrections d'éventuelles erreurs.
Phase de recette finale
La phase de recette est la période pendant laquelle toutes les vérifications relatives aux recommandations SEO qui ont été fournies aux intégrateurs et développeurs seront vérifiées. Bien que le code HTML de chacune des pages par type de template ait été vérifié au préalable (balisage sémantique, microdonnées, convivialité des pages, organisation du contenu, liens, menu, etc.), la mise en place d'un crawl permettra de s'assurer de la cohérence de plusieurs éléments.
Développement et restrictions sur le serveur
Le site de test doit être non crawlable par les moteurs et inaccessible au public de préférence, et ce dès sa mise en place en début de projet. Pour cela, il est recommandé de mettre en ligne un fichier robots.txt contenant les directives suivantes afin d'éviter tout problème de duplication de contenu dans l'index des différents moteurs de recherche :
User-agent :*
Disallow: /
Il n'est malheureusement pas rare de voir des sites dédiés aux tests et développements qui se retrouvent indexées comme le montre cette page de résultats : https://www.google.fr/search?q=site%3Apreprod.*.* (plus de 350 000 résultats !).
En complément de la mise en place de cette restriction de crawl, une authentification via une combinaison login / pass sera plus sûre pour éviter tout effet de bord, lors de la suppression du fichier robots.txt par erreur par exemple…
Voici la méthodologie à utiliser pour obtenir un système d'authentification sur différents serveurs, pour restreindre l'accès au public mais surtout afin d'éviter des problèmes d'indexation intempestifs.
Apache et authentification :
Afin de limiter l'accès au site en construction, il vous faudra générer un fichier .htpasswd contenant les différentes clés utilisateur / mot de passe via l'outil « apache2-utils », qu'il faudra avoir préalablement installé via la console sous les systèmes Unix/Linux :
#apt-get install apache2-utils
Vous pourrez ensuite lancer l'outil permettant de générer le fichier .htpasswd (à placer dans le répertoire sur le serveur) via la commande suivante :
sudo htpasswd -c /var/www/monsite/.htpasswd nomutilisateur
Il vous sera alors demandé de saisir le mot de passe souhaité afin de générer le fichier contenant les accès (vous pourrez relancer cette commande pour ajouter plusieurs utilisateurs). La vérification du contenu de votre fichier pourra se faire au travers de la commande :
#cat /var/www/monsite/.htpasswd
Il vous faudra ensuite activer l'authentification pour ces utilisateurs, en ajoutant les lignes suivantes dans votre fichier .htaccess (ou la configuration de votre serveur, directives <Directory> en vert à ajouter dans ce cas) :
<Directory /var/www/monsite/>
AuthType Basic
AuthName "Restricted Content"
AuthUserFile /var/www/monsite/.htpasswd
Require valid-user
</Directory>
Une boite de dialogue s'ouvrira par la suite, vous demandant de vous identifier, afin d'effectuer la recette du futur site, tout en évitant que le futur site soit accessible au public et indexable par les moteurs.
Nginx et authentification :
La création du fichier .htpasswd peut être effectuée comme pour les serveurs Apache. Afin d'activer le fichier, il sera nécessaire de modifier la configuration de Nginx (ex : /etc/nginx/sites-enabled/default), en adaptant le chemin vers le fichier .htpasswd généré préalablement.
server {
listen 80 default_server;
listen [::]:80 default_server ipv6only=on;
server_name www.monsite.com;
location / {
auth_basic "Restricted Content";
auth_basic_user_file /etc/nginx/.htpasswd;
}
}
IIS et authentification :
La procédure demande d'accéder à la configuration du serveur via les différents menus de IIS, vous trouverez la documentation nécessaire sur cette page de documentation de Microsoft : https://docs.microsoft.com/en-us/iis/configuration/system.webserver/security/authentication/basicauthentication
Crawl de recette
Le crawl du futur site vous permettra de déceler d'éventuelles erreurs d'intégration, pouvant nuire au référencement de votre site. L'outil Screaming Frog SEO Spider étant capable de crawler quelques centaines de milliers d'URL (à condition de lui dédier plusieurs Giga-octets de mémoire vive au préalable via le nouveau menu Configuration > System > Memory) sera suffisant dans la majeure partie des cas.
Afin que cet outil puisse crawler le site de test malgré la restriction du fichier robots.txt décrit précédemment (Disallow: /), il vous faudra modifier sa configuration pour crawler le site avec les restrictions du futur fichier robots.txt (Menu « Configuration > robots.txt > custom ») :
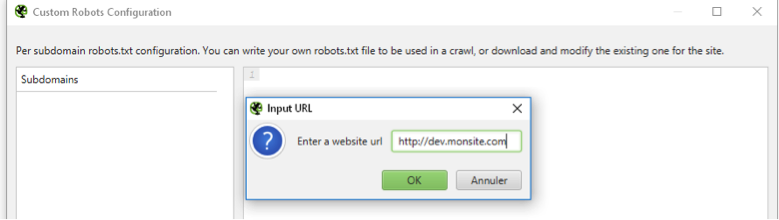
Fig. 1. Création d'un fichier robots.txt spécifique pour autoriser le crawl de façon temporaire.
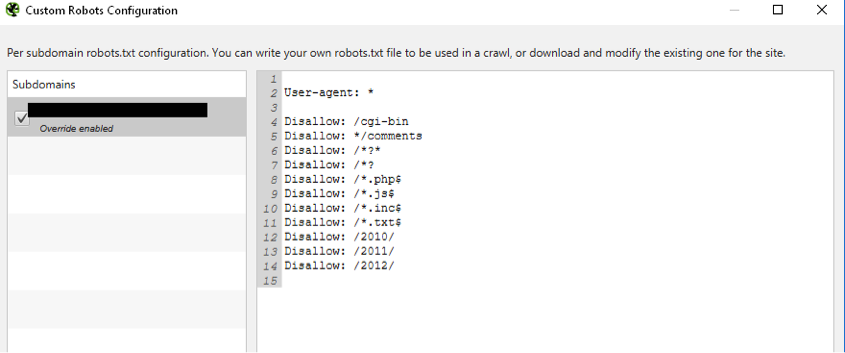
Fig. 2. Ajout des directives du futur fichier robots.txt.
Le crawl pourra alors être lancé. Dans le cas où une authentification aurait été mise en place, Screaming Frog vous ouvrira une boîte de dialogue afin que vous renseigniez votre login/pass.
Par la suite, voici quelques éléments qui pourront être passés en revue pour vous assurer de la validité du site, relatifs aux problématiques typiques à analyser lors de la création d'un nouveau site :
-
- Présence de Spider-trap (boucle de liens pouvant perdre un crawler), en s'assurant que le niveau maximum de la profondeur des pages ne soit pas trop élevé (Colonne « Crawl depth »).
- Liens erronés générant des erreurs 404 visibles via le sous-menu « Client error 4xx » de l'onglet « Response codes ». La fenêtre inférieure vous permettra de trouver l'origine des liens cassés :
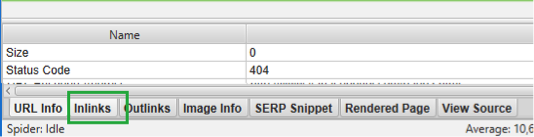
Fig. 3. Liens cassés ou mal formatés provoquant des erreurs 404.
- Pages vides (page de tests publiées) ou pages sans contenu pouvant faire baisser la qualité globale de votre site. Vous pourrez détecter ce type de page en analysant la colonne « Word count » qui vous permettra de détecter les pages contenant trop peu de mots :
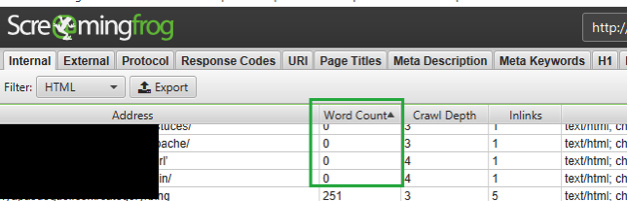
Fig. 4. Pages ne contenant pas ou peu de mots probablement vides de contenu.
- Pages sous-maillées et ne recevant que peu de liens via la colonne « Unique Inlinks » de la fenêtre principale : vérifier la pertinence du maillage interne avant toute mise en ligne.
Bien qu'une projection du maillage interne ait pu vous permettre de définir le placement des différents liens dans les pages ainsi que la structure des menus, il est préférable de vérifier le résultat final pour identifier tout dysfonctionnement.
Le crawl vous permettra également d'identifier des URL parasites détectées par le crawler et non pertinentes pour le SEO qui devront être bloquées via le fichier robots.txt, et masquées du code source pour éviter une dilution du PageRank interne.
Recherches dans les pages
Il est également utile de rechercher des termes spécifiques avant de lancer le crawl pour identifier des éléments relatifs au site de développement qui ne doivent pas se retrouver en ligne :
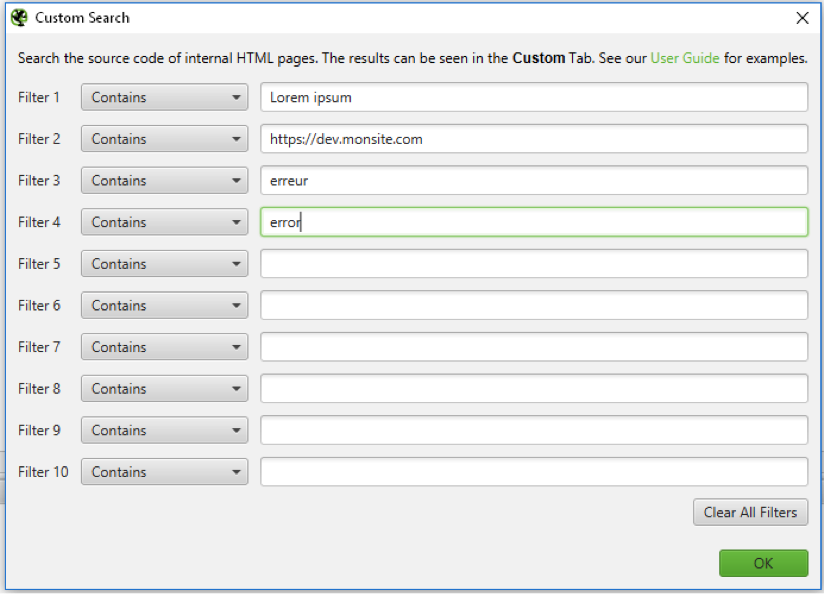
Fig. 5. Recherche de termes spécifiques.
- « Lorem ipsum » pour détecter des textes de test ayant pu être utilisés dans des pages de test.
- https://dev.monsite.com pour détecter des URL du site de test qui auraient été codées en dur dans le code source.
- D'autres termes comme « erreur », « error », ou « undefined » qui remonteraient des problématiques de développement générant des erreurs.
Une fois que le crawl du futur site sera satisfaisant, il sera nécessaire de tester les redirections mises en place lors du plan de migration, pour s'assurer de leur bon fonctionnement.
Test des règles de redirection
Afin de tester le fonctionnement des règles de redirections implémentées, il vous faudra utiliser un crawler comme Screaming Frog ou Xenu permettant de crawler une liste d'URL, sans en suivre les liens. Vous pourrez ainsi vous assurer du bon fonctionnement des redirections 301.
Il est recommandé d'utiliser la liste d'URL qualifiées préalablement (article « Refonte de site web - Le plan de redirection ») qui seront ensuite importées dans l'outil de crawl de votre choix :
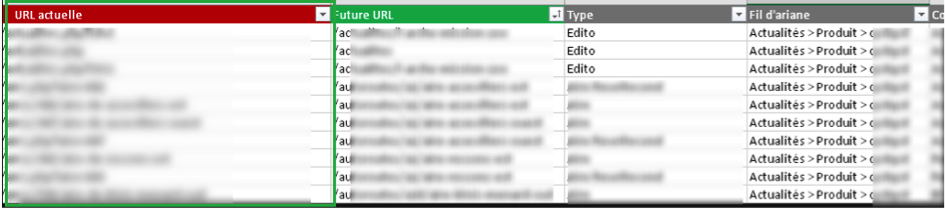
Fig. 6. Test des URL identifiées à rediriger.
Le nom d'hôte de chaque URL devra être modifié avant le test, afin que les URL soient testées sur le serveur de préprod, ex : http://www.monsite.com/url1 --> http://dev.monsite.com/url1.
Lors du crawl, les principales erreurs à identifier seront les suivantes :
- Codes réponse différents de 301 : des erreurs 4xx ou 5xx indiqueront le mauvais fonctionnement de certaines règles de redirection ;
- Chaines de redirections (301 -> 301 -> 200) : ces suites de redirections peuvent être provoquées par des redirections déjà existantes qu'il faudra mettre à jour pour éviter le crawl d'URL intermédiaires ;
- Présence de paramètres d'URL non souhaitées post-redirection. C'est souvent le principal élément pouvant pénaliser une migration SEO, avec l'ajout d'anciens paramètres d'URL sur le nouveau site, provoquant ainsi de la duplication de contenu.
Un focus particulier doit être effectué sur tous les paramètres d'URL, pour détecter les redirections ne traitant pas correctement cette chaîne située après le « ? » dans les URL (cf Refonte de site web – règles de redirections) . Cela peut avoir un effet très négatif lors d'une migration.
En cas de problème sur certaines règles, vous pourrez éventuellement débugger les règles contenant des erreurs directement sur le serveur, ou via un outil en ligne tel que https://htaccess.mwl.be/ pour les fichiers .htaccess (serveurs Apache) .
Une comparaison des URL récupérées post-redirection vs les nouvelles URL souhaitées dans un tableur comme Excel vous permettra ensuite de gagner un temps considérable pour analyser vos résultats.
Mise en production
Quand les règles seront toutes fonctionnelles, le site pourra enfin être mis en production. Cependant, plusieurs éléments importants seront à vérifier lors de la mise en ligne. Voici les principaux points d'attention à prendre en compte :
- Supprimer les balises meta robots en « noindex » qui auraient pu être placées sur l'ensemble du site ;
- Vérifier l'éventuel présence d'en-têtes X-Robots-Tag en noindex, ou d'en-têtes dédiées au site de développement ;
- Remplacer le fichier robots.txt en Disallow de votre site de test par le futur robots.txt, au risque de voir votre trafic chuter rapidement dans le cas contraire (erreur malheureusement encore trop fréquente) ;
- S'assurer de la présence du code de suivi de votre outil d'analyse d'audience dans toutes les pages du site (ex: Google Analytics, GTM) ;
- Supprimer les méthodes d'authentification qui auraient pu être paramétrées (cf. début de l'article) ;
- S'assurer de la validité du certificat SSL en cas de passage au HTTPS : https://www.ssllabs.com/ssltest/.
- Configurer une nouvelle propriété dans la Google Search Console pour un site qui passerait en HTTPS ou qui changerait de nom de domaine.
Enfin, cela peut paraitre évident, mais il est fortement déconseillé de mettre en ligne un nouveau site en fin de semaine comme un vendredi après-midi par exemple (déjà vu)… au risque de passer un mauvais week-end en cas de problème.
Le début de semaine sera plus adapté pour une meilleure réactivité en cas de dysfonctionnement, mais également afin d'avoir un suivi efficace les premiers jours de la migration.
Dans le cas où vous devriez rendre votre site indisponible pendant quelques heures pour sa mise en ligne, il est recommandé de renvoyer un code 503 sur le fichier robots.txt : cela stoppera le crawl de Googlebot de façon temporaire. Tant que ce fichier ne sera pas à nouveau disponible (status http 200), le crawl de Google restera en veille (plus d'infos : http://www.yapasdequoi.com/seo/3461-seo-et-site-en-maintenance-raconte-quoi-googlebot.html).
Suivi et correction d'erreurs
Pour vous assurer de la bonne prise en compte des redirections et de la performance du nouveau site, voici les principaux éléments à surveiller dans les jours qui suivent la migration :
- Evolution des erreurs 404 (analyse de logs, Google Search Console) ;
- Evolution des clics et impressions dans les pages de résultats ;
- Evolution des positions sur un ensemble de mots-clés définis au préalable ;
- Evolution du trafic SEO hors marque (exemple : filtrer les clics dans Google Search Console en supprimant les requêtes contenant le nom de la marque) ;
- Evolution de l'indexation via la commande « site : » dans les pages de résultats ;
- Fréquence de crawl dans les statistiques d'exploration de l'ancienne Search Console ;
- Etc.
Exemple de tableau de suivi :
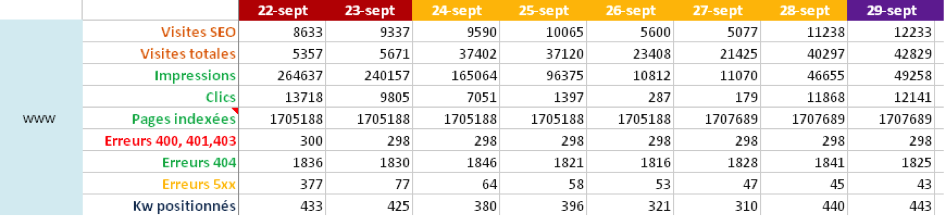
Fig. 7. Suivi des KPI post-migration.
Fréquence de crawl
Le nombre d'éléments crawlés par jour par Google est également un indicateur à prendre en compte. Il est probable que vous constatiez un pic de crawl sur une courte période : quand Google détectera un grand nombre de redirections, il pourra accélérer son crawl pour favoriser la prise en compte des redirections 301 et la fraîcheur de son index. Enfin, il faut garder à l'esprit que pour une URL visitée, cela provoquera 2 hits de Googlebot : la redirection 301, et la page suivante répondant en 200).
Erreurs 404
Une hausse des erreurs 404 est normal : on trouve toujours des URL qui peuvent être passées entre les mailles du filet lors de la phase de création du plan de redirection. Comme les règles ont été créés par ordre de priorité, il est probable que les erreurs concernent des URL ayant peu de poids SEO. Cependant, plus vite les erreurs importantes auront été identifiées, mieux cela sera : une migration ratée est longue à rattraper.
Variations de trafic
Enfin il n'est pas rare de voir des variations de trafic et de positions dans les jours qui suivent une migration. Cela est due entre autres :
- Au délai de prise en compte des redirections 301 ;
- A la duplication temporaire qui peut survenir (nouvelle page découverte et redirection de l'ancienne page par encore crawlée) ;
- A la prise en compte du nouveau maillage interne.
En fonction de la taille des sites, cette période peut varier de quelques jours à plusieurs semaines. Dans le meilleur des cas, cela peut se passer de façon transparente. Plus vous serez rigoureux et précis dans vos recommandations et dans la mise en place d'un plan de redirection en cas de changement d'URL, plus votre migration aura un impact bénéfique sur votre trafic SEO.
Vous avez désormais toutes les clés en main pour que votre refonte de site web se déroule bien ! Pour rappel, cet article est la conclusion d'un ensemble d'articles sur la refonte de site Web dont voici la liste :
- Refonte de site web : quels enjeux SEO ?
- Refonte de site web : l'analyse de l'existant
- Le scraping au service de votre migration SEO
- Refonte de site web : le passage au HTTPS
- Refonte de site web : le plan de redirections
- Refonte de site web : la création des règles de redirection
Bonne migration ! 🙂
![]() Aymeric Bouillat
Aymeric Bouillat
Consultant SEO Senior, YAPASDEQUOI

 de nous rejoindre
de nous rejoindre