


Les algorithmes des moteurs de recherche évoluent chaque jour un peu plus et font parfois l'objet de communication de la part des équipes qui les mettent en place. Ca a été le cas il y a quelques jours avec l'update BERT, une mise à jour intégrée par Google pour améliorer sa compréhension des requêtes longues et/ou complexes. Mais quels sont les algorithmes derrière BERT en général et quelles sont les implications SEO en particulier de cet update ? Explications par Sylvain Peyronnet, notre spécialiste reconnu de tous sur l'algorithmie des moteurs de recherche...
 Par Sylvain Peyronnet
Par Sylvain Peyronnet
Récemment (voir l’annonce [1]), Google a annoncé par la voix de son vice-président Search Pandu Nayak qu’une nouvelle routine de compréhension de la requête tapée par un utilisateur était en cours de mise en place, basée sur l’algorithme de machine learning BERT.
Qu’est-ce que BERT l’update, mais surtout qu’est-ce que BERT l’algorithme, et que permet-il de faire réellement ?
La requête, point bloquant pour un moteur de recherche qui veut améliorer la qualité de ses résultats
Un moteur doit réaliser de nombreuses tâches, plus ou moins coûteuses et plus ou moins importantes (voir la figure 1, qui présente le schéma général d’un moteur de recherche). Mais depuis plusieurs années, l’effort qui permet au moteur d’améliorer la qualité de ses résultats, et d’avancer vers la notion de moteur de réponse, se concentre principalement sur la compréhension de l’utilisateur.
L’utilisateur intervient à deux moments cruciaux dans la vie du moteur : tout d’abord lorsqu’il rentre sa requête pour exprimer son besoin informationnel, et ensuite lorsque la SERP lui est proposé et qu’il va implicitement en noter la qualité par le comportement qu’il adoptera (ce qu’il clique, mais surtout ce qu’il ne clique pas). L’update BERT que propose Google en ce moment intervient sur le premier moment : comprendre le besoin informationnel de l’utilisateur.
La notion de besoin informationnel est clé pour le moteur, mais les différents algorithmes qui étaient utilisés jusqu’ici n’étaient pas nécessairement toujours au top.
Pourquoi ? Car il y a de nombreuses ambiguïtés dans la langue, complexes même pour les êtres humains. En Français on se plait à utiliser le mot "Paris" comme par exemple dans cette phrase : J’ai vu Paris à Paris, elle travaille sur la vie de Pâris. (par ordre d'apparition : le prénom, la ville, le prince troyen).
En anglais, avec la sortie de BERT c’est le mot "bank" qui revient en force pour faire un bel exemple : The Bank is close to the river bank (la banque est proche de la rive du fleuve).
L’objectif de la fameuse update BERT est de mieux comprendre les ambiguïtés dans les mots d’une requête, de mieux comprendre le sens d’une requête, et tout simplement de mieux comprendre les contenus (par exemple de comprendre que le mot Paris n’est finalement pas le même objet selon le contexte qui l’entoure).
Un peu d’histoire algorithmique concernant la quête du sens
Ce qu’il faut comprendre c’est que la plupart des méthodes de traitement de la langue naturelle (NLP en anglais pour Natural Language Processing), n’ont pas été créées spécifiquement pour faire de la recherche d’information, sauf les toutes premières datant des années 60-70 avec des modèles fréquentiels naïfs basés sur la tf-idf (sujet déjà vu plusieurs fois dans nos articles sur Réacteur).
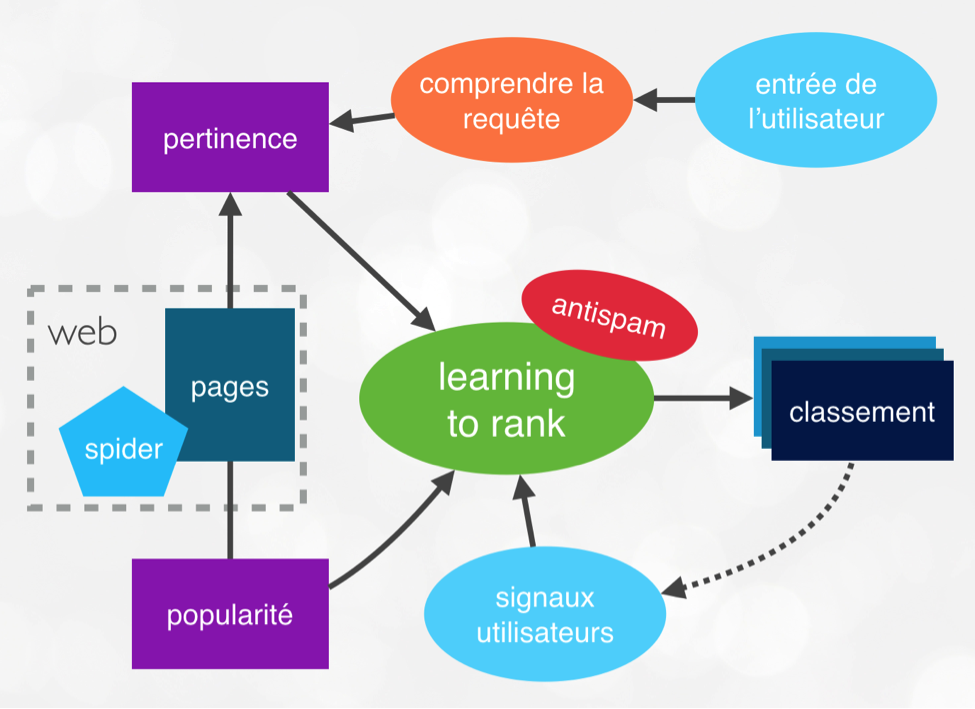
Fig. 1. Schéma général de l’architecture d’un moteur de recherche.
Au contraire, la plupart des approches ont été mises au point pour, soit "comprendre" complètement la langue, soit réaliser des tâches plus "nobles" comme la traduction automatique, le résumé automatique, etc.
Toutes les méthodes modernes que l’on voit actuellement (BERT, GPT-2, ELMO, etc.) s’inscrivent dans le cadre théorique des sémantiques distributionnelles [2]. L’idée générale de ce concept est que le sens d’un mot est fixé par l’apparition d’autres mots autour de lui (c’est-à-dire par son contexte). Les méthodes fréquentielles et l’utilisation du concept de co-occurence dans les premières années des moteurs de recherche vont constituer une première approche de ce type de sémantique.
Même si la plupart des méthodes distributionnelles visent le même but, elles sont définies par certaines primitives qui changent tout d’un point de vue qualité des résultats. En premier lieu, la notion de contexte (s’agit-il des mots autour d’un mot donné, ou bien d’objets définis par la grammaire ?), la taille de la fenêtre de contexte et son sens de lecture (on verra plus loin que la force de BERT se situe dans cette définition), la méthode de calcul des poids des mots, la mesure de distance utilisée (cosinus de Salton ou une autre distance plus ou moins standard), etc.
Nous avons pour l’instant parlé de méthodes distributionnelles, mais le terme consacré lorsque l’on fait des moteurs de recherche ou du SEO est "modèle vectoriel", car tous les objets sémantiques (mots, phrases, textes) vont être représentés par des vecteurs. Un autre terme important est celui de "word embeddings" (une traduction bien approximative serait "encodage des mots"), toutes les méthodes modernes depuis word2vec jusque BERT calculent des word embeddings. Et c’est cette notion dont je vais raconter brièvement l’histoire.
Les word embeddings sont par essence indissociables des réseaux de neurones (quand il n’y a pas de réseau de neurones en jeu on parlera plutôt de vecteurs de contexte). Ceci pour une bonne raison : la notion d’embedding est une notion liée aux réseaux de neurones.
La première approche sur le sujet est celle du modèle neural standard de Bengio et al. (voir la référence [3]). Ce modèle est le premier basé sur des réseaux de neurones, et réalise une prédiction de la probabilité d’apparition d’un mot après l’apparition d’un premier mot. Cela permet par exemple de faire de l’auto-complétion intelligente ou de la correction automatique à la volée (par exemple sur mobile). L’approche de Bengio date de 2001, et pendant plusieurs années, rien n’a été fait de plus, principalement car plusieurs barrières l'empêchait : le manque de puissance de calcul (c’est venu plus tard), l’absence d’astuces algorithmiques que nous verrons un peu plus loin, et la faiblesse de la taille des datasets disponibles.
C’est à partir de 2008 que la bascule va s’opérer. Tout d’abord grâce à une astuce algorithmique dûe à Collobert et Weston (on parle d’ailleurs du modèle C&W - référence [4]). L’idée est toute simple (mais pas sa réalisation) : plutôt que de prédire la probabilité qu’un mot apparaisse derrière un autre, la méthode donne un score qui permet de comparer la vraisemblance d’existence d’une phrase par rapport à sa variante avec un mot différent. Cela parait anodin, mais c’est cela qui va permettre de créer les méthodes modernes d’embedding vectoriel.
Le jalon suivant est en 2013, c’est Tomas Mikolov qui va amener la vraie révolution avec word2vec (référence [5], qui est un véritable all-star game avec Mikolov, Chen, Corrado et Dean, soit tous les cadors de l’IA chez Google). On pourrait parler pendant des heures de word2vec, qui est la première méthode réellement opérationnelle d’embedding vectoriel. On se contentera de dire que word2vec présente deux nouveaux modèles d'entraînement : le continuous-bag-of-words, dans lequel on essaye de prédire la probabilité d’apparition d’un mot dans une phrase où on l’aurait oublié, et le skip-gram, où l’on prédit la probabilité d’une phrase à partir d’un seul mot de la phrase.
Word2vec est une révolution, mais très rapidement la méthode va être améliorée. Tout d’abord avec GloVe (référence [6]), qui va prendre en compte explicitement l’information de co-occurrences entre les mots pour calculer des décalages vectoriels qui vont embarquer les relations entre les mots. A noter : ces décalages existent dans word2vec, mais ne sont qu’un "by-product" de la méthode, alors qu’avec GloVe leur fabrication est volontaire.
Une autre amélioration a été faite avec Fasttext (voire référence [7], chez Facebook, Mikolov ayant été recruté là-bas après son stage chez Google). Fasttext travaille sur des décompositions des mots en groupes de n caractères consécutifs, ce qui va permettre d’apprendre le sens de mots qui ne sont pas dans le dataset d’apprentissage, en décomposant ces derniers en fragments qui sont eux connus. En procédant ainsi, la qualité de résultat sur les mots connus est par ailleurs amélioré.
Enfin, les tous derniers modèles que sont ELMO, GPT-2 et BERT sont basés sur des méthodes algorithmiques un peu plus touffues (notamment la notion de transformer pour les deux derniers) et donnent encore de meilleurs résultats.
Avant de passer à BERT, pourquoi tout cela performe bien mieux que les modèles fréquentiels des années avant 2000 ?
La question que l’on peut se poser est donc de savoir si ces modèles basés sur des algorithmes bien plus complexes que ceux qui se contentent de compter les mots sont réellement plus efficaces. D’un point de vue industrie, il semble que le choix ai déjà été fait, et tous les moteurs utilisent a minima des méthodes équivalentes à word2vec, mais souvent des méthodes proches de BERT ou équivalents (par exemple Qwant utilise des modèles assez proches pour son prototype de moteur de recherche image - pas encore déployé hors prototype disponible à l’adresse research.qwant.com).
La plupart du temps, le folklore SEO conclut que si ces méthodes sont meilleures, c’est grâce à la "magie" des réseaux de neurones, ou sur le fait qu’il s’agit de méthodes de prédiction plutôt que de méthodes de calculs de fréquences. En pratique, les choses ne sont pas si simples et en théorie on ne sait pas si ces méthodes sont réellement meilleures. Mais il semble qu’elles soient toujours plus faciles à utiliser et que les méthodes plus anciennes ne soient capables de rivaliser qu’au prix d’un paramétrage très laborieux.
Ce que l’on peut dire en tout cas, c’est que pour la plupart des tâches du NLP, les expériences sont plutôt en faveur des méthodes type Word2vec, GloVe et compagnie (voir la référence [8] par exemple).
Et BERT dans tout ça ?
BERT est un nouveau type de méthode basée sur des réseaux de neurones différents : les transformers, là où les précédentes méthodes étaient basées sur d’autres objets, dont les réseaux de neurones récurrents (RNNs). BERT a été présenté au public en 2018 (voir le post de blog [9] par Devlin et Chang, tous deux chercheurs chez Google).
Il y a deux raisons qui font que les transformers sont plus efficaces que les RNNs, la première est qu’ils ont été développés largement pour tirer partie des architectures modernes de processeurs, comme par exemple les TPUs de Google. Sachant que le nerf de la guerre en machine learning est principalement la puissance de calcul nécessaire pour faire du calcul vectoriel, tout algorithme qui profite d’une architecture dédiée aura nécessairement un avantage concurrentiel indéniable.
La deuxième raison est d’ordre théorique et est très intuitive. Les RNNs (et toutes les méthodes précédentes, sont intrinsèquement séquentielles). Cela veut dire que la data est lu une fois, dans un sens fixé à l’origine, c’est-à-dire de la gauche vers la droite ou l’inverse.
Imaginons une méthode qui apprend le sens des mots en lisant de la gauche vers la droite, l’exemple qui montre la limite de la méthode est donné par Devlin lui-même : "I arrived at the bank after crossing the [mot masqué]"
Quel est le sens du mot bank ? Il dépend complètement du mot masqué. Si le mot masqué est "river" alors "bank" signifie "rive", si c’est "street" alors on parle d’une banque. L’ambiguïté ne sera donc pas levée facilement par l’algorithme. On peut construire un exemple similaire qui empêche la lecture dans l’ordre inverse d’être efficace. L’astuce est donc de lire les phrases dans les deux sens, le réseau de neurones doit être bidirectionnel.
Ca tombe bien, BERT signifie Bidirectional Encoder Representation for Transformer. BERT est donc sujet à moins de problèmes de compréhension du sens des mots. En pratique cela veut dire qu’un modèle de la langue comme BERT va encoder différemment le mot "bank" (par exemple) selon son contexte d’utilisation. Il y aura donc dans l’espace vectoriel des mots plusieurs vecteurs pour le mot "bank", tous différents pour capter des sens différents du mot. Les méthodes précédentes comme word2vec et Fasttext n’étant pas capables de faire la différence, elles ont un encodage unique pour un mot ambigu, ne permettant jamais de vraiment lever l'ambiguïté.
Il y a de nombreux points techniques concernant BERT, mais l’idée de l’algorithme en dehors du principe de bi-directionnalité, est de masquer arbitrairement plusieurs mots d’une phrase d'entraînement, et de calculer ensuite une prédiction concernant les mots qui ont été masqués, à partir du contexte total (mots à droite et à gauche du mot masqué). C’est ce que l’on appelle la technique MLM (Mask Language Model).
Par ailleurs, BERT utilise une technique appelée NSP (Next Sentence Prediction). L’objectif est d’apprendre les relations entre les phrases du dataset. Pour cela, le modèle reçoit lors de la phase d'entraînement des paires de phrases, et il apprend à prédire si ces phrases sont compatibles (c’est-à-dire qu’un être humain ne sera pas surpris de les voir l’une à la suite de l’autre dans un document textuel), ou bien si au contraire l’une semble n’avoir aucun rapport avec l’autre.

Fig. 2. exemple d’utilisation du NSP.
La figure 2, tirée de [9], illustre cette technique de NSP. Les deux phrases à gauche auront une prédiction de compatibilité, celles de droite seront considérées comme sans rapport (à raison a priori).
En utilisant ces deux techniques simultanément, BERT fournit des résultats sensiblement meilleur que les méthodes précédentes ou concurrentes (principalement GPT-2 par OpenAI et Elmo).
Enfin, BERT est disponible en open source pre-entraîné de manière non supervisé sur des datasets de grande taille (l’intégralité de Wikipedia par exemple). Cela permet ensuite de créer des cas d'usage spécifiques en ajoutant un entraînement supervisé spécifique peu coûteux. On peut ainsi s’en servir pour faire du cross-learning (ou transfer learning), c’est-à-dire transposer la connaissance d’une langue à une autre langue, ce qui est très pratique quand on fait par exemple un moteur de recherche d’images. Dès qu’on sait bien répondre en anglais, en utilisant une méthode comme BERT on sait aussi répondre pour d’autres langues, sans aucun surcoût.
BERT et le SEO ?
Il y a déjà une littérature plus qu’abondante sur BERT et le SEO. Sur le blog de Google (référence [1]), tout est assez bien expliqué en terme de l'utilisation que va en faire le moteur.
Grosso modo il s’agit de faire, en mieux, ce que faisait déjà les algorithmes mis en place lors de l’update Rankbrain de 2015.
Avec un modèle de la langue qui est moins sujet aux ambiguïtés, le moteur pourra beaucoup mieux sérier le sens réel d’une requête, c’est-à-dire qu’il comprendra beaucoup mieux le besoin informationnel, qui en plus de la thématique comporte surtout une intention spécifique.
L’effet principal de BERT en terme de SEO peut être la "déconcentration" des résultats. Par essence, quand le moteur ne comprend pas bien les intentions, le pool de pages éligibles à être positionnées est "fusionné".
Qu’est ce que cela veut dire ? Imaginons deux requêtes parlant de machine à café, mais l’une est informationnelle tandis que l’autre est commerciale (transactionnelle). Si le moteur ne sait pas différencier les intentions (des sites et des requêtes), il va prendre les pages des deux intentions pour essayer de les positionner sur les deux requêtes. Imaginons qu’il y avait 1 000 pages pour chaque intention, cela signifie que votre page d’intention commerciale est à la lutte avec 1999 pages pour la page 1, alors que si le moteur sait comprendre les intentions vous êtes à la lutte avec 999 pages seulement.
L’effet direct est donc que les gros sites qui rankent grâce à la popularité avant la sémantique vont mécaniquement perdre des positions, tandis que les pages qui ciblent des requêtes avec des intentions très spécifiques (de la longue voire très longue traîne) auront de meilleures positions moyennes (mais sur moins de requêtes).
Au final, la théorie veut que le moteur mettra en avant des pages plus qualifiées, avec de meilleur taux de conversion, mais moins souvent.
Pour le SEO, cela change quelque chose : un travail supplémentaire doit être fait pour créer des contenus réellement adaptés aux besoins des internautes. Fini le trafic organique au kilomètre, place aux pages qui sont là pour drainer peu de trafic, mais beaucoup de conversions ! Et c'est plutôt une bonne nouvelle...
Références
[1] Understanding searches better than ever before. Prandu Nayak. https://www.blog.google/products/search/search-language-understanding-bert/
[2] Firth, J.R. (1957). "A synopsis of linguistic theory 1930-1955". Studies in Linguistic Analysis: 1–32. Reprinted in F.R. Palmer, ed. (1968). Selected Papers of J.R. Firth 1952-1959.
[3] Bengio, Y., Ducharme, R., Vincent, P., & Janvin, C. (2003). A Neural Probabilistic Language Model. The Journal of Machine Learning Research, 3, 1137–1155.
http://jmlr.csail.mit.edu/papers/volume3/bengio03a/bengio03a.pdf
[4] Collobert, R., & Weston, J. (2008). A unified architecture for natural language processing. Proceedings of the 25th International Conference on Machine Learning – ICML ’08, 20(1), 160–167.
https://ronan.collobert.com/pub/matos/2008_nlp_icml.pdf
[5] Mikolov, T., Corrado, G., Chen, K., & Dean, J. (2013). Efficient Estimation of Word Representations in Vector Space. Proceedings of the International Conference on Learning Representations (ICLR 2013), 1–12.
https://arxiv.org/abs/1301.3781
[6] Pennington, J., Socher, R., & Manning, C. D. (2014). Glove: Global Vectors for Word Representation. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, 1532–1543
https://nlp.stanford.edu/projects/glove/
[8] Baroni, M., Dinu, G., & Kruszewski, G. (2014). Don’t count, predict! A systematic comparison of context-counting vs. context-predicting semantic vectors. ACL, 238–247.
https://www.aclweb.org/anthology/P14-1023/
[9] https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html
![]() Sylvain Peyronnet, fondateur de la régie publicitaire sans tracking The Machine In The Middle (http://themachineinthemiddle.fr/).
Sylvain Peyronnet, fondateur de la régie publicitaire sans tracking The Machine In The Middle (http://themachineinthemiddle.fr/).

 de nous rejoindre
de nous rejoindre