


Le Web en général et le SEO en particulier est empli de croyances, mythes et autres légendes parfois folkloriques, notamment sur les critères de pertinences utilisés par l'algorithme de moteur, le fonctionnement des robots (Googlebot, Bingbot), etc. Certaines sont même là depuis des années et ont la vie dure... Sylvain Peyronnet, dans cet article, en évoque quelques-uns (nofollow, ratio code/texte, publicité, étanchéité des silos, temps de chargement des pages, etc.) et explique pourquoi il ne faut pas trop rapidement prendre en compte les « fake SEO » qui traînent ici ou là...
 Par Sylvain Peyronnet
Par Sylvain PeyronnetLe référencement est en voie de normalisation depuis des années, mais encore maintenant, les bases ne sont pas toujours très bien maîtrisées. La faute à qui ? Un peu à tout le monde, mais surtout la faute à un écosystème qui n’est pas toujours aussi vigilant qu’il le faudrait lorsque se propage une nouvelle « bonne pratique ».
Sur les bases, on a cependant vu ces dernières années une substantielle amélioration de la connaissance des principes du SEO, et c’est maintenant sur des points plus précis et souvent un peu techniques que des zones d’ombre subsistent, propices alors à la création de véritables légendes urbaines.
Dans cet article un peu plus léger que ceux que j’ai l’habitude d’écrire ici, nous allons passer en revue ensemble quelques assertions que l’on retrouve souvent, et on va voir si elles sont vraies ou fausses. J’ai choisi quelques uns de ces mythes que je trouve représentatifs, mais il y en a bien d’autres.
En mettant un lien en nofollow on va “garder” plus de PageRank, et on aura un meilleur maillage interne.
Le sujet du nofollow est celui qui fait le plus parler dès lors qu’on aborde les sujets de linking. A chacune de nos formations depuis 7 ou 8 ans, on nous en parle. L’invention du nofollow n’est pas nouvelle, c’est en janvier 2005 que l’idée est introduite via le blog officiel de Google (voir la référence [1]).
Basiquement, il s’agit d’un indicateur qui dit que le surfeur aléatoire, que nous avons abondamment décrit dans le cadre de la lettre Réacteur, doit se téléporter plutôt que de suivre un lien. Très concrètement, cela transfère la partie du PageRank de la page source du lien qui devait transiter vers la page cible vers le reste du Web de manière équitable.
Il n’y a donc aucun gain en terme de popularité à attendre en mettant des liens en nofollow sur votre site : soit le lien est externe (de votre site vers un autre site), dans ce cas tout ce que vous faites, c’est de donner la popularité qui était pour la cible du lien à tout le Web, soit il est vers une des pages de votre site (lien interne), et dans ce cas vous perdez de la popularité au profit du reste du Web. Notez bien cette dernière phrase : en transformant un lien interne follow en nofollow, vous baissez votre positionnement.
Il y a désormais des discussions plus fines sur le sujet à cause du modèle du surfeur raisonnable. En effet, tous les liens ne se valent pas au niveau d’une page web et certains transfèrent plus de popularité que d’autres, mais cela ne change pas l’idée, un lien peu contributif qui passe en nofollow, cela reste une perte (mais faible).
Si je rapporte des sous à Google en ayant des bannières de chez eux sur mon site, ou si j’ai Google Analytics, ou XYZ dans l’écosystème Google, alors mes positions seront meilleures.
Il y a une grande tendance chez les pros du web à chercher des explications toujours un peu complexes à tout et n’importe quoi. On va rapidement croire par exemple que le site qui marche bien c’est “parce qu’il fait gagner plein d’oseille à Google”. Il y a ainsi plein de petits signaux potentiels auxquels les gens croient un peu trop facilement.
Il se trouve que Kevin Richard et moi-même avons mené il y a quelques années une étude sur ce sujet (voir la référence [2]), pour voir parmi certains signaux ceux qui étaient importants pour le ranking et ceux qui n’étaient pas vraiment des signaux.
Les conclusions de cette étude étaient nombreuses, mais une partie est résumée dans le tableau de la figure 1.
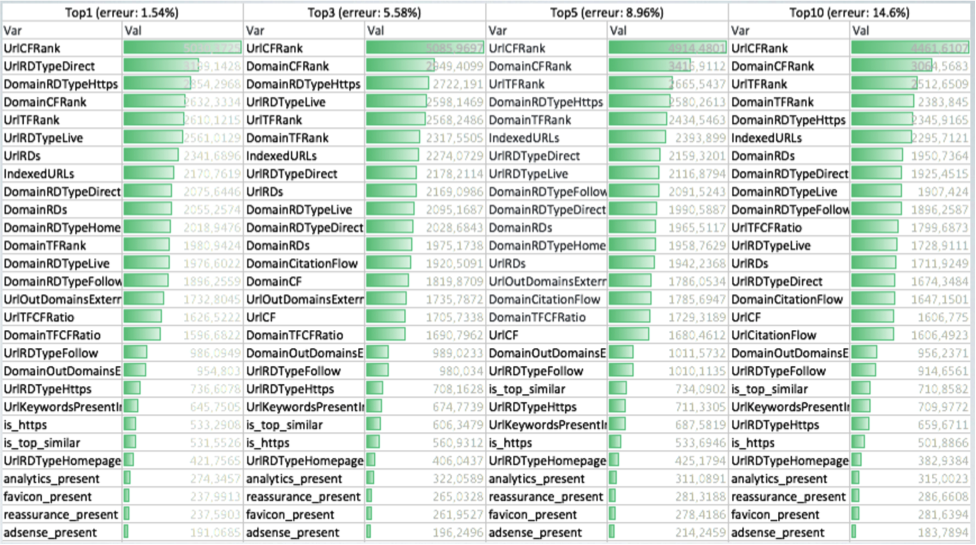
Fig. 1. Étude sur les facteurs de ranking.
Ce type de figure n’est pas forcément facile à lire, je vais donc la décrire. On y voit des colonnes qui permettent de savoir quels sont les facteurs importants (hors sémantique et vitesse) pour rentrer dans le top 10, puis top 5, puis top 3, puis premier de la SERP.
On voit que dans tous les cas adsense_present est en bas du tableau : en aucun cas la présence ou non d’adsense sur une page n’a d’impact sur la capacité d’une page à se positionner. C’est aussi le cas pour la présence d’un tag analytics, de divers éléments de réassurance ou encore d’un favicon.
Bref, si des publicités Google Adsense vous font vivre, vous pouvez y aller, mais pas la peine d’en mettre pour le SEO 😉
La meta description n’a aucune utilité en SEO, on peut la laisser vide, Google se débrouillera
Ce mythe là, heureusement on l’entend de moins en moins, mais il a la vie dure, principalement parce que Google dit que la meta description n’est pas un signal de ranking. Mais ce n’est pas parce que ce n’est pas un signal de ranking que c’est inutile en terme de SEO.
Première chose, en dehors du SEO c’est indispensable d’avoir la meilleure meta description possible, car c’est elle qui va créer l’attractivité au niveau de la SERP en affichant votre promesse au visiteur potentiel via le snippet. Est-ce que c’est raisonnable de laisser Google le faire ? Je ne crois pas.
Par ailleurs, c’est l’interaction entre les internautes et le moteur qui permet à ce dernier de déterminer la satisfaction des internautes. Cette satisfaction inférée par le comportement des visiteurs va ensuite être utilisée par un algorithme de machine learning pour pondérer entre eux tous les signaux SEO, alors oui la meta description est donc utile puisqu’elle va permettre de créer une meilleure attractivité de votre site et vous permettre d’orienter les signaux choisis par le moteur comme étant ceux importants pour votre thématique.
Pour faire une analogie, dire que la meta description n’est pas utile pour le SEO, c’est un peu comme dire que les couvertures des livres ne sont pas utiles pour choisir ce qu’on va lire. Techniquement on peut effectivement faire sans, mais ça aide vraiment pas mal quand même…
Quand on fait du siloing, il ne faut jamais faire de liens entre silos.
Là on est sur un point qui est plus complexe. Pourquoi ? Tout simplement parce que ce qui était vrai il y a 15 ans n’est plus vrai maintenant.
Avec le PageRank thématique (voir la référence [3]), les liens ne transmettent quasiment plus de popularité si le contenu de la page source et de la page cible du lien ne sont pas en “cohérence sémantique”. Si vous faites un lien entre deux silos qui sont sur des thématiques très différentes, ces liens existeront pour les visiteurs mais pour le moteur, ils n’auront pas d’impact.
C’est d’ailleurs un point très important, comme à son habitude Google mets en place des algorithmes qui ont pour but de rendre l’expérience utilisateur meilleure, là c’est typiquement le cas puisque soudainement, on peut mettre des liens utiles à l’internaute mais que l’on s’interdisait de mettre pour que le moteur favorise le site.
Bref, sur ce point, maintenant il n’y a plus autant besoin de maintenir artificiellement l’étancheité entre les silos. Ils doivent cependant l’être un minimum pour que la “customer journey” ne perde pas les visiteurs.
Un site qui se charge vite c’est ultra important pour le SEO.
Bon, un site qui se charge vite, c’est bien entendu mieux qu’un site qui se charge lentement, et on sait que pour les aspects de conversion c’est très important. Ceci étant (mais on s’éloigne du sujet), il y a une vraie différence entre la vitesse et la perception de la vitesse. Si ce sujet vous intéresse il existe un exposé très intéressant par Ilya Grigorik sur Youtube (ça date de 2014, c’est la référence [4], et Ilya Grigorik est maintenant directeur des relations avec les développeurs chez Google).
Pour le reste c’est une discussion sans fin. Ce que l’on sait, c’est qu’il y a une faible corrélation entre le TTFB (time to first byte, grosso modo le temps de réponse du serveur qui héberge le site) et le positionnement, principalement sur les premières places de la SERP. Mais cette corrélation est très faible. On sait aussi que les sites vraiment très longs à charger se positionnent assez mal, mais c’est sans doute plutôt un effet du fait que le bot va lâcher l’affaire plutôt qu’un signal purement dû à la vitesse de chargement trop longue. L’idée dans ce cas est qu’on ne peut pas vraiment positionner un contenu qu’on n’a pas pris le temps de lire…
Je résume : un site rapide c’est bien, il y a un petit effet, mais ça ne doit pas être une priorité côté SEO (mais coté UX et developpement, ça devrait l’être, ne serait-ce que pour l’amour du travail bien fait).
Voir également l'article sur le mode de chargement des pages web par Daniel Roch le mois dernier et ce mois-ci sur Réacteur.
Être le premier est le plus important.
Cette affirmation est, sauf cas exceptionnels, de plus en plus l’expression d’un ego souffrant plus que celle du pragmatisme des affaires. Sauf à être rémunéré à la position c’est plutôt le trafic organique, de préférence qualifié, qui est l’objectif du SEO (pour in fine générer du revenu bien entendu).
Une étude de Ahrefs (voir la référence [5]) est à ce titre extrêmement intéressante. Vous pourrez y trouver quelques lieux communs, mais surtout une information importante (voir la figure 2) sur le fait que les pages qui sont en première position ne sont pas toujours celles qui drainent le plus de trafic.
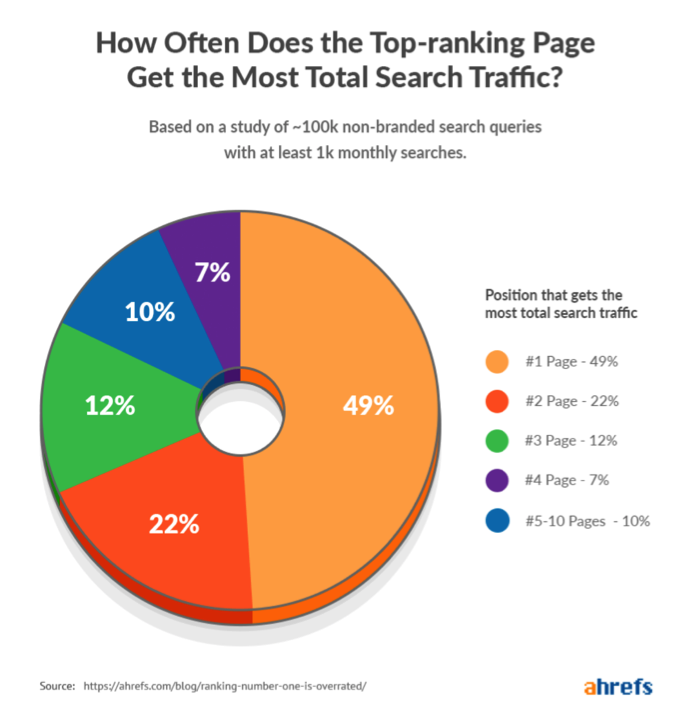
Fig. 2. Qui a du trafic organique ?
La page en première position de la SERP pour au moins un mot-clé n’est pas celle qui aura au global le plus de trafic organique dans 51% des cas. Pourquoi ? on peut imaginer des tas de raisons, mais une piste est celle du focus du contenu : avec plus de contenu, et un vocabulaire plus diversifié, on se positionne assez vite sur plusieurs requêtes connexes. Dans tous les cas de requêtes riches avec de nombreuses variantes qui expriment le même besoin informationnel, cela peut vite faire un très beau trafic.
Il est à noter que la plupart des outils ne voient pas du tout ce phénomène, car le monitoring par pool de mots-clés opaques ne permet pas de mesurer finement ce type de chose.
C’est d’ailleurs pour cela qu’un des premiers conseils que l’on donne post-audit SEO est généralement de se créer son pool de mots-clés et d’utiliser un outil de suivi de mots-clés configurable.
Si on a un positionnement en amélioration après le déploiement d’une mise à jour importante de l'algorithme, on est tranquille.
On touche là à un mythe qui a un énorme impact sur les process. Quand une grosse mise à jour de son algorithme est mise en œuvre par Google, en particulier via du machine learning, le moteur va souvent regarder ce qui se passe seulement sur les sites qui sont bien positionnés (c’est typiquement ce qui se passe dans le cas du filtre Penguin). Il n’y a en effet aucun intérêt à pénaliser des sites qui sont déjà loin dans le classement.
Après le passage du filtre, les premiers étant pénalisés, ils vont reculer au profit des moins bons, qui ont alors une petite fenêtre de tir pour rectifier ce qui est problématique chez eux et garder ces bons positionnements acquis par chance.
Le référenceur qui se sait un peu fautif, qui a gagné des places post-filtre et qui ne regarde pas ce qu’il doit faire pour se remettre dans le rang doit savoir qu’il sera le prochain pénalisé.
Bien entendu, on peut aussi être en amélioration parce qu’on était moyennement classé, mais très propre et donc on remonte parce que les spammeurs ont été pénalisés, sans risques pour la suite. Ce qui compte c’est de bien analyser la situation dans tous les cas de mouvements, à la baisse comme à la hausse.
Si on a un mauvais ratio text-to-code on est fichu.
Pour finir en beauté voici un mythe qui circule beaucoup, au point que certains outils fournissent la métrique associée : le ratio entre la taille du texte et la taille du code source de la page. A chaque fois que l’on m’en parle, je ne peux que me demander quel est le raisonnement caché derrière cette métrique. A contenu visible et lisible égal, la taille du code source va essentiellement dépendre de facteurs externes, en premier lieu le CMS et le thème choisi lorsque le site n’est pas fait main « à l’ancienne ». Dans ce cas, pourquoi Google, dont le but est de favoriser les contenus pertinents les plus populaires et utiles à l’internaute, pousserait certains plutôt que d’autres ?
Le seul point d’accroche réel autour de ce mythe est sur les valeurs extrêmes : si une page est composée de plusieurs mégaoctets de code alors bien sûr, il y a un souci, mais à ce stade, le souci n’est pas le ratio !
Une petite conclusion
Je n’ai ici abordé que quelques mythes que l’on rencontre en se promenant sur les forums, Twitter ou les groupes Facebook. Il y en a bien entendu beaucoup plus. Les mythes SEO c’est un peu comme les fake news : si on réfléchit un peu, on voit vite que l’assertion est un peu trop péremptoire, et en se renseignant auprès des bonnes sources (pas le “renseignes-toi” des complotistes donc, mais bien se renseigner dans les livres, dans les nombreuses archives de conférences, etc.) on voit assez vite ce qu’il en est.
Et surtout, et là je m’adresse aux SEOs juniors : il n’y a aucune honte à demander des éclaircissements à des plus seniors que soi si vous ne savez pas quoi penser sur tel ou tel sujet. 😉
Références
[1] https://googleblog.blogspot.com/2005/01/preventing-comment-spam.html
[2]
https://fr.slideshare.net/512banque/les-serps-ont-parl-comment-font-ceux-qui-performent-en-2018
[3] Haveliwala, T. H. (2003). Topic-sensitive PageRank: A context-sensitive ranking algorithm for web search. Knowledge and Data Engineering, IEEE Transactions on, 15(4), 784-796.
http://ilpubs.stanford.edu:8090/750/1/2003-29.pdf
[4] https://youtu.be/7ubJzEi3HuA
[5] https://ahrefs.com/blog/ranking-number-one-is-overrated/
![]() Sylvain Peyronnet, concepteur de l'outil d'analyse de backlinks Babbar.
Sylvain Peyronnet, concepteur de l'outil d'analyse de backlinks Babbar.

 de nous rejoindre
de nous rejoindre