

![]() L'outil Screaming Frog permet de crawler un site pour en extraire bon nombre de données utiles en SEO. Mais il recèle quelques fonctionnalités peu connues et pourtant très utiles et qui permettent souvent de gagner beaucoup de temps. Vous pensez bien connaître Screaming Frog ? Cet article va certainement vous surprendre...
L'outil Screaming Frog permet de crawler un site pour en extraire bon nombre de données utiles en SEO. Mais il recèle quelques fonctionnalités peu connues et pourtant très utiles et qui permettent souvent de gagner beaucoup de temps. Vous pensez bien connaître Screaming Frog ? Cet article va certainement vous surprendre...
Screaming Frog est un crawler fréquemment utilisé par les référenceurs : véritable boîte à outil du SEO, il permet non seulement de crawler des sites Web pour effectuer des analyses poussées, mais également de récupérer de nombreux éléments sur les pages via des expressions régulières, des sélecteurs CSS ou le langage Xpath. Par ailleurs, il dispose de plusieurs connecteurs avec des outils externes (Google Search Console, Google Analytics, Ahrefs, etc.) afin de qualifier les URL pour permettre d’identifier rapidement les KPI liés à des pages spécifiques : nombre de liens externes, clics, temps de chargement,…
Régulièrement mis à jour, cet outil se voit doté de nouvelles fonctionnalités parfois discrètes et peu connues. Nous verrons dans cette série d’articles autour de Screaming Frog Seo Spider, la façon dont un crawl doit être configuré, les fonctionnalités intéressantes de l’outil, mais surtout la façon dont il faut analyser les données pour déployer une stratégie d’optimisations SEO. Rappelons également que cet outil est disponible pour 3 familles de systèmes d’exploitation : Windows, MacOS, et Linux (distribution Ubuntu).
Avant de lancer un crawl, il est nécessaire de configurer un certain nombre de paramètres : en fonction des sites, il peut être utile de crawler (ou non) certains éléments comme les images ou les fichiers JS et CSS, et le comportement du crawler pourrait ne pas permettre de détecter certaines problématiques. Nous allons voir dans cet article les principaux éléments à paramétrer avant de lancer un crawl.
Autres articles à lire sur Screaming Frog :
Stockage des crawls
Mode Base de données
L’outil dispose de 2 modes de stockage : « Memory Storage » et « Database Storage ». Par défaut, il permet de lancer des crawls en utilisant la mémoire vive de l’ordinateur (Memory Storage), pour ensuite les enregistrer sous la forme de fichiers portant l’extension « .seospider ».
La limite de 2Go par défaut peut être augmentée en fonction de l’importance des crawls à réaliser et des éléments récupérés (Menu Configuration > System > Memory Allocation), mais il est inutile d’allouer plus de 50% de cette mémoire, ce qui ralentirait le fonctionnement du système d’exploitation et serait contre-performant.
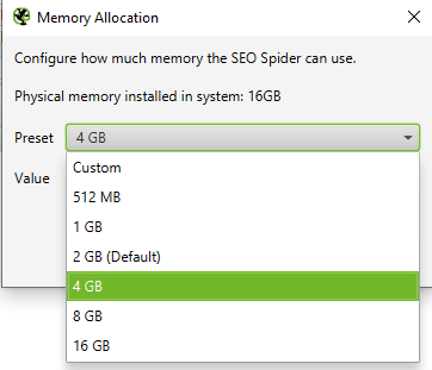
Augmentation de la mémoire vive utilisée pour un crawl en mode "Memory Storage"
L’écriture de données sur la mémoire vive permet de crawler des sites de façon rapide et performante. Cependant, elle peut vite trouver ses limites dans le cas où les sites à crawler comportent plusieurs centaines de milliers d’URL.
La capacité de la mémoire RAM étant limitée, il est préférable d’utiliser un autre mode de stockage pour des sites importants et des crawls réguliers, à savoir le mode « Storage Mode » (Menu Configuration > Système > Storage Mode) :
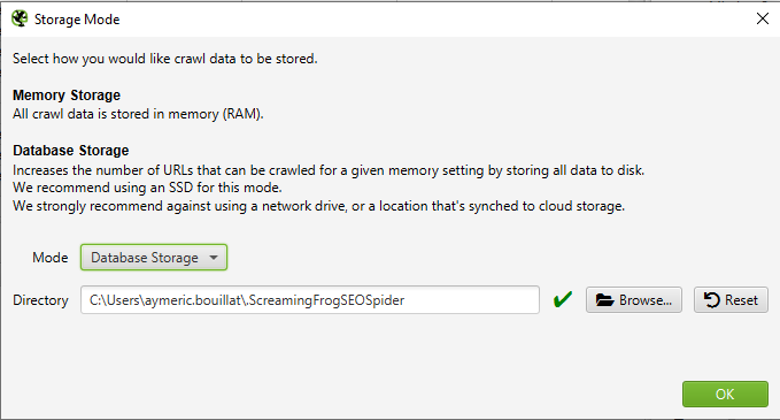
Configuration du "Storage mode"
Avec un disque SSD (recommandé) qui dispose de temps d’accès rapides et d’un taux de transfert élevé, ce mode d’enregistrement écrira directement sur le disque dur l’ensemble des données de vos crawls. Outre cet avantage permettant de crawler des sites conséquents, ce mode fera apparaître une nouvelle entrée dans le menu « File » appelée « Crawls » qui listera l’ensemble de vos crawls, et qui vous permettra de les renommer ainsi que de les organiser à votre guise en fonction de vos projets :
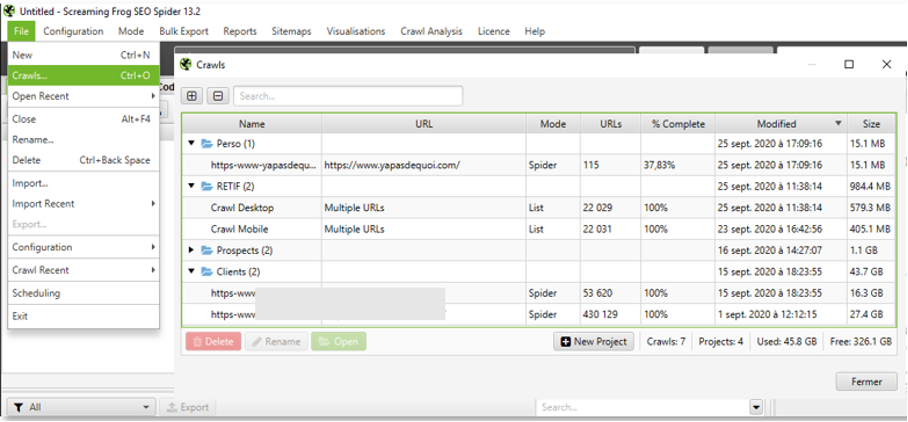
Organisation des crawls effectués par projet
Dans ce mode, nul besoin d’enregistrer vos crawls, qui seront stockés dans une base de données (utile en cas de plantage de votre ordinateur, ce qui évitera de repartir de zéro). Veillez malgré tout à régulièrement faire le ménage pour éviter de surcharger le disque dur inutilement (cf. capture ci-dessus, espace occupé indiqué en bas à droite).
Comportement du crawl
User-agent
Avant de paramétrer les multiples options liées au comportement du crawler, il est indispensable de paramétrer son identité ainsi que sa vitesse. En effet, Screaming Frog envoie son identité aux serveurs qu’il visite via son « User-Agent », de la même manière que le fait un navigateur ou un robot. Ce user-agent spécifique par défaut (« Screaming Frog Seo Spider » pouvant être bloqué par défaut sur certains serveurs, il est préférable de le modifier via le menu « Configuration > User-agent ».
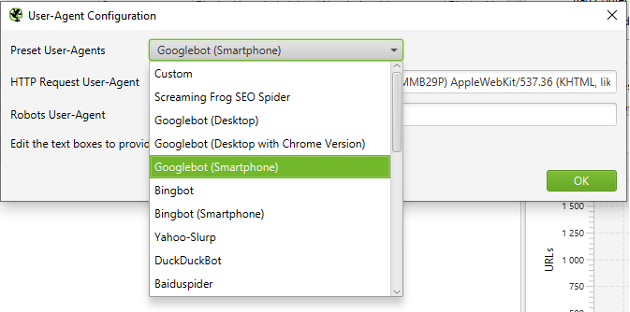
Paramétrage du user-agent
Il faut également garder à l’esprit que certains sites disposent d’une URL dédiée pour leur version mobile (m.monsite.com), ou encore renvoient du contenu différent en fonction de l’appareil utilisé (dynamic serving).
Google utilisant depuis 2018 l’index mobile dans son moteur, une mauvaise configuration du user-agent pourrait délivrer une version erronée du site à analyser (le mieux est de regarder dans les paramètres de la Search Console pour votre site quelle est la version de Googlebot utilisée : Desktop ou Mobile et de configurer votre crawl en conséquence).
Par ailleurs, certains sites effectuant du rendu JS via du SSR (Server Side Rendering), la configuration du user-agent avec « Googlebot (Smartphone) » vous permettra d’être au plus proche du contenu délivré à Google, tout en accélérant le crawl dans le cas du SSR, le rendu JS du crawler étant particulièrement gourmand.
Javascript
Screaming Frog a la capacité d’effectuer un rendu JS des pages crawlées. Cette option est utile quand des sites utilisent des frameworks Javascript sans paramétrage de SSR. Vous trouverez les éléments relatifs au rendu JS dans la fenêtre Configuration > Spider (onglet Rendering).
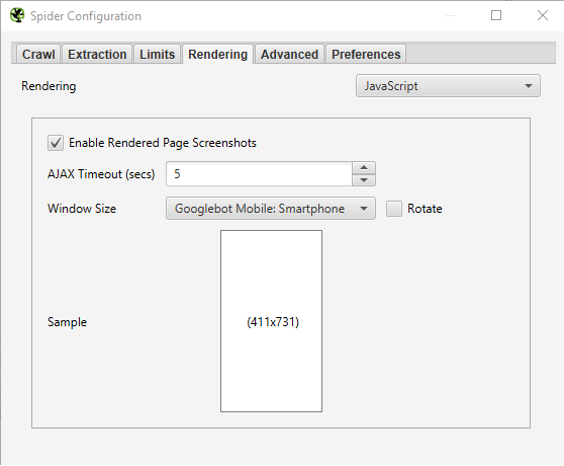
Option de rendu JS
Il vous sera possible de crawler des sites en React, Angular, Ember ou tout autre framework, mais pas exactement à la façon de Google, dans la mesure où le moteur de rendu de Screaming Frog n’est pas le même que celui de Google. En effet Googlebot Evergreen utilise le moteur de rendu récent de Chrome, tandis ce que Screaming Frog utilise une version plus ancienne :
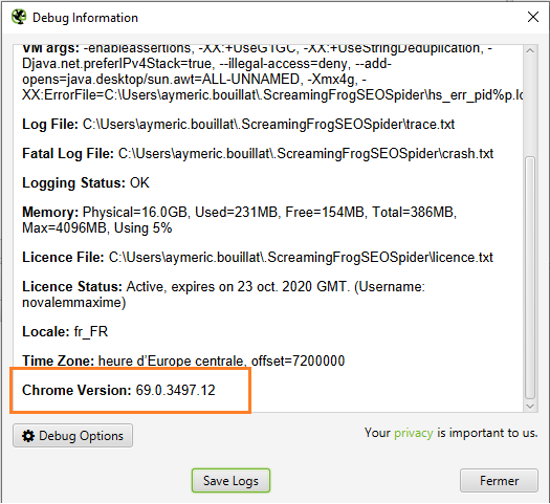
Moteur de rendu utilisé par l'outil
Vitesse
La vitesse du crawler utilise par défaut 5 threads, ce qui équivaut à l’équivalent de 5 onglets Chrome ouverts en simultané pour faire une analogie. En fonction de la configuration de sites (cache, serveur, etc.), cela peut provoquer des surcharges dans certains cas (voire même un blacklistage temporaire). Il est donc possible de limiter le crawl à un certain nombre d’URL par seconde.
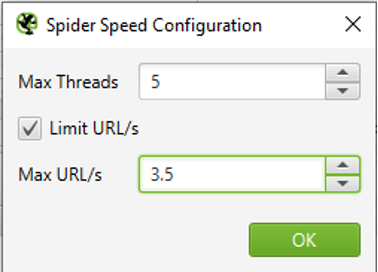
Vitesse du crawl
Quoi qu’il en soit, il est toujours préférable de contacter le responsable de l’hébergement du site pour crawler dans une plage horaire plutôt creuse afin d’éviter de charger le serveur inutilement.
Le fait de fournir le user-agent utilisé ainsi que l’adresse IP de la machine effectuant le crawl pourra permettre un ajout à la withelist à l’hébergeur pour prévenir tout blacklistage ultérieur.
Programmation du crawl
Dans le cas où il serait nécessaire de lancer le crawl en pleine nuit où à un moment spécifique, sachez qu’il est possible de programmer les crawls, et ce de façon régulière également. En ouvrant la fenêtre « Scheduling » du menu « File », vous pourrez ainsi lancer le crawl de façon automatisée. Celui-ci pourra être lancé de façon unique, quotidienne, hebdomadaire ou encore mensuelle, avec la génération d’exports si besoin est, ou encore la génération de fichiers Sitemap automatisée.
En cas de programmation d’un crawl, l’ordinateur devra cependant rester allumé (attention au mode Veille). Il existe également la possibilité de lancer Screaming Frog en mode CLI (Command Line Interface) sans interface graphique, ce qui sera particulièrement utile pour les serveurs exécutant l’application.
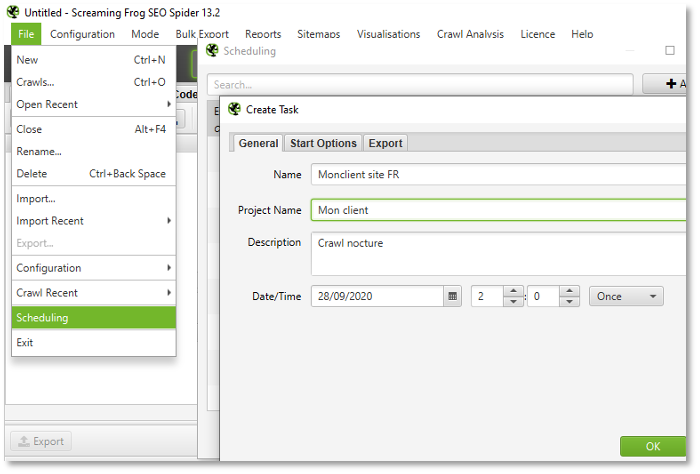
Programmation du crawl
A noter que ce mode est uniquement disponible que l’outil est paramétré en « Storage mode ».
Configuration du crawl et éléments à parcourir
Screaming Frog dispose de nombreuses options dans sa fenêtre de configuration (Menu Configuration > Spider). Parmi les options les plus utiles, on pourrait citer les fonctions suivantes :
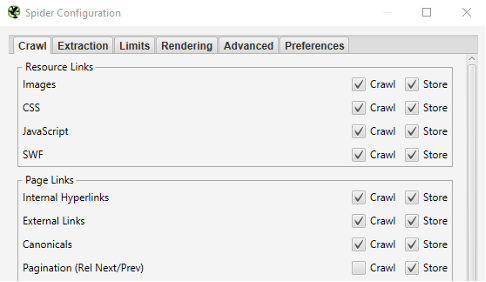
Fênetre de configuration du crawler
- Conserver ou non les relations entre les fichiers via les cases à cocher « Store », sachant que ne pas les enregistrer limitera drastiquement le poids du crawl, mais ne permettra pas de retrouver l’origine des URL découvertes ;
- Récupérer les fichiers sitemaps XML mentionnés dans le robots.txt (ou ajout manuel des sitemaps), via l’option « XML Sitemaps » en bas de l’onglet Crawl. Cela permettra après le crawl de détecter les URL orphelines (URL ne recevant pas de liens mais présentes dans le sitemap) pour ainsi mettre en avant un défaut de maillage interne.
- Respecter ou non la balise noindex (Onglet Advanced), ce qui signifiera que toutes les URL contenant un noindex ne seront pas reportées dans le résultat du crawl. Cela peut être intéressant dans le cas où un site disposerait d’un nombre important d’URL en noindex (ex : moteur à facettes accessible via des liens non bloqués dans le robots.txt).
- Respecter ou non la balise Canonical (Onglet Advanced, ce qui peut permettre d’y voir plus clair dans la duplication de balises <title>. En effet, il arrive souvent que le nombre de balises <title> dupliquées soit relatif avec des URL canoniques vs URL non canoniques.
Eléments à récupérer
Scraping d’éléments On-page (onglet Extraction)
Plusieurs éléments peuvent être récupérés pour chaque URL crawlée par l’outil
Microdonnées
L’utilisation des microdonnées est un vrai plus sur un site Web afin de donner encore plus de contexte à Google sur les entités de recherche, mais également pour bénéficier de résultats enrichis. On notera l’intérêt particulier de récupérer les microdonnées (onglet « Extraction » de la fênetre de configuration) dans cet outil afin de débugger celle qui peuvent être détectées (format Microdata, JSON-LD, RDFa) dans les pages. Les erreurs seront ensuite reportées dans l’onglet de détail de chaque URL :
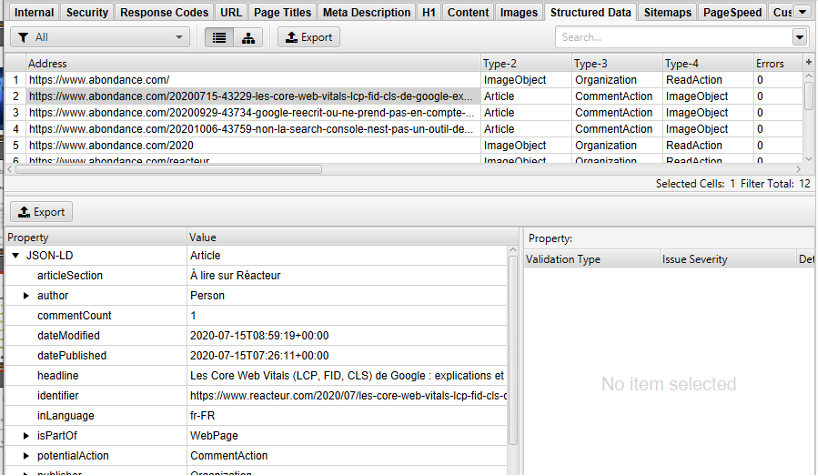
Analyse des microdonnées au format JSON-LD
Code HTML
D’autres éléments peuvent être enregistrés comme l’intégralité du code HTML brut, ou encore le code HTML rendu (après l’exécution du Javascript). Ces 2 options qui se trouvent dans l’onglet « Extraction » de la fenêtre « Configuration > Spider » permettront de faire des nuages de mots-clés relatif aux occurrences les plus fréquentes dans une page de façon ultérieure, ou encore de comparer les différences entre le HTML brut et le HTML rendu :
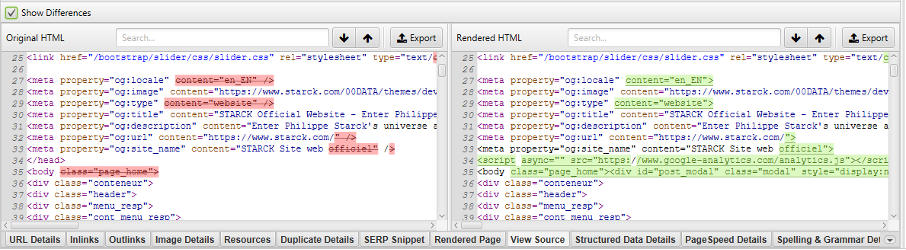
Analyser les différences entre le HTML brut et le rendu JS
Scraping
L’une des fonctions les plus intéressantes de Screaming Frog est relative à la récupération d’éléments spécifiques dans le contenu des pages. Dans le menu « Configuration > Custom », il sera possible de récupérer des éléments dans les pages via les sélécteurs CSS, Xpath ou encore les expressions régulières.
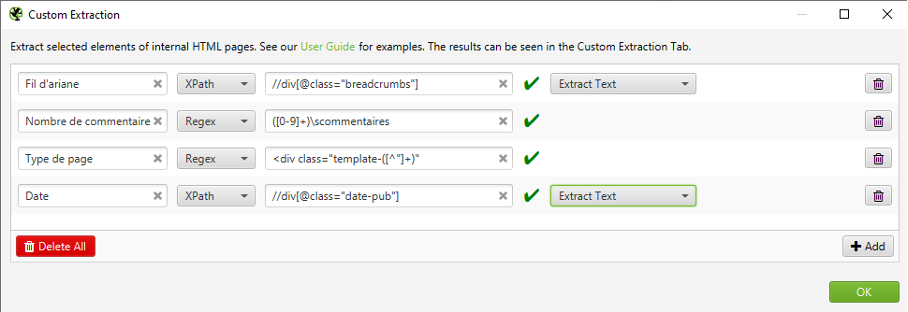
Custom extraction
Parmi les diverses utilisations de cette fonction, on pourra citer :
- L’ extraction du fil d’Ariane pour chaque page ;
- La présence de code tracking pour s’assurer que toutes les pages sont bien tagguées ;
- Le nombre d’avis/commentaires des produits sur un site de e-commerce ;
- La date de publication et/ou l’auteur des articles ;
- Le type de page (édito, listing, galerie, etc.) via les classes CSS ;
- Le nombre de produits dans une liste ;
- Etc.
Emplacement des liens
Une fonctionnalité récente permet d’identifier la position d’un lien par rapport aux balises HTML qui l’englobe. On pourra ainsi vérifier pour le maillage d’une page, l’emplacement des liens vers cette dernière. Cela s’avèrera utile pour mettre en avant des pages maillées uniquement via le menu, le footer, ou encore le contenu central d’une page.
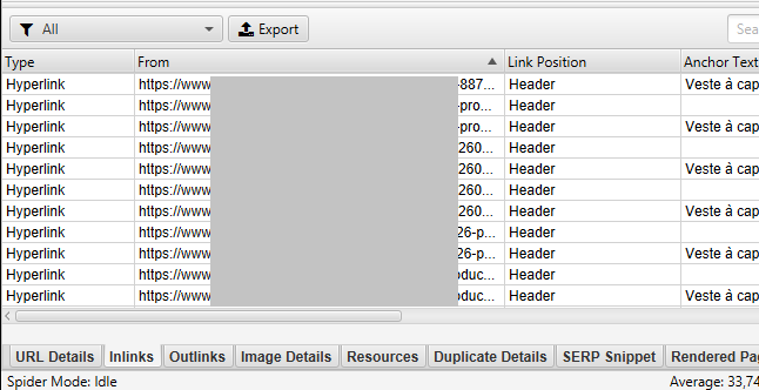
Emplacement des liens relatifs à une URL
Il est possible de configurer en fonction des sites les emplacements des liens par rapport à des balises spécifiques (Menu Configuration > Custom > Link position) :
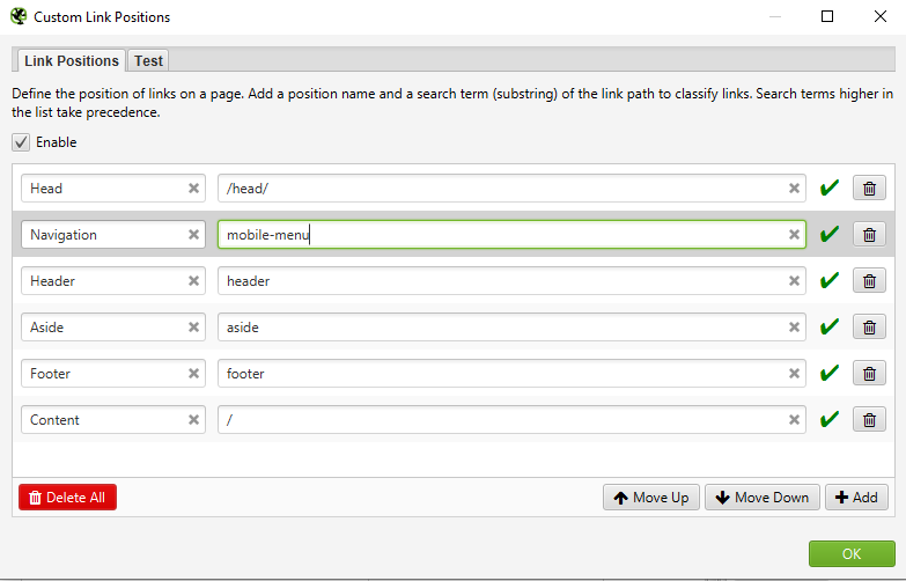
Paramétrage de la fonction "Link position"
Pour cibler un <div> ayant une classe particulière (ex : <div class=mobile-menu>), il est possible d’utiliser directement le nom de la class dans la configuration. Attention, les termes de recherche permettent un classement par ordre d’affichage, il faut donc veiller à utiliser les ciblages les plus larges en bas du tableau (et les plus stricts en haut).
Attention, cette fonctionnalité étant gourmande en ressources lors du crawl, elle peut être désactivée si besoin.
Connexions aux API
Contrairement aux paramétrages qui viennent d’être évoqués, les connexions aux différentes API comme la Search Console ou Google Analytics par exemple, peuvent être configurées après le crawl si nécessaire. En effet, l’onglet API de la colonne de droite de l’outil permet de requêter les API en fonction des URL crawlées a posteriori :
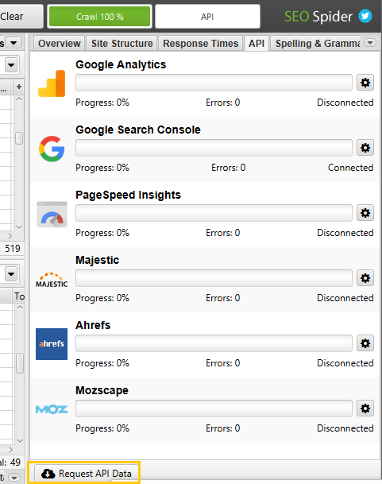
Les résultats se retrouveront ensuite dans des onglets spécifiques :
Onglets relatifs aux API
Restrictions liées aux URL
Respect ou non du robots.txt
En respectant le fichier robots.txt, certaines URL qui ne sont pas encore restreintes dans ce dernier peuvent complexifier le crawl. On peut donc dans ce cas forcer un robots.txt spécifique afin de simuler une configuration future (ou encore écraser le robots.txt d’un site de préprod qui serait en « Disallow:/ ») :
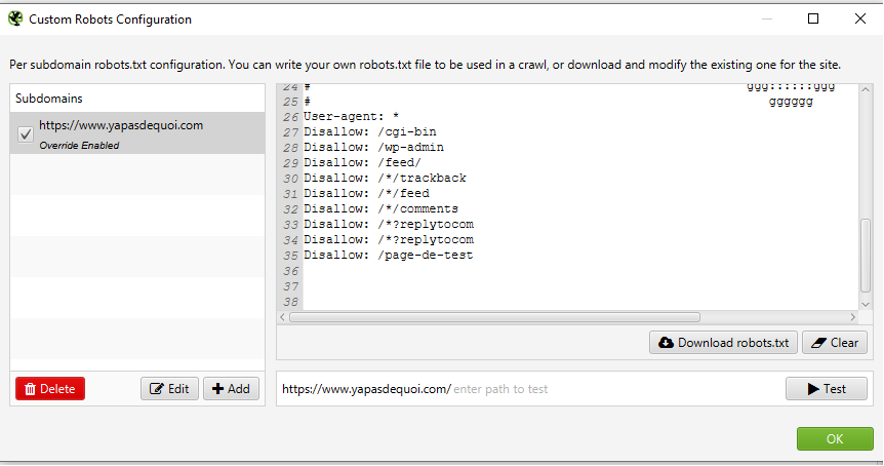
Surcharge du robots.txt
A l’inverse, cette fonction permettra également de rendre crawlable des URL initialement bloquées pour faire des projections sur l’ouverture d’un moteur à facette par exemple.
Réécriture d’URL
Pour aller plus loin dans la manipulation des URL à crawler, notez qu’il est également possible de réécrire des URL à la volée. On pourra supprimer certains paramètres d’URL (ex : URL de tracking interne pour combiner les signaux relatifs au nombre de liens entrants), et effectuer des modifications via des expressions régulières (sur un site de préprod avec des liens vers le site de prod, cela peut s’avérer très pratique).
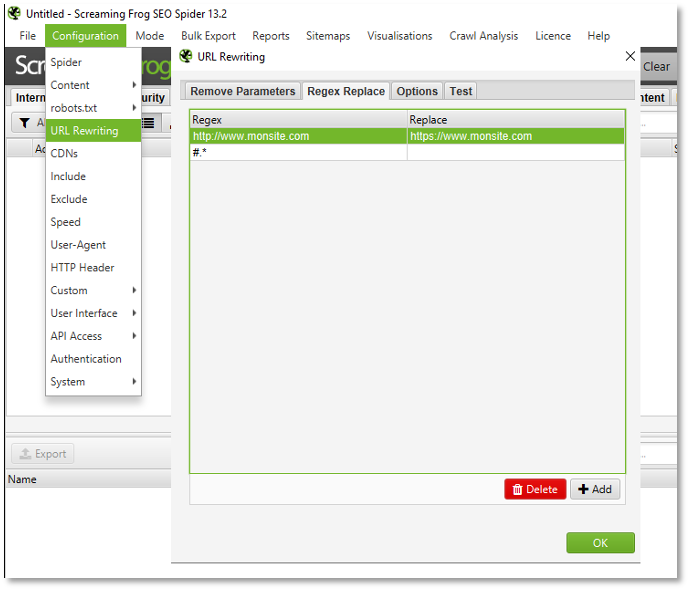
URL Rewriting
Par exemple, pour un site qui contiendrait encore de nombreux liens de la version HTTP vers HTTPS, les redirections 301 de HTTP vers HTTPS pourrait fausser l’interprétation des résultats relatifs aux codes réponse (avec de nombreuses 301 liées à la version HTTP). Vous pourrez donc ainsi faire abstraction de cette problématique (exemple : si les liens sont en cours de modification par les développeurs) en réécrivant les URL à la volée (Menu Configuration > URL Rewriting > Onglet Regexp Replace) :
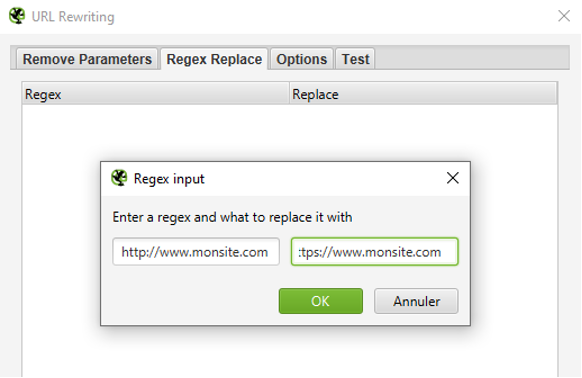
On remplace ainsi toutes les URL découvertes en HTTP par des URL en HTTPS , ce qui permettra d’avoir une bonne vision des codes réponses hormis cette problématique.
Dans le cas d’un crawl avec rendu JS, toutes les URL contenant un # seront crawlées. Les moteurs ne tenant pas compte du hash (#), il sera recommandé dans ce cas de ne pas les crawler pour regrouper les différents signaux Exemple : /url-a#content et /url-a#top pourront être considérés comme une seule et même URL « /url-a » :
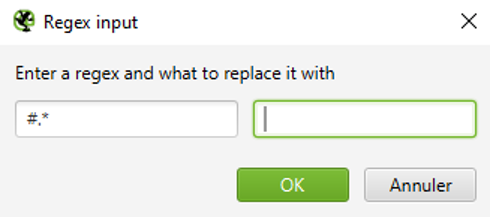
Suppression du hash dans les URL
Sauvegarde de la configuration
Comme vous avez pu le constater, la configuration d’un crawl peut parfois s’avérer complexe, et demande de nombreux réglages préalables. Cette tâche pouvant être fastidieuse, il est heureusement possible de sauvegarder la configuration :
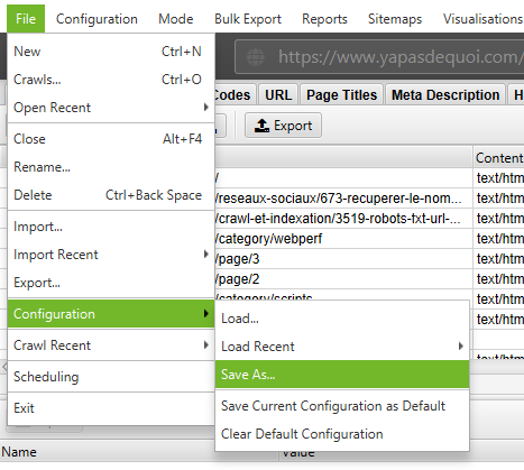
Sauvegarde de la configuration d'un crawl
Avec tout cela, vous devriez maintenant avoir un outil de crawl très bien configuré par rapport à vos besoins. Nous verrons dans le prochain article, le mois prochain, l’utilisation de fonctions d’analyses spécifiques, ainsi que la façon dont les résultats doivent être exploités : l’outil ne fait pas tout, il faut bien savoir interpréter les données ! À très bientôt et bon crawl !
 Aymeric Bouillat, Consultant SEO
Aymeric Bouillat, Consultant SEO