


« Passage Indexing » ou « Passages », selon les noms les plus souvent donnés à ce projet, a fait dernièrement l'objet de plusieurs analyses et commentaires, mais également de nombreux malentendus, la communication de Google à son sujet ayant été plus qu'approximative. Cette faculté de trouver « l'aiguille dans une botte de foin » pour l'algorithme est cependant très intéressante et mérite que l'on se penche dessus avec précision, non seulement pour comprendre de quoi il s'agit, mais également pour dissiper toutes les mauvaises compréhensions que l'on a pu voir à son sujet…
Il faut le dire clairement : Google a passablement foiré sa communication autour du projet "Passage Indexing" (possibilité pour le moteur d'aller chercher une réponse à une requête au sein d'une page qui ne parle pas obligatoirement de ce sujet, mais dont un paragraphe, par exemple, est pertinent par rapport à l'interrogation de l'internaute). Du fait de cette mauvaise communication, on lit et entend tout et son contraire au sujet de cette fonctionnalité depuis quelques temps. Nous avons donc choisi de vous en parler sous la forme d'une FAQ, qui nous a semblé la façon la plus efficace pour traiter toutes les questions que se posent bon nombre de personnes à propos de ce projet. Voici donc les questions les plus fréquemment posées, et leur réponse, au sujet du système de "Passage Indexing" :
Le Passage Indexing, c'est quoi ?
Il s'agit d'un projet annoncé en octobre 2020, qui a pour vocation de mieux comprendre un passage au sein d'une page pour trouver "l'aiguille dans une botte de foin" ou une information pertinente "cachée" dans une page qui ne traite pas obligatoirement de ce sujet. Ce qui peut aider sur des requêtes de longue traîne, très spécifiques et très précises. Le lancement de ce nouvel algorithme avait été annoncé pour novembre 2020, et il était annoncé comme ayant la possibilité d'améliorer 7% des résultats de recherche dans toutes les langues dès le premier jour de sa mise en œuvre.
Pourquoi ce nom ?
Première erreur : le terme "indexing" a été très mal choisi, car il laisse à penser que Google n'indexerait qu'une partie des pages web (celle qui semble intéressante), délaissant le reste du contenu en termes de crawl et/ou d'indexation pure. Or, il n'en est rien : tout le contenu des pages web est indexé, mais il s'agit avant tout de rechercher un "passage" répondant plus spécifiquement à une question très précise. Un nom comme "Passage Analyzing", "Passage Ranking" (idée de Martin Splitt) ou "Passage Identification", par exemple, aurait été plus logique et plus descriptif. D'ailleurs, ce système est désormais souvent appelé "Passages" dans la presse, tout simplement. C'est plus court et cela porte moins à confusion, même si ce n'est pas très descriptif.
Comment les résultats issus de cette analyse seront-ils représentés ?
Deuxième erreur de Google avec, dans son article officiel d'annonce, une illustration qui semblait indiquer que les résultats en Passage Indexing s'afficheraient comme des featured snippets :
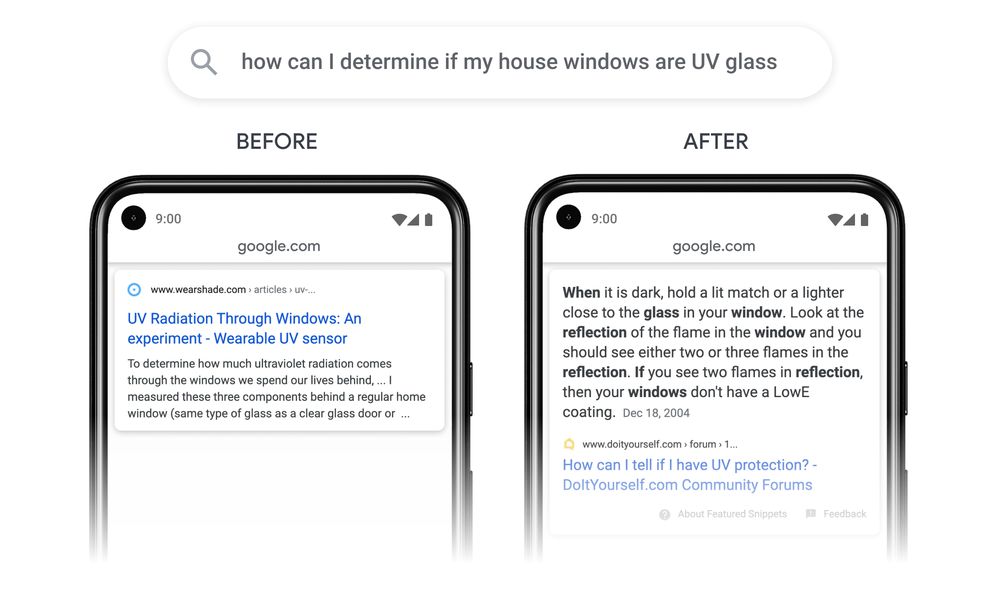
Illustration du Passage Indexing dans l'article officiel d'annonce du projet
Qui plus est, quasiment en même temps, on a vu arriver des featured snippets "new look", avec non plus un encadré gris, mais un trait vertical sur la gauche de la mention "A propos des extraits optimisés" :
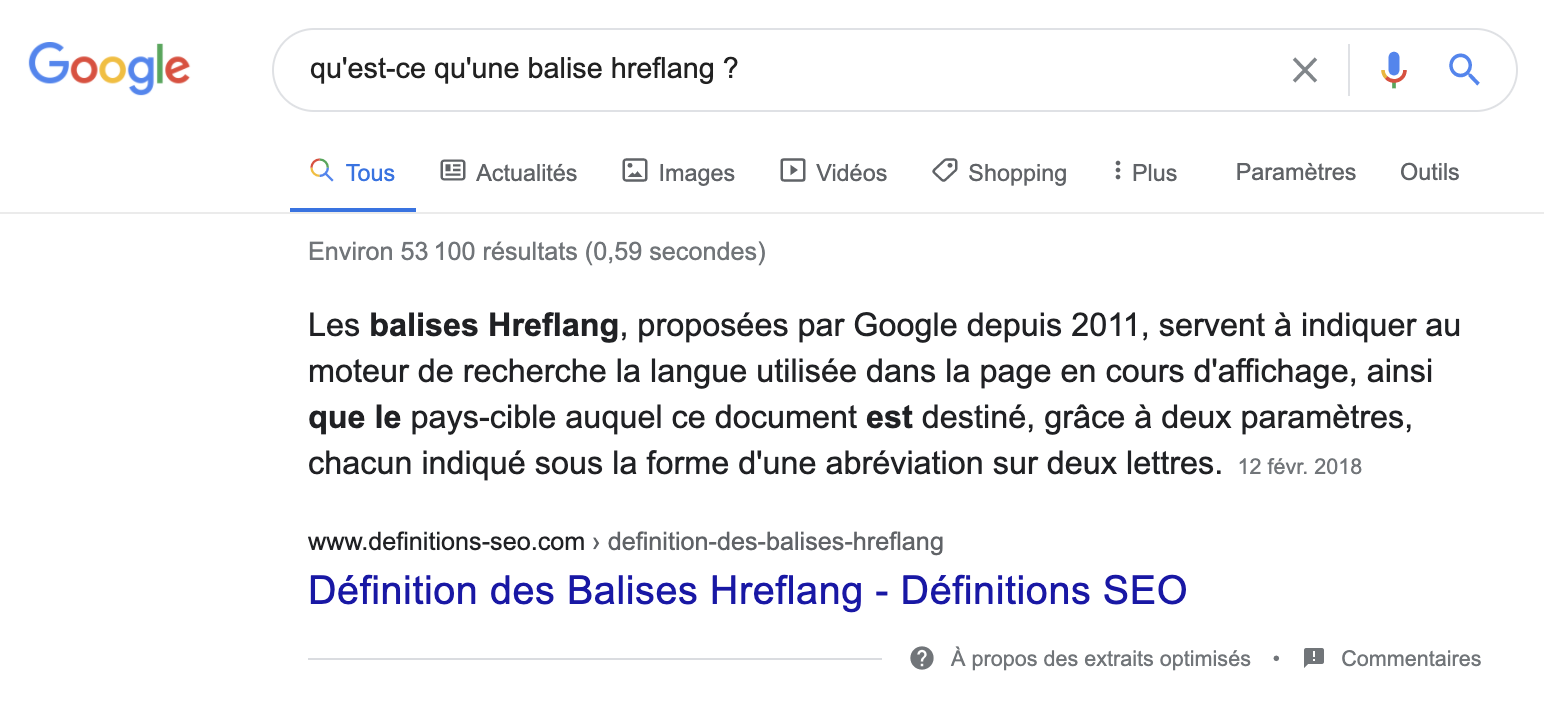
Nouveau test d'affichage des featured snippets
À opposer au look classique des featured snippets (encadré gris autour de la réponse) :
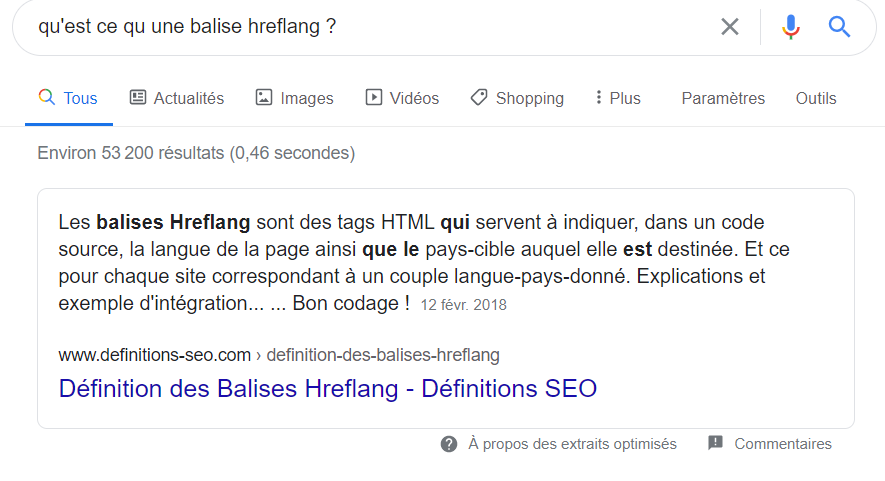
Affichage classique et "historique" des featured snippets
De nombreuses personnes ont donc pensé (et ce n'était pas illogique) que ce nouveau look des featured snippets correspondait aux résultats en "Passage indexing". Et on a plongé aussi chez Abondance dans un article annonçant l'arrivée de ces résultats sur Google France. Mais en fait, il n'en était rien : c'était avant tout un test pour un autre affichage des featured snippets, rien de plus. Les résultats en Passage indexing s'afficheront en fait comme des "liens bleus", dans les résultats de recherche classiques, et rien ne permettra de différencier un lien bleu habituel, classique, d'un lien bleu émanant d'une analyse "Passages". En tout état de cause, ils ne seront pas affichés comme des featured snippets, comme Danny Sullivan l'a confirmé sur Twitter. Et cela a été confirmé par Martin Splitt lors d'un webinar (voir ci-après).
Comment fonctionne Passages ?
Le googler Martin Splitt a également répondu aux questions de 3 SEO anglophones lors d'un webinar de près d'une heure sur le projet Passages.

Webinar consacré à Passages, à l'initiative de Search Engine Journal
Dans ce webinar, certaines informations intéressantes ont été divulguées :
- Selon Martin Splitt, il n'y a rien à faire de spécial sur un site web pour l'adapter à Passages : "C'est un changement qui est purement interne et il n'y a rien que vous ayez à faire, vous n'avez pas besoin d'apporter des modifications à votre site web, vous n'avez pas besoin de modifier vos pages, vos articles ou vos marges. Il n'y a rien de spécial à faire. Il s'agit simplement pour nous de mieux comprendre le contenu d'une page et de pouvoir noter les différentes parties d'une page de manière indépendante."
- Il peut être intéressant d'utiliser les balises Hn pour mieux baliser chaque éléments du contenu de la page : "C'est à peu près ça. Pour tout type de contenu, il faut une certaine sémantique et une certaine structure, de sorte que les systèmes automatisés puissent plus facilement comprendre la structure et le type de contenu, les éléments et les morceaux de votre contenu. Mais même si vous ne le faisiez pas, nous pourrions toujours dire quelque chose comme « cette partie de la page est pertinente pour cette requête alors que l'autre partie de votre page ne l'est pas autant »".
- Martin Splitt a également expliqué qu'il n'était pas réellement concevable qu'une agence SEO propose une prestation spécifique d'optimisation axée sur Passages : "Comment dire ça gentiment... uhm... 🙂 Il y aura probablement des gens qui essaieront d'en tirer profit. Mais je ne tomberais pas dans le panneau. Je pense que le mythe fondamental est de penser que Passages est une "chose" spécifique. Parce qu'en réalité, il s'agit juste d'un petit changement où nous essayons d'aider ceux qui ne sont pas nécessairement familiers avec le SEO ou qui ne savent pas comment structurer leur contenu ou leur stratégie de contenu. Parce que beaucoup de gens finissent par créer ces pages très longues qui ont du mal à se classer pour quoi que ce soit, vraiment parce que tout est tellement dilué à ce long contenu. Nous les aidons avec ce système. (…) Encore une fois, si vous avez un site web qui se classe bien, ce n'est pas vraiment un problème pour vous. Nous n'améliorons le classement que pour les pages qui ont actuellement des difficultés."
En gros, Passages est conçu pour tenter de mettre en valeur des contenus "mal fichus", mal structurés. Mais un contenu clair et mono-concept sera toujours préférable. - Passages s'adapte plus aux contenus rédactionnels de type "article", et impactera certainement assez peu les sites e-commerce.
- Il a donc répété que Passages n'avait aucun rapport avec les Featured Snippets. Dont acte. À ce sujet, Martin Splitt n'était pas certain qu'il serait possible d'observer un classement simultané d'un Featured Snippet et de Passages classés pour le même contenu.
- Il n'y a pas de longueur spécifique (maximale ou minimale) testée pour le contenu textuel pris en compte par Passages : "cela est basé sur ce que l'algorithme détecte et c'est de l'apprentissage automatique (machine learning), donc cela peut changer à tout moment. Et cela peut être très court, aussi court que quelques mots, aussi long qu'un paragraphe, je suppose."
- L'un des SEO a posé la question suivante : Un passage avec la réponse dans le corps du texte peut-il être supérieur – mieux classé - à une page avec la requête dans le titre de la page ? Ce à quoi Martin Splitt a répondu par une question rhétorique, demandant si une page avec une bonne réponse dans le corps du texte est plus pertinente qu'une page avec la requête dans le titre de la page. Bartosz Góralewicz (le SEO) a répondu que s'il devait répondre à la question rhétorique, il dirait que la pertinence est plus importante que la présence d'une phrase de mot-clé dans le titre de la page. Martin Splitt a confirmé par un sourire. 🙂
- Martin Splitt ne savait pas si les textes détectés par Passages seraient surlignés en jaune lorsqu'on va sur la page correspondante, comme c'est le cas avec les featured snippets depuis l'été 2020 (https://www.abondance.com/20200604-42930-google-surligne-le-contenu-des-featured-snippets-dans-les-pages-datterrissage.html).
- Le système Passages sera testé avant son lancement et que lorsqu'il sera lancé, il le sera petit à petit et non pas en une seule fois.
- Il n'y aura pas d'outil de test de Passages accessibles à tous (ce qui semble plus que logique).
- Et Martin Splitt de conclure : "Si vous savez faire du SEO de qualité, le Passage Ranking sera la chose la moins intéressante qui puisse vous arriver." 🙂
Passage indexing a-t-il été lancé comme prévu en novembre 2020 ?
Non, à la mi-janvier 2021 (date à laquelle ces lignes étaient écrites), ce nouveau système n'est pas encore disponible sur le moteur, comme l'a confirmé Danny Sullivan sur Twitter. Aucune date de lancement officiel n'a à ce jour été indiquée.
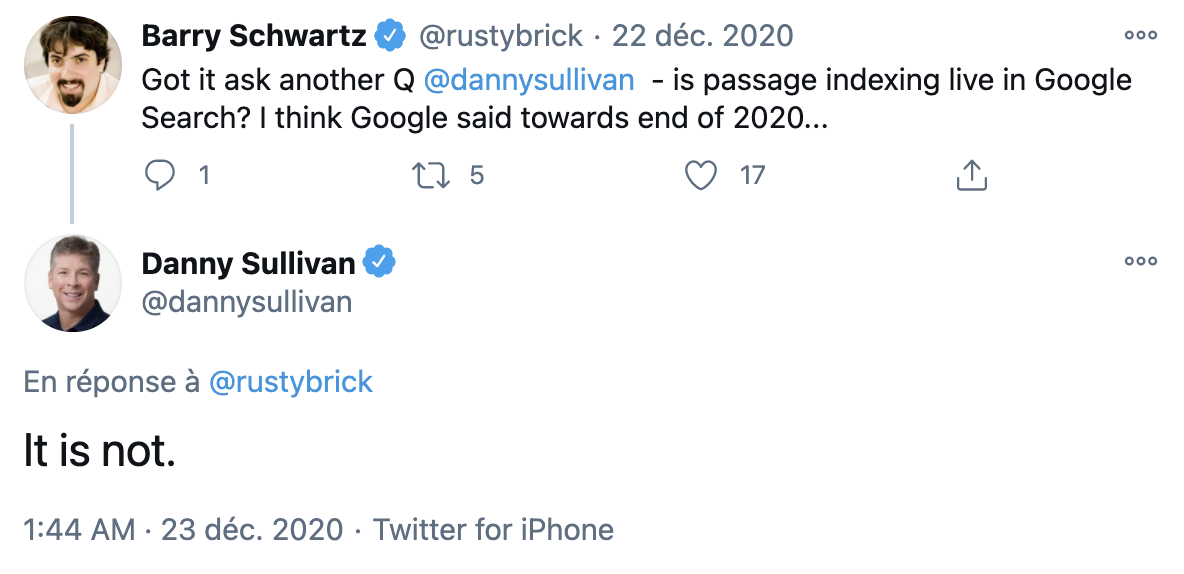
Tweet de Danny Sullivan sur le lancement (attendu) de Passages.
Quels sont les algorithmes utilisés au sein de Passage indexing ?
Pour ce sujet, laissons la parole à Sylvain Peyronnet, spécialiste du domaine : l’annonce de Prabhakar Raghavan sur le passage indexing a fait grand bruit, mais peut laisser de marbre les SEO tant il n’y a pas beaucoup d’information disponible, au delà du “on a fait une amélioration du ranking substantielle, qui va nous permettre de classer des passages de pages et non plus seulement les pages elles-même”.
Pour comprendre tout cela, faisons un petit point technique.
Le premier point est bien entendu de comprendre ce qu’est BERT. BERT veut dire Bidirectional Encoder Representations from Transformers (voir l’article [1] à la fin de l'article), c’est un modèle de la langue qui utilise un mécanisme qu’on appelle l’attention en machine learning pour comprendre les relations entre des mots d’un même contexte (une fenêtre de mots consécutifs, de 512 “tokens” dans la première version de l’algorithme).
Avec BERT on peut faire un vecteur de contexte pour chaque mot d’un texte, ce qui permet de mieux comprendre le sens des mots, entre autres. Le problème, pour un moteur qui doit ensuite évaluer la pertinence par rapport à une requête et classer des pages entre elles, est que pour faire le vecteur d’un long texte, on va faire des moyennes de vecteurs très nombreux, et on va donc diluer la sémantique du texte pour peu que les contextes ne soient pas forcément très “connexes” sémantiquement. Cela peut arriver notamment si des mots sont utilisés de manière pas tout à fait similaire dans plusieurs contextes séparés d’une même page.
Pour pallier ce problème, une solution plus ou moins évidente est de prendre en compte des contextes plus longs. C’est ce que présente l’article [2] (petite digression, vous remarquerez dans les auteurs Mark Najork, pionnier de l’antispam de contenu sur le web) avec SMITH, un algorithme qui utilise des réseaux de neurones jumeaux (on dit “siamese” - siamois - en anglais) pour réussir à calculer l’attention et donc les contextes sur des passages de 2048 tokens. À noter que Google a dernièrement indiqué que SMITH n'était pas à l'heure actuelle lancé dans l'algorithme du moteur.
Mais tout cela ne résout en fait pas du tout le problème de la pertinence par rapport à une requête. Si les moteurs utilisent depuis toujours des variantes de la tf*idf (et en particulier BM25), c’est parce que ces méthodes permettent de comprendre quels sont les termes importants d’un texte, ceux qui vont caractériser réellement la sémantique du texte. Le problème est qu’en ne prenant pas en compte l’interaction d’un terme avec son contexte, ces méthodes historiques ratent une partie de ce qui est important. Pour la petite histoire, en passant, des outils comme yourtextguru et les métamots ont justement développé des méthodes pour éviter cet écueil dans lequel vont tomber ceux qui ne font pas réellement de prise en compte du contexte. Je ferme la parenthèse... 😉
Le buzz du moment se focalise autour d’un nouveau type de méthode, dont la première est deepCT, développé par Zhuyun Dai et Jamie Callan de l’université Carnegie Mellon (cf. article [3]). Zhuyun Dai était doctorante sous la direction de Jamie Callan à l’époque, elle est maintenant chez Google. Indice ? L’idée-clé de cette méthode est que dans un passage, un mot fréquent n’est pas forcément pertinent et il faut donc aller plus loin que la fréquence locale pour estimer l’importance. Une nouvelle fonction de poids appelé tfdeepCT donne un poids de type fréquence biaisée à chaque terme selon son importance dans un modèle contextuel (BERT dans l’article de base, mais cela pourrait être SMITH ou n’importe quel autre algorithme du même type). A partir de cette fonction de poids, Dai et Callan proposent la création d’un index inversé plus efficace qualitativement, et dédié aux passages. Pour rappel, l’index inversé est ce qui prend en entrée un mot ou une requête (par exemple “loutre”) et fournit des pages qui sont en relation avec le mot en question (par exemple des pages qui décrivent la vie des loutres dans la rivière).
BERT est certes utilisé actuellement, mais il n’est qu’un algorithme qui crée des vecteurs, alors que deepCT est une méthode qui utilise ces vecteurs (ou d’autres) pour faire du classement de passages (parce qu’à cause de BERT, cela ne peut traiter que des petits textes), mais dans le futur, sans doute du classement de textes plus longs.
Enfin, la dernière question est de savoir si Google utilise cette méthode. Probablement pas dans la version académique, mais dans l’article [4] ils remercient explicitement Zhuyun Dai pour deepCT qu’ils utilisent pour obtenir les meilleurs résultats pour leur TF-Ranking (TF étant TensorFlow et pas Term Frequency ici). Et une vidéo “documentaire” de Google explique que TF-Ranking est en cours de mise en place (voire déjà intégré, ce n’est pas forcément très clair). L'étau se resserre donc autour de ce type de technologies…
Passage Indexing est-il un système en relation avec le projet "Page Experience" / "Core Web Vitals" ?
Non, aucun rapport avec ces projets (tout comme avec les "core updates" récents) et John Mueller l'a confirmé sur Twitter.
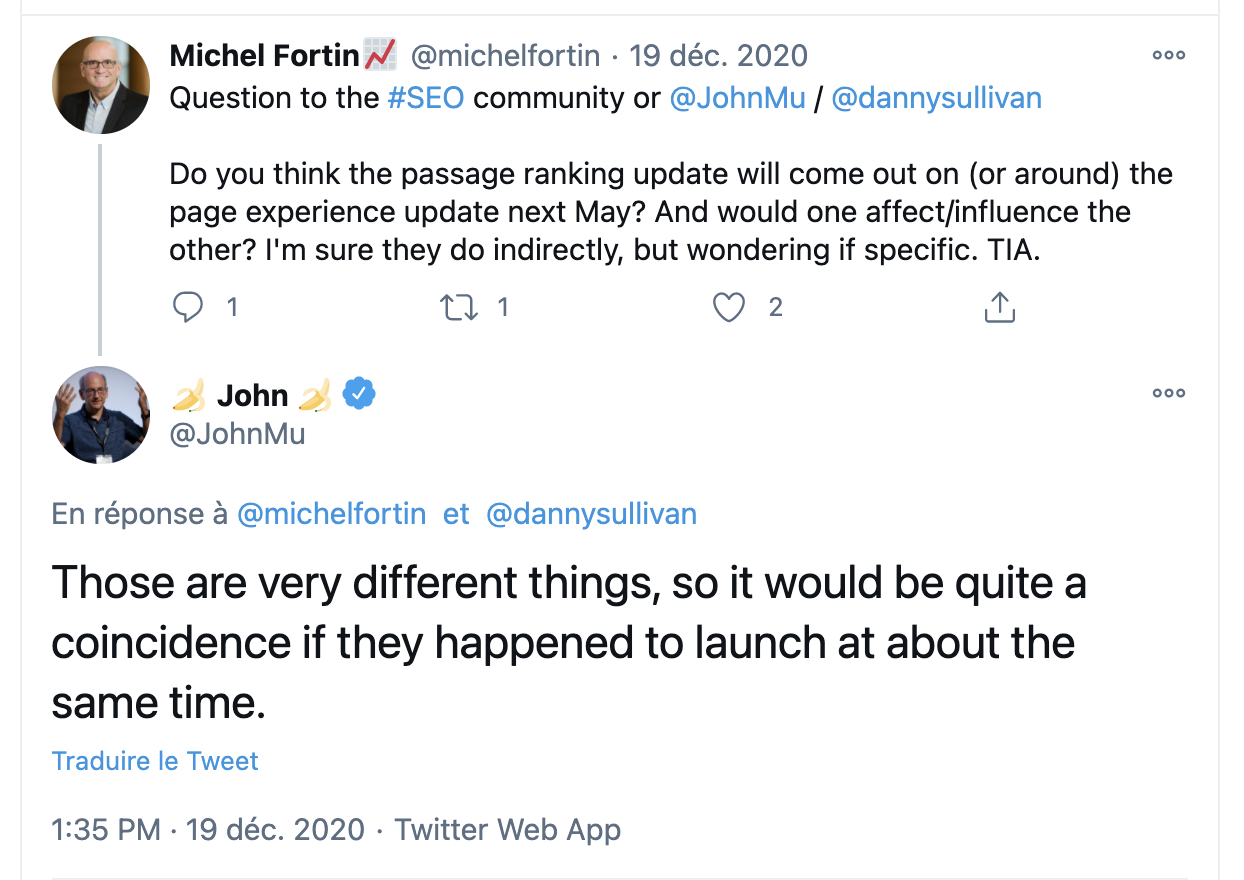
Tweet de John Mueller sur Passages et Core Web Vitals / Page Experience
Idem avec les sous-thématiques, projet mis en place depuis novembre 2020. Ce sont des sujets, projets et algorithmes différents. Lors du webinar organisé par Search Engine Journal, Martin Splitt a expliqué que les sous-thématiques étaient une façon de comprendre les requêtes et Passages une question de classement. Les deux sujets sont dissociés.
Conclusion : Passages, une solution avant tout tournée vers les pages web mal structurées
Lors du webinar organisé par Search Engine Journal, Martin Splitt a finalement bien résumé la situation en expliquant que si vous avez un site web sur les légumes et que celui-ci propose une page d'explication par légumes, aucun problème, vous n'aurez pas "besoin" de Passages pour obtenir de la visibilité. Mais si une page unique parle de TOUS les légumes, il est important pour Google de détecter dans ce contenu les informations spécifiques aux tomates, aux poireaux ou aux courgettes. Car elles peuvent répondre à certaines requêtes spécifiques au sujet d'un de ces légumes, de façon précise. Et c'est à ce moment-là que Passages entrera en lice. Mais si vous avez un site web bien conçu en termes de SEO, il y a de fortes chances pour que Passages soit le cadet de vos soucis... 😉
Références
[1] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Jacob Devlin, Ming-Wei Chang, Kenton Lee, et Kristina Toutanova.
https://arxiv.org/abs/1810.04805
[2] Beyond 512 Tokens: Siamese Multi-depth Transformer-based Hierarchical Encoder for Long-Form Document Matching. Liu Yang, Mingyang Zhang, Cheng Li, Michael Bendersky, et Marc Najork.
https://arxiv.org/abs/2004.12297
[3] Context-Aware Sentence/Passage Term Importance Estimation For First Stage Retrieval.
Zhuyun Dai et Jamie Callan.
https://arxiv.org/abs/1910.10687
[4] Learning-to-Rank with BERT in TF-Ranking. Shuguang Han, Xuanhui Wang, Mike Bendersky, et Marc Najork.
https://arxiv.org/abs/2004.08476

![]() Olivier Andrieu Rédacteur en chef de la lettre Réacteur, avec l'aide de Sylvain Peyronnet, concepteur de l'outil d'analyse de backlinks Babbar.
Olivier Andrieu Rédacteur en chef de la lettre Réacteur, avec l'aide de Sylvain Peyronnet, concepteur de l'outil d'analyse de backlinks Babbar.

 de nous rejoindre
de nous rejoindre