

Le netlinking est une activité très chronophage, chacun en conviendra. Mais la notion de temps passé n'est pas la seule à devoi rêtre prise en compte. La sémantique, et notamment le concept de glissement sémantique est également très importante pour obtenir des liens de qualité, faisant intervenir le célèbre surfeur aléatoire du PageRank de Google de façon efficace. Et dans ce cas, la structure et le contenu sont aussi important que la présence même des backlinks...


 Par Guillaume Peyronnet, Sylvain Peyronnet et Thomas Largillier
Par Guillaume Peyronnet, Sylvain Peyronnet et Thomas Largillier
Avant l’été, nous avons eu l’occasion de voir comment fonctionnait en détail un moteur de recherche moderne. Il est maintenant temps de voir comment profiter de cette connaissance pour réussir à mieux se positionner dans les résultats, les fameuses SERP.
Vous le savez déjà, les deux leviers les plus importants pour le moteur sont le contenu des pages (de l’aveu même de Google, content is king) et les liens qui sont faits depuis des sites tiers vers vos pages.
Il existe actuellement de nombreuses techniques de structuration du contenu qui sont faites soit en interne d’un site (silos, cocon sémantique, etc.) soit en externe (on parle maintenant de PBN pour Private Blogs Network, mais auparavant on faisait tout simplement des réseaux et des pages satellites). Dans cet article, nous ne discuterons d’aucun formalisme, aucune méthode. Nous allons tout simplement voir ce qu’il est important de prendre en compte, pour que chacun puisse se construire la pratique qui lui convient, car c’est d’abord cela une meilleure pratique…
Le moteur, c’est lui qui dicte les règles, pour le pire et le meilleur
Nous allons partir du principe que vous avez une seule page importante à positionner. Nous ferons par ailleurs l’hypothèse que cette page est une page très commerciale (par exemple une page de conversion dans une thématique très concurrentielle). Par essence, même si le contenu de cette page est très pertinent pour votre requête, il sera difficile d’obtenir de beaux backlinks et au final vous aurez du mal à obtenir des positions. Une stratégie bien réfléchie, mixte en terme de liens et de contenu, vous permettra de pallier ce problème.
Voyons maintenant les primitives du moteur qu’il faut garder à l’esprit.
- Le modèle de la pertinence/similarité est un modèle vectoriel. Un moteur détermine que deux pages sont similaires lorsqu’elles utilisent globalement les mêmes mots de la même manière (dans ce cas, n’importe quelle fonction de poids, telle que la TF.IDF, associée à un cosinus de Salton ou équivalent, jugera que les pages sont proches).
- Le PageRank est une propriété du surfeur aléatoire. Il est donc important de créer des maillages qui font circuler le surfeur aléatoire. Nous avons déjà évoqué dans ces pages qu’il fallait réaliser des boucles qui circulent autour et à travers des pages importantes de son site. C’est une bonne pratique qu’il faut respecter de manière globale.
- Le PageRank est thématique. Les travaux de Taher Haveliwala (d’abord chez Kaltix, puis Google à partir de 2003, voir [1]) sont fondateurs dans ce cadre. Le PageRank thématique impose que des pages liées entre elles soient en adéquation thématique (pas pertinente pour la même requête, mais appartenant au même thème) pour que le PageRank passe de l’une à l’autre.
- Les liens externes ont plus de valeur que les liens internes. C’est Brian Davison qui le prouve dans l’article [2] : un moteur a des résultats plus qualitatifs lorsque l’on décote les liens internes (entre pages d’un même domaine) par rapport aux liens externes.
Cette décote n’a pas d’importance dans un maillage sans aucun liens sortants, mais dans le cas contraire, cela signifie que le PageRank va principalement “fuiter” vers des sites tiers.
Une fois que l’on a toutes ces primitives à l’esprit, que faut-il faire ?
Les bonnes pratiques de maillage et de contenu
Le premier point clé que nous souhaitons mettre en avant est le suivant : pour avoir plus de visibilité, nous allons augmenter la surface “d'atterrissage” de notre écosystème (notez que nous n’avons pas écrit "site", nous y reviendrons plus tard). Pour cela, il faut générer des pages qui sont compatibles sémantiquement avec notre page principale. Nous sommes là dans une logique que l’on retrouve dans les silos et dans le concept du cocon sémantique.
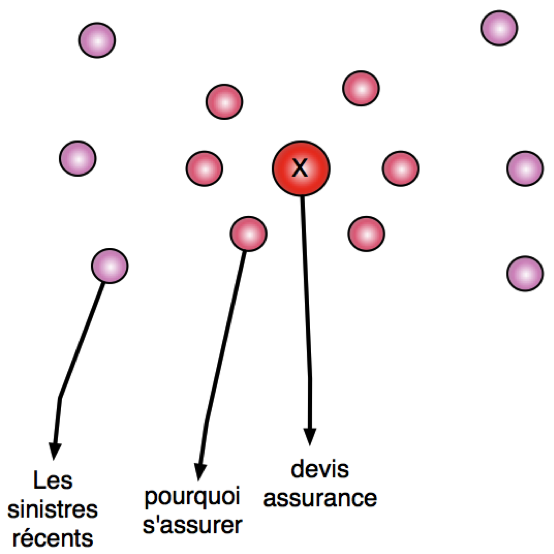
Il faut que ces pages soient compatibles, mais aussi qu’elles ne parasitent pas la page principale, qu’elles fassent entonnoir de conversion en raffinant l’intention. La notion clé ici est de comprendre les intentions, mais aussi de pratiquer un glissement sémantique depuis la frontière de ces pages jusqu’à la page principale.

Fig. 1. La notion de glissement sémantique.La figure 1 illustre grossièrement la notion de glissement sémantique : la page principale sera par exemple une page permettant de demander un devis d’assurance, mais plus on s’en éloigne, plus l’intention et le sujet sont larges, tout en restant compatible avec la thématique de l'assurance.
Trouver les intentions plus larges (souvent informationnelles) est la tâche la plus difficile. De nombreux outils permettent de le faire (on parle souvent de d’outils de suggestion de questions), notre but n’est pas de les lister ici (nous en oublierons), mais vous pourrez facilement les trouver via la lettre ou sur abondance.com.
Un point important est ensuite de savoir quels termes il faudra écrire sur chacune des pages pour assurer un glissement sémantique optimal. Une astuce de rédaction est d’utiliser un outil sémantique. Nous sommes auteurs de l’un d’entre eux (yourtext.guru), nous nous baserons donc sur celui-ci pour la suite.
Pour chaque intention, on va utiliser l’outil pour trouver le champ lexical associé, et on va ensuite voir quelles sont les pages avec les champs lexicaux les plus proches, et c’est ces pages qui vont ensuite être mises en relation.
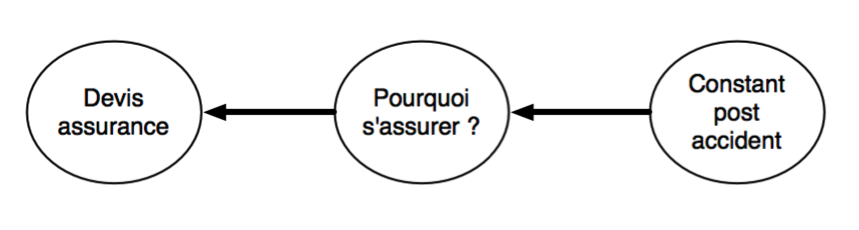
Reprenons l’exemple de l’assurance. Notre requête principale est “demander un devis d’assurance”, et selon yourtext.guru le champ lexical comporte comme top termes : assurance, auto, devis, ligne, véhicule, contrat, garanties, assureur, voiture, offres, etc.
Une requête plus large possible est “pourquoi s’assurer”, une autre est “faire un constat pour l’assurance après accident”. La première requête possède comme top termes une partie de ceux de la requête sur le devis, ainsi que des mots différents : pourquoi, responsabilité, dommages, etc. La deuxième est plus éloignée avec des mots plus spécifiques : sinistre, indemnisation, recours, police, dégats, circonstances, victime, lieu de l’accident, dépanneuse, etc.
Un linking entre les pages pour ces requêtes serait donc celui visible dans la figure 2.
Fig. 2. Linking avec glissement sémantique.L’avantage de ce schéma est que l’on va rapidement vers des pages suffisamment informationnelles pour que les backlinks affluent naturellement. C’est l’avantage de la structuration sémantique et du travail sur le glissement d’intention : il permet de faciliter le netlinking.
Mais cela ne suffit pas…
Ce qui a été dit précédemment est un très bon début, mais cela ne suffit pas. En effet, une fois qu’on aura acquis du PageRank grâce à des pages avec une intention plus large, mais suffisamment proche thématiquement pour ne pas casser le flux du PageRank thématique, il faudra garantir une amplification maximale.
Pour cela, il suffit de créer des boucles qui passent périodiquement par la page principale de notre structure. Ainsi le surfeur aléatoire reviendra souvent sur la même page, qui sera donc boostée en terme de popularité au niveau du moteur. Avec un bon contenu et une bonne popularité, elle sera bien positionnée, et en plus au coeur d’un entonnoir de conversion ad-hoc, ce qui semble être le mieux qu’on puisse faire.
Pourtant, on peut faire encore un peu plus !
Il faut pour cela se rappeler du dernier point important : les liens internes ont moins de valeur que les liens externes. Il va donc falloir être rusé dans le linking “interne” que l’on est en train de créer. Le lecteur avisé aura remarqué que nous avons précédemment utilisé le mot écosystème plutôt que celui de site, ce n’est pas par hasard.
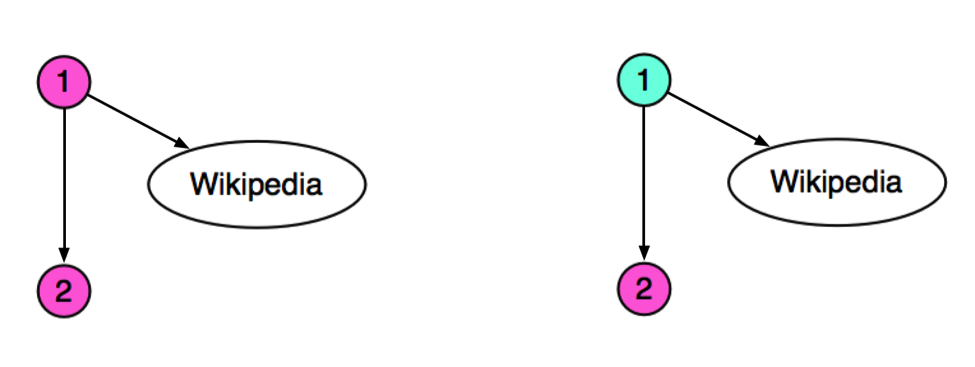
Structurellement, pour pousser au maximum la page principale, il faut une structure avec une forme de fermes de liens, et si on la veut plus discrète, une forme de spirale avec des “raccourcis” paraît tout aussi adaptée. Mais il faut faire attention à la gestion des pages avec des liens vers l’extérieur. Dans l’idéal, ces pages ne doivent pas faire partie du même site que la page suivante dans la structure que nous avons construit. La figure 3 est édifiante à ce titre.

Fig. 3. Attention à ne pas mettre tous ces liens dans le même site.On a ici deux pages d’un même site, avec la page 1 qui pointent vers la page 2 et vers wikipedia. Même si les deux pages ont exactement la même thématique, la page 2 recevra moins de 10% du PageRank de la page 1 à cause de l’amortissement de transmission entre pages d’un même site. A droite, les deux pages sont sur des sites différents et donc la page 2 recevra un peu plus de 40% du PageRank de la page 1. Bien sûr le chiffre de 10% est illustratif, on ne connaît pas la décoté exacte effectuée par les moteurs.
En revanche, si une page n’a pas de liens vers l’extérieur, on peut sans aucun problème la maintenir sur le même site. Et plus globalement, on ne peut pas non plus mettre une page sur deux sur un domaine différent pour optimiser la transmission, cela ne serait pas très discret. 😉
Pour conclure
Lorsque l’on comprend bien les briques de base utilisées par les moteurs de recherche, on voit assez facilement qu’il existe un moyen d’améliorer son netlinking grâce à des pages qui ne sont pas nécessairement celles que l’on va positionner, mais qui vont servir de réceptacle à des liens naturels. Il s’agira ensuite tout simplement de guider le PageRank (en fait le surfeur aléatoire thématique) via des canaux sémantiques bien choisis, avec des sauts de sites en sites, sur un même écosystème.
Au final, et pour être un peu provocant, la meilleures stratégie est peut-être un mix entre réseau, cocon et silos.Références
[1] Haveliwala, T. H. (2003). Topic-sensitive PageRank: A context-sensitive ranking algorithm for web search. Knowledge and Data Engineering, IEEE Transactions on, 15(4), 784-796.
http://ilpubs.stanford.edu:8090/750/1/2003-29.pdf[2] Lan Nie, Brian D. Davison, and Xiaoguang Qi. 2006. Topical link analysis for web search. In Proceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval (SIGIR '06). ACM, New York, NY, USA, 91-98. DOI=http://dx.doi.org/10.1145/1148170.1148189
 Thomas Largillier, Guillaume Peyronnet et Sylvain Peyronnet sont les fondateurs de la régie publicitaire sans tracking The Machine In The Middle (http://themachineinthemiddle.fr/).
Thomas Largillier, Guillaume Peyronnet et Sylvain Peyronnet sont les fondateurs de la régie publicitaire sans tracking The Machine In The Middle (http://themachineinthemiddle.fr/).

 de nous rejoindre
de nous rejoindre