

Google utilise des robots pour explorer un site web de la façon la plus efficace possible. Mais il limite ses ressources de façon différente pour chaque site web. Il est donc important d'affiner ce travail, en montrant à Googlebot vos meilleures pages en priorité et en faisant le "ménage" dans votre arborescence pour séparer le bon grain de l'ivraie. Voici donc une somme de conseils bien utiles pour optimiser votre budget crawl pour les moteurs de recherche...
 Par Daniel Roch
Par Daniel RochLa notion de « crawl budget » est importante en référencement naturel, et c’est un sujet de plus en plus abordé dans la communauté des référenceurs en France et dans le monde. Le souci principal est que cette notion est parfois assez vague.
Nous allons donc voir en détail en quoi consiste ce « budget crawl » chez Google, son impact réel sur le référencement naturel d’un site et surtout comment en tirer profit dans une stratégie SEO.
Qu’est-ce que le crawl ?
Commençons par le départ : qu’entend-on par crawl exactement ?
Pour pouvoir proposer des résultats aux internautes, Google doit avant tout connaître le détail des pages de chaque site. Pour cela, il a développé des robots qui lui permettent de parcourir le Web, c’est-à-dire de faire ce fameux crawl, et donc l'exploration des sites web, pages par pages. Ses robots s’appellent GoogleBot, et le moteur de recherche en a créé plusieurs en fonction du type de contenu ou de résultat qu’il avait besoin de trouver et de proposer aux internautes. On retrouve ainsi :
- GoogleBot : pour la plupart des contenus web ;
- Googlebot-News : pour crawler des URL pour les résultats de type « actualité » ;
- GoogleBot-Image : pour crawler des URL de type Image ;
- GoogleBot-Video : pour crawler des URLde type Vidéo ;
- Mediapartners-Google : pour les sites utilisant Adsense pour générer des revenus publicitaires ;
- Adsbot-Google : pour les sites utilisant Adwords pour attirer du trafic supplémentaire ;
- Etc.
Source : https://support.google.com/webmasters/answer/1061943?hl=fr
Ce crawl s’effectue en quasi temps réel. Google parcourt ainsi des millards de pages par jour(20 milliards de sites quotidiennement) afin de proposer des résultats pertinents aux internautes. Vous pouvez d’ailleurs constater vous-même le crawl de Google sur votre site avec le menu « Exploration > Statistiques sur l’exploration » de la Search Console de Google (https://www.google.com/webmasters/tools/).
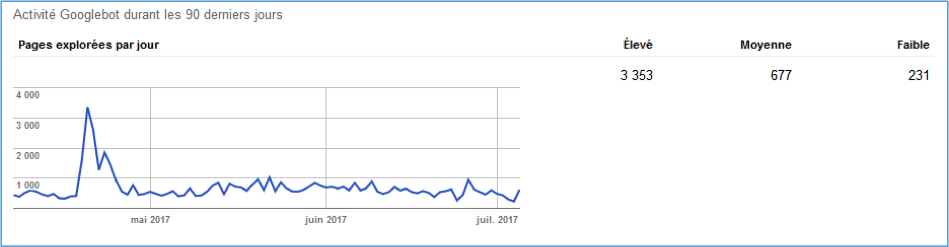
Fig. 1. Des statistiques sur le crawl de Google sur votre site
La notion de budget de Crawl chez Google
En Janvier 2017, Google a voulu clarifier le concept de « budget de crawl » car de nombreux sites parlaient de ce concept mais n’avaient tous pas tous une définition commune (source). Derrière ce terme, il existe en réalité deux aspects différents :
Le Crawl Rate
Le taux de crawl représente le nombre d’URL que Google peut crawler de manière simultanée. L’objectif de Google est de pouvoir analyser le plus grand nombre d’URL possible de chaque site web, sans pour autant dégrader l’expérience utilisateur des internautes qui naviguent sur ces derniers (et donc les ressources des serveurs). Google se définit d’ailleurs comme « Un bon citoyen du Web » quand il parle de cet aspect.
Cette limite du crawl de chaque site est très variable. Par défaut, tout site web possède le même taux de crawl lors de sa création. Ensuite, Google va augmenter ou diminuer cette limite en fonction de plusieurs paramètres dont nous parlerons en détail plus loin dans cet article, et dont voici le résumé :
- La « santé » du site qui est crawlé (vitesse de chargement, erreurs, etc.) ;
- L’éventuelle limite définie manuellement dans la Search Console de Google.
Remarque : cela veut notamment dire que sur un nouveau nom de domaine il est déconseillé de publier trop de contenu au démarrage car Google mettra du temps pour les crawler et les indexer.
Le Crawl demand
Deuxième aspect, le « besoin » de crawler ou non votre site entier (ou certaines URL de ce dernier). Google va ainsi venir plus ou moins souvent en fonction de nombreux critères que l’on peut également résumer ainsi :
- La popularité. Plus un site ou une page est populaire (PageRank), plus Google aura tendance revenir rapidement ;
- La fraicheur : Google essaie de vérifier si les URL d’un site n’ont pas été modifiées, le tout afin de toujours proposer aux internautes des résultats à jour. Si vous publiez souvent, Google reviendra également à une fréquence plus élevée ;
- Des évènements ponctuels qui pourraient augmenter temporairement la demande de crawl d’un site (changement de nom de domaine, piratage, refonte du site, passage en HTTPS, etc.).
En résumé, le budget de crawl au sens large se définit par une simple phrase : c’est le nombre d’URL que Google va pouvoir et vouloir explorer sur votre site chaque jour.
Qu’est ce qui impacte le budget de crawl ?
Essayons d’abord de comprendre ce qui peut impacter à la hausse ou à la baisse ce budget de crawl. Comme expliqué, tout nouveau nom de domaine se voit attribuer par Google une limite de crawl par défaut. Ce n’est qu’après avoir analysé le site que Google va ensuite décider d’augmenter ou de diminuer cette limite.
Google indique ainsi que ce qui impacte en premier lieu cette limitation sera les URL de faible qualité, et notamment :
- La navigation à facette (c’est-à-dire des URL avec des paramètres) ;
- La duplication de contenu ;
- Les pages en erreur (ou en soft 404, c’est-à-dire des pages considérées par Google comme étant des erreurs même si elles n’en sont pas réellement) ;
- Les URL piratées ;
- Les contenus peu pertinents ou les contenus considérés comme du spam ;
- Et tout autre problème technique (redirections multiples, mauvaises balises canoniques, etc.).
Quel impact le crawl peut-il avoir sur le référencement naturel ?
Selon Google, la plupart des référenceurs n’auraient pas à se soucier de cette problématique et seuls les gros sites ou les sites ayant une génération automatique d’URL devraient s’en soucier (source). Pourtant, le budget de crawl peut avoir un impact positif, quelle que soit la taille de votre site.
Le fait que Google revienne crawler vos pages de manière plus ou moins assidue peut avoir plusieurs impacts positifs ou négatifs :
- Le moteur de recherche peut trouver plus rapidement vos nouvelles publications ;
- Google peut comprendre et prendre en compte les contenus qui ont été mis à jour, déplacés, ou supprimés ;
- Il peut également passer du temps sur les pages réellement importantes de votre site, ou à l’inverse sur des pages secondaires ou inutiles en référencement (comme vos mentions légales par exemple, voire de vieilles URL que vous avez oubliées mais qui sont toujours en ligne).
L’idée est donc de mesurer la façon dont Google parcourt votre site pour savoir si oui ou non vous devez améliorer votre site pour mieux mettre en avant vos pages principales.
Comment mesurer le crawl de Google ?
Le menu de la Search Console
La première étape pour le mesurer est de regarder les statistiques globales de crawl via le menu dédié de la Search Console dont nous avons déjà parlé. On peut ainsi voir la fréquence globale de crawl du site comparée au nombre de contenus que l’on possède réellement.
On peut aussi voir grâce à cela si un évènement a provoqué une forte baisse ou hausse de ce crawl, comme dans l’exemple suivant où le site web a basculé en HTTPS (Google crawle alors de nouveau tout le site) :
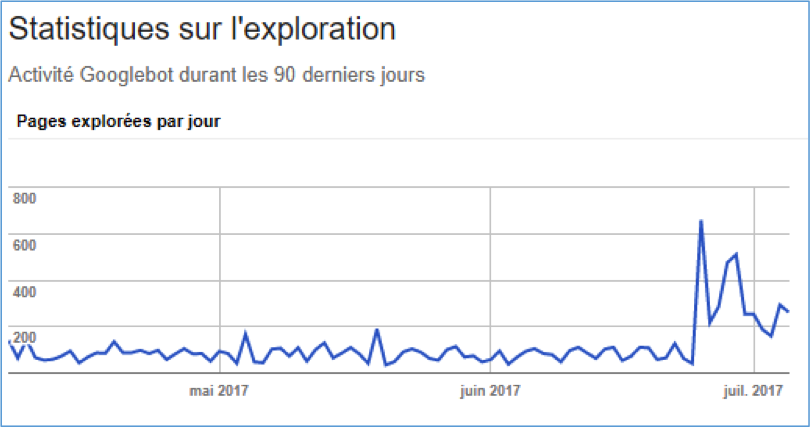
Fig. 2. Un exemple de modification visible d’une fréquence de crawl
Mesurer en PHP
Deuxième méthode : mesurer en PHP les visites de Google. Il est ainsi facile de développer un petit script PHP (ou dans tout autre langage d’ailleurs) pour mesurer le passage de Google Bot sur chacune de vos URL.
Par exemple, la variable serveur $_SERVER['HTTP_USER_AGENT'] peut permettre de savoir si le visiteur est un robot. On peut ensuite passer cette variable dans notre base de données pour mesurer chaque visite de Google.
Sachez cependant que cette technique a de nombreux défauts :
- On ne peut mesurer le passage de GoogleBot si la page a été mise en cache ;
- Il faut développer son propre script pour pouvoir capter cette information ;
- Cela ne fonctionne que pour vos contenus HTML. Cela ne peut fonctionner pour mesurer le reste du crawl de Google (fichiers JS et CSS, images, vidéos, etc.).
Les logs pour mesurer le crawl
Il s'agit sans doute ici de la meilleure solution : utiliser les logs de son serveur web pour mesurer l’intégralité du crawl de Google. La plupart des outils payants sur ce sujet (comme par exemple Botify) utilisent d’ailleurs ces fichiers car ils sont de très loin la source la plus fiable pour mesurer le passage de GoogleBot sur son site.
Pour faire cela, il suffit de consulter la page d’aide de votre hébergeur qui vous indiquera l’emplacement où vous pourrez télécharger ces fichiers de logs. Chez certains hébergeurs, ce sera via votre accès FTP, pour d’autres ce sera possible au travers d'un menu dédié dans l’interface d’administration de votre serveur.
Une fois téléchargé, vous aurez un fichier dont le contenu ressemble à celui de la figure 3.

Fig. 3. Un exemple de fichiers de logs pour l’hébergeur Infomaniak.
Vous obtenez ainsi la liste de chaque appel d’URL sur votre site, que ce soit un robot ou un visiteur réel qui la demande. Cela inclut donc tous vos contenus HTML, mais également les autres types de contenus comme les flux RSS, les images, les vidéos, les fichiers CSS, etc.
L’idée ici est d’importer ces données dans un logiciel dédié, ou bien tout simplement dans Excel, puis de filtrer les données. Votre objectif est alors de décomposer ces logs pour pouvoir filtrer uniquement les URL appelées par Google. Dans notre exemple de logs venant de l’hébergeur Infomaniak, chaque ligne se décompose des éléments suivants :
- Le nom de domaine ;
- L’IP de l’utilisateur ou du robot ;
- La date et l’heure de passage ;
- Le type de requête (GET ou POST) ainsi que l’URL demandée ;
- Le protocole HTTP utilisé et l’entête renvoyé par le serveur ;
- Le détail de l’user-agent (c’est ici que l’on saura s’il s’agit de GoogleBot ou non).
Remarque : attention, une tierce personne peut potentiellement se faire passer pour Google. Pour être sûr que ce n’est pas le cas, il vous suffit de suivre ce guide officiel : https://support.google.com/webmasters/answer/80553?hl=fr. Certains sites essaient aussi de lister pour vous les adresses IP réellement utilisées par les robots de Google, comme ici : http://www.lightonseo.com/moteurs-de-recherche/1181-1226-liste-ip-googlebot/
Une fois votre tri réalisé dans Excel, il vous suffit alors de regarder quelles sont les pages qui ont été les plus crawlées par Google sur une période de temps précise, et de vérifier si les pages principales sont bien en tête de liste et les pages peu pertinentes en dernier.
Si l’on prend pour exemple une analyse de logs sur un petit site pendant une journée, en voici les résultats : 467 URL différentes ont été analysées par Google, pour un total de 806 passages du robot en tout. Si on s’attarde sur les principales URL parcourues par le moteur de recherche, on se rend compte que :
- Les 4 URL les plus visitées sur cette journée sont les URL des flux RSS ;
- Vient ensuite l’accueil ;
- Et très vite on retrouve également une image et une page auteur.
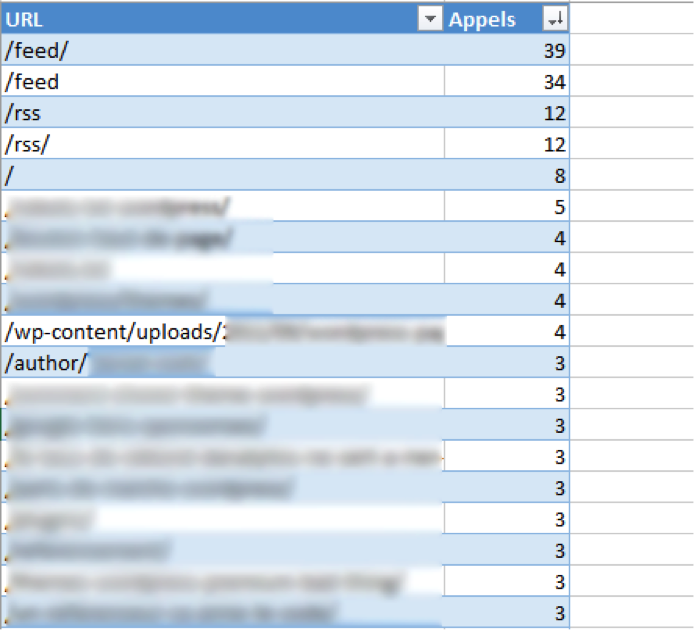
Fig. 4. Un exemple de détail des URL crawlées par GoogleBot.
La question à se poser est donc : pourquoi Google passe autant de fois sur certaines URL peu pertinentes (ici nos flux RSS) ? Et la question qui suit est de vérifier si les URL les plus analysées par Google sont bien les plus importantes pour nous.
Avec les logs, on peut ainsi mesurer le nombre total de passages de Googlebot, mais aussi vérifier, sur son budget de crawl, comment celui-ci est réparti.
Comment orienter le crawl de GoogleBot ?
Maintenant que l’on comprend ce dont il s’agit, voyons comment on peut augmenter, optimsier, ce budget de crawl et comment on peut le réorienter vers nos pages les plus pertinentes.
Les contenus inutiles
Première chose à toujours garder en tête : Google prend en compte tous vos contenus dans son budget de crawl. Cela inclut donc vos pages HTML, mais également toutes les ressources comme les fichiers JS et CSS, les images, les vidéos, ainsi que toutes les alternatives à vos publications comme les pages AMP, les pages traduites (balisages hreflang), les flux RSS, etc.
Pour améliorer le budget de crawl, il faut donc réduire au strict minimum ces URL sur un même nom de domaine. Cela passe donc par :
- La fusion de tous les CSS en un seul fichier ;
- La fusion de tous les JS en un seul fichier ;
- Si vous utilisez beaucoup d’images en background, les fusionner dans ce qu’on appelle un « Sprite CSS » ;
- Ne conserver qu’un seul flux RSS ;
- Placer chaque autre langue sur un nom de domaine différent (ou sur un sous-domaine éventuellement).
Le fichier robots.txt
Deuxième possibilité : on peut bloquer l’accès à Google peut permettre de mieux répartir ce budget de crawl. On pourrait tout à fait envisager le fait de mettre une directive Disallow pour une URL ou une série d’URL que l’on ne souhaite pas positionner dans un moteur de recherche (comme par exemple la page des mentions légales ou des conditions générales de vente, les pages "login", formulaires, pages de résultats du moteur de recherche interne, etc.).
Sachez également que la commande « Crawl-Delay » n’est pas prise en compte par Google dans un fichier robots.txt (source).
Noindex et/ Nofollow
Deux autres méthodes peuvent bloquer le robot : les attributs nofollow sur vos liens et le noindex.
La balise meta robots "NoIndex" n’est pas une solution fiable car elle bloque l’analyse de votre contenu, et non pas le crawl de l’URL. En effet, une URL en noindex sera crawlée ponctuellement par Google pour vérifier si cette balise change ou non.
L’attribut nofollow d’un lien (dans la balise A), à l’inverse, peut être une bonne solution car l’attribut empêche le moteur de recherche de suivre le lien (et donc de crawler la ressource). Cependant, cela ne fonctionne que si l’intégralité des liens internes et des backlinks externes vers cette URL précise sont bien tous en nofollow, et si cette URL n’est pas soumise à Google d’une autre façon (par un fichier sitemap, par des pings, par un flux RSS, etc.). Donc pas si évident que cela (et, en pratique, quasiment impossible en mettre en oeuvre).
Corriger vos erreurs
Parmi les autres éléments qui vont impacter le crawl de Googlebot, on peut citer les erreurs de votre site, à commencer par toute page 404 ou encore les erreurs serveur. Plus Google passera de temps sur ce type d’URL, moins il pourra crawler les pages réelles de votre site (et moins il aura envie de le faire).
De la même façon, des redirections 301 en cascade vont là encore freiner le robot (un lien A qui redirige vers B, qui lui-même redirige vers C, etc.)
Dans tous les cas, il est important de corriger ces éléments pour avoir une limite de crawl plus élevée.
La vitesse
Google l’indique clairement : le temps de téléchargement va lui aussi influer sur les passages de son bot.
Réduire le temps de chargement est donc toujours une très bonne idée, surtout que cela améliore également l’expérience utilisateur. On va donc appliquer les principes précédents (pas de page d’erreur, fusion des ressources CSS et JS, etc.), mais on va aussi devoir effectuer les actions suivantes :
- Mettre en cache le contenu afin de réduire le temps de calcul de vos pages (c’est surtout le cas avec les CMS) ;
- Réduire le poids des ressources (par exemple en compressant les images) ;
- Améliorer les performances du serveur (PHP7, compression Gzip, etc.).
La popularité
Les backlinks vont là aussi avoir de l’importance. Google indique par exemple que les URL ayant un plus fort PageRank seront crawlées plus souvent. Faites donc en sorte d’augmenter le nombre de backlinks vers vote site, que ce soient des liens vers votre page d’accueil ou des liens directs vers des pages profondes.
Comme l'explique Google : For example, high PageRank URLs probably should be crawled more often. And we have a bunch of other signals that we use that I will not say. But basically the more important the URL is the more often it will be recrawled (Source).
La Search console
Dans la Search Console, vous pouvez modifier la vitesse d’exploration de Google, à la hausse ou à la baisse. Attention cependant, cela ne veut pas dire que Google prendra en compte les demandes d’augmentation : c’est juste que vous autorisez GoogleBot à le faire.
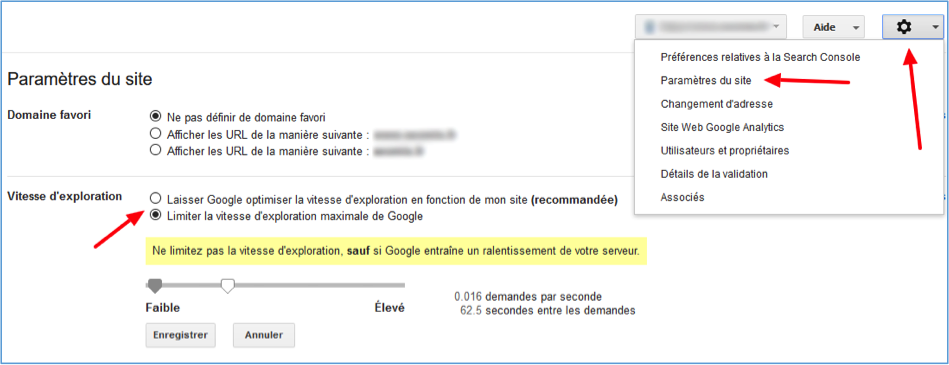
Fig. 5. En haut à droite, cliquez sur « Paramètres du site » pour modifier la vitesse d’exploration de Google.
N'utilisez cependant cette possibilité que dans des cas extrêmes et argumentés, car dans l'immense majorité des situations, Googlebot respectera votre serveur.
Pour pouvoir modifier temporairement ce crawl, sachez que vous pouvez faire des demandes manuelles à Google pour explorer une page (ou pour explorer une page et les liens qu’elle contient). Cette technique étant manuelle, elle n’a surtout d’intérêt que pour forcer le crawl de nouveaux contenus si Google ne le fait pas de lui-même.
Enfin, les fichiers Sitemaps XML peuvent aider, mais uniquement les fichiers partiels. L’idée ici est de ne mettre dans votre fichier sitemap.xml que les pages les plus importantes à vos yeux. Google peut alors considérer qu’elles ont plus d’importance, et qu’elles seront ainsi crawlées plus fréquemment par le moteur de recherche : If this URL is in a sitemap, we will probably want to crawl it sooner or more often because you deemed that page more important by putting it into a sitemap. We can also learn that this might not be true when sitemaps are automatically generated, like for every single URL entry in the sitemap (Source).
La qualité des contenus
Bien entendu, la qualité des contenus entre en ligne de compte dans le crawl. Si chaque contenu est long, pertinent et optimisé, Google reviendra plus souvent les analyser et voir si d’autres publications pertinentes existent. Le même bénéfice apparaît égalementi pour les sites qui publient souvent du contenu, car Google va alors considérer qu’il est intéressant de revenir plus souvent pour trouver vos nouvelles URL.
A l’inverse, tout contenu pauvre et/ou dupliqué partiellement ou totalement aura l’effet inverse : la diminution du crawl de votre site.
Les freins techniques
Certains éléments techniques de votre site peuvent réduire fortement le crawl de Google, et ceci pour plusieurs raisons : un blocage pur et simple du robot de Google, ou une diminution de la pertinence de vos différentes URL. Voici quelques exemples de ces erreurs :
- Un fichier robots.txt mal renseigné ;
- L’affichage de sessions PHP dans les URL ;
- Une navigation à facette générant des centaines d’URL dupliquées (voire plus) ;
- Des balises canoniques mal implémentées ;
- Des URL en soft 404 ;
- Etc.
De même, faites la chasse aux URL inutiles comme les flux RSS secondaires ou tout lien inutile dans le code source (comme par exemple les liens raccourcis ?p= sur le CMS WordPress). Pour détecter ces liens, un scan avec le logiciel Xenu Link Sleuth ou avec Screaming Frog Spider SEO vous permettra de les identifier.
Un maillage efficace
Pour terminer sur les méthodes d’amélioration et de réorientation du crawl des moteurs de recherche, les liens internes vont avoir une part cruciale. Cela implique avant tout un maillage interne efficace entre vos contenus, en faisant plus de liens vers vos pages les plus importantes (et si possible avec des ancres de texte optimisées).
De même, faites très attention aux liens communs à toutes les pages et à ceux générés automatiquement par le CMS, par vos menus, vos widgets et autre. Essayez toujours de faire des liens pertinents, qui ne sont pas en double ou qui ne pointent pas vers la page actuellement consultée par le moteur. Regardez donc toujours comment sont générés les liens dans le footer, dans les menus ou encore dans les sidebar.
De même, assurez-vous d’avoir toujours un chemin de navigation, et d’avoir un système d’articles relatifs qui ne fait que des liens entre des contenus publiés dans la même section.
Conclusion
En soit, le budget de crawl de Google n’améliore pas votre positionnement dans les moteurs de recherche. Que ce soit la limite de crawl que Google a défini ou bien l’intérêt pour lui de revenir crawler votre site (le « Crawl Demand »), cela ne vous fera pas gagner directement des positions.
Cependant, une bonne indexation en temps réel passe par une réelle maîtrise de ce crawl. Mieux encore, si Google crawle davantage vos pages importantes, cela veut aussi dire que vous avez réussi à correctement les mettre en avant.
Il est donc toujours important de surveiller et d’adapter le crawl de GoogleBot sur son site. Mais pour cela, il vous faudra travailler de très nombreux points techniques, structurels et rédactionnels pour y parvenir.
![]() Daniel Roch
Daniel Roch
Consultant WordPress, Référencement et Webmarketing chez SeoMix (http://www.seomix.fr)

 de nous rejoindre
de nous rejoindre