
De nombreuses études ont été publiées ces dernières années, ayant pour objectif de décoder les critères de pertinence majeurs des moteurs de recherche. Basées sur des sondages auprès de référenceurs ou sur des méthodes de corrélation de type Spearman, leurs résultats parfois fantaisistes montrent les limites des procédés utilisés pour les mener à bien. Les secrets des algorithmes de Google et consorts ne sont pas si faciles à percer et ce type d'étude semble aujourd'hui vain pour mener à bien ce type d'investigation. Mais n'existe-t-il pas d'autres voies plus efficaces ?
 Par Philippe Yonnet
Par Philippe YonnetJ’ai participé récemment à la préparation d’une étude SEO sur les critères de référencement réalisé par le Journal du Net. Il s’agissait d’un sondage auprès des personnes inscrites dans l’annuaire professionnel du JDN pour connaître leur opinion sur l’impact de certains facteurs.
Cette étude s’inscrit dans la lignée de nombreuses autres initiatives du même genre lancée depuis une douzaine d’années. Un certain nombre de professionnels du SEO se réfèrent aux résultats de ces travaux pour justifier l’importance de certains critères, ou en minimiser d’autres. Mais que mesurent exactement ces études ? Dans quelle mesure peuvent-elles vraiment donner des informations exploitables d’un point de vue opérationnel ? Nous allons voir qu’il faut garder dans tous les cas la plus grande prudence quant à l’interprétation des résultats ainsi publiés.
La première approche : le sondage
Historiquement, la première étude d’envergure sur les critères de classement dans l’algorithme de Google a été lancée par Rand Fishkin de Moz (à l’époque SEOMoz) en 2005. Cette première initiative a pris la forme d’un sondage auprès d’un échantillon plus que restreint d’experts SEO : 12 personnes…
Cette première édition a été plutôt saluée par les observateurs, même si certains ont critiqué le choix des experts interrogés (notamment la proportion de white hats et de black hats), et le faible nombre de « sondés ».

Fig. 1. Les 10 critères de classement les plus importants d’après le sondage de SEOMoz de 2005.
Une deuxième mouture de l’enquête a été réalisée en 2007, auprès de 35 experts cette fois-ci :
https://moz.com/blog/ranking-factors-version-2-released
Et depuis lors, Moz publie une enquête du même genre tous les deux ans environ. La dernière date de 2015. Le nombre de sondés s’est élargi avec le temps,
Fig. 2. La page de l’étude de MOZ de 2015 : https://moz.com/search-ranking-factors.
Ce type de sondage a fait des émules, y compris dans l’espace francophone. Une première étude a été lancée par Yannick Bouvard en 2015, opération renouvelée en 2016 : http://www.seo-factors.com/
Et plus récemment, cette étude du Journal du Net auprès de 140 référenceurs volontaires :
http://www.journaldunet.com/solutions/seo-referencement/1195455-seo-les-criteres-les-plus-importants-selon-140-referenceurs/
Ce que nous apprennent vraiment les sondages sur les Ranking Factors
Les informations issues des études par sondage sont souvent reprises sans aucune précaution dans la littérature sur le SEO, comme si les « critères » élus comme les plus importants par la majorité des experts en référencement interrogés étaient les plus importants dans l’algorithme de Google.
Or, compte tenu de la méthodologie employée, rien n’est moins sûr.
Ces sondages ne mesurent qu’une seule chose : l’opinion d’un échantillon de professionnels du SEO. D’un point de vue sociologique, c’est un exercice passionnant, car il permet :
- D’identifier les critères qui font « consensus », soit pour les considérer comme très importants, soit sans impact du tout ;
- Ou au contraire, d’identifier les critères dont l’importance fait débat, au point que l’opinion des SEO diverge.
Les résultats de la première catégorie sont souvent présentés comme des « conclusions » utiles d’un point de vue opérationnel, en sous-entendant que si les SEO s’accordent pour dire que certains critères sont importants, alors ces critères le sont réellement.
Le raisonnement se tient, mais comme l’opinion des experts ne se base pas sur des observations scientifiques objectives, la majorité des experts peut aussi … se tromper.
Ce que ces études montrent, ce sont les croyances les plus répandues chez les experts SEO, croyances qui sont dans la pratique alimentées :
- Par la communication de Google ;
- Par les informations véhiculées par les « gourous » et les influenceurs.
Les « croyances » ayant la peau dure, l’analyse de l’évolution des opinions sur les critères montre que même si Google se met à modifier radicalement son algorithme de classement, et le confirme officiellement, il peut s’écouler des années avant que la majorité des « sondés » change d’avis sur un critère.
Les biais cachés : le choix des questions
Outre le fait que ces « sondages » ne mesurent pas la véritable importance des « ranking factors » dans l’algorithme de classement de Google, mais ce qu’un échantillon de professionnels croit être important, la façon dont le sondage est rédigé à une forte influence sur les résultats.
En effet, c’est le « sondeur » qui décide de la liste des critères sur lesquels les personnes interrogées doivent statuer. Et la façon de présenter la question sur le critère changera la réponse donnée par la plupart des « sondés ».
Prenons par exemple 3 formulations différentes (et classiques dans ce genre de sondage) d’une question sur le critère « mots clés dans le title » :
Formulation 1 : « Pensez-vous que la présence des mots clés de la requête dans la balise <title> de la page est importante pour le référencement »
Ou
Formulation 2 : « Notez entre 0 et 5 l’impact de la présence des mots clés de la requête dans la balise <title> de la page sur les classements »
Ou
Formulation 3 : « Classez les critères suivants par ordre d’importance :
- Présence des mots clés de la requête dans la balise <title>
- Présence des mots clés de la requête dans la balise <H1>
- Présence des mots clés de la requête dans l’url
La formulation n°1 induit typiquement un grand nombre de réponses positives chez les professionnels du référencement : une majorité pense que c’est important, et répondent en ce sens.
La formulation n°2 crée une réponse beaucoup plus nuancée :
- On parle ici d’impact sur les classements, la question est plus précise : optimiser un <title> change-t-il les classements ?
- Et la notation de 0 à 5 produit un spectre de réponses plus diversifiés.
Quant à la formulation n°3, elle demande de restituer une hiérarchie, et cela produit des résultats beaucoup plus diversifiés d’un référenceur à l’autre et beaucoup moins consensuels.
Bref, la forme des questions, comme la façon de noter ou la forme de la réponse vont produire des résultats probablement très différents.
Dans tous les cas, vouloir tirer des informations opérationnelles de ces sondages s’avère difficile : un critère populaire est-il un critère important/impactant ? Ce n’est pas toujours sûr, et à moins de vouloir suivre ce que fait la meute et de renoncer à toute tentative d’approche expérimentale ou scientifique, force est de constater que les enseignements tirés de ces études sont très peu réutilisables.
Avoir une idée d’une opinion générale sur l’importance d’un critère n’est pas une information réutilisable pour optimiser un site. Car se baser sur l’opinion dominante pour savoir ce qu’il est intéressant d’optimiser n’est pas toujours pertinent. En effet, l’autre biais des questions présentes dans ces sondages, c’est de demander une opinion générale sur un critère, en faisant fi du contexte.
Par exemple demander si le contenu dupliqué a un impact négatif sur le référencement (sans infos de contexte) ou en précisant si on parle de pages de texte ou de pages produits, de duplication au sein d’un site, ou entre deux sites, produira des réponses complètement différentes.
Ces remarques ont été faites par de nombreux observateurs depuis la première étude de Moz. C’est pourquoi d’autres acteurs ont décidé de « classer » les critères de classement en utilisant une méthode plus scientifique, du moins en principe.
Les études de corrélation critères <-> rankings
Les premières études de corrélation ont été lancées par l’éditeur de l’outil Searchmetrics en 2011. L’idée est simple : mesurer la corrélation statistique entre la présence d’un critère (« la présence de nombreux domaines pointant vers le site »), et les classements observés sur un certain nombre de mots clés.
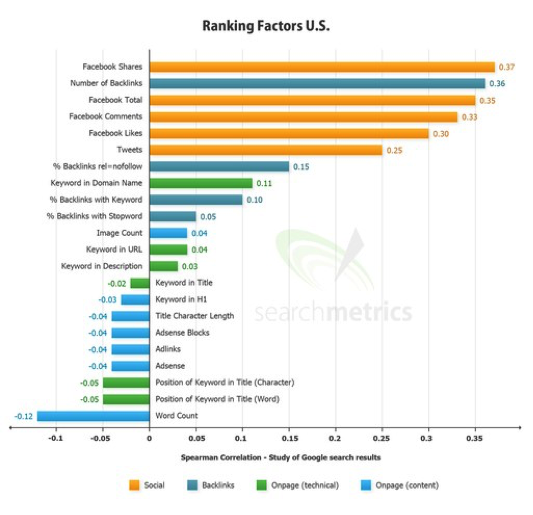
Fig. 3. L’étude « Ranking factors US » 2012 de Searchmetrics.
Ces études utilisent la corrélation de Spearman, qui est adaptée pour mesurer une corrélation entre un classement (comme l’ordre d’apparition des résultats dans Google) et un autre, comme le niveau d’un signal (comme le nombre de mots dans un document).
Moz, face à ce nouveau type d’études, a « complété » son sondage sur les Ranking factors par une étude sur les corrélations de Spearman entre critères et classements.
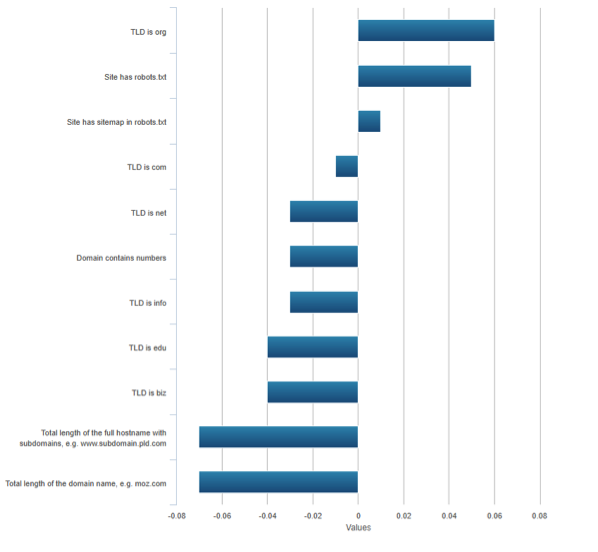
Fig. 4. Un extrait de l’étude sur les corrélations – Moz 2015.
Des études apparemment plus scientifiques, mais pas forcément très concluantes
Les études à base de corrélations de Spearman, telles que les mènent Moz ou Searchmetrics, présentent de nombreux biais méthodologiques qui font perdre beaucoup de leur pertinence en tant qu’outil d’identification des critères les plus importants.
Des « rhos » souvent trop bas pour en déduire une corrélation
Les valeurs obtenues pour les corrélations de Spearman, qu’elles soient négatives ou positives, tournent souvent autour de 0,20 ou moins pour les études sur les Ranking Factors. A ces niveaux-là, on juge en général qu’il n’y a pas de corrélation, en tout cas rien de suffisamment concluant. Mais ces résultats « non concluants » sont pourtant en général présentés parmi les autres, comme dans les deux exemples plus hauts.
Entre 0,30 et 0,50, la corrélation est jugée faible. Or, rare sont les résultats qui dépassent les 0,40 dans ces études ! Bref, les statisticiens qui jettent un œil sur ces études en concluent en général qu’on ne peut pas en tirer d’enseignements définitifs.
Dans les résultats publiés, on voit également apparaître des « moyennes » entre corrélations de Spearman. Une notion qui ne véhicule aucune signification d’un point de vue statistique et qui rend les chiffres impossibles à interpréter.
Une méthode valable quand les variables sont indépendantes, or elles ne le sont pas dans les Ranking Factors
Le plus « gênant » est certainement d’utiliser cette méthode qui s’applique à des corrélations entre des variables mutuellement indépendantes, alors que les Ranking Factors et les classements ne le sont pas : les classements dépendent forcément de plusieurs critères à la fois. Cela peut expliquer des résultats étranges. La plupart des auteurs de ces études en sont conscients, mais persistent à ne pas corriger leur méthodologie.
Cette critique est présentée dans l’étude réalisée par SEMRush en 2017 :
https://email.semrush.com/acton/attachment/13557/f-0ae2/1/-/-/-/-/Ranking%20factors.pdf
Par contre SEMRush n’explique pas sa méthodologie alternative, il est donc difficile de s’assurer qu’il s’agit bien d’une méthode plus « robuste » (surtout lorsqu'on voit les résultats publiés !). Dans tous les cas, les « corrélations » identifiées, outre leur faiblesse, manquent de valeur opérationnelle. Car comme d’habitude, il ne faut pas confondre « corrélation » et « causalité ».
Ne pas confondre corrélation et causalité
Les principales erreurs d’interprétation concernant les études sur les « ranking factors » proviennent de la confusion qu’elles entretiennent entre corrélation et causalité. Dès que l’on essaye d’interpréter des corrélations, pour en déduire des causalités, il est facile de tirer des conclusions totalement erronées.
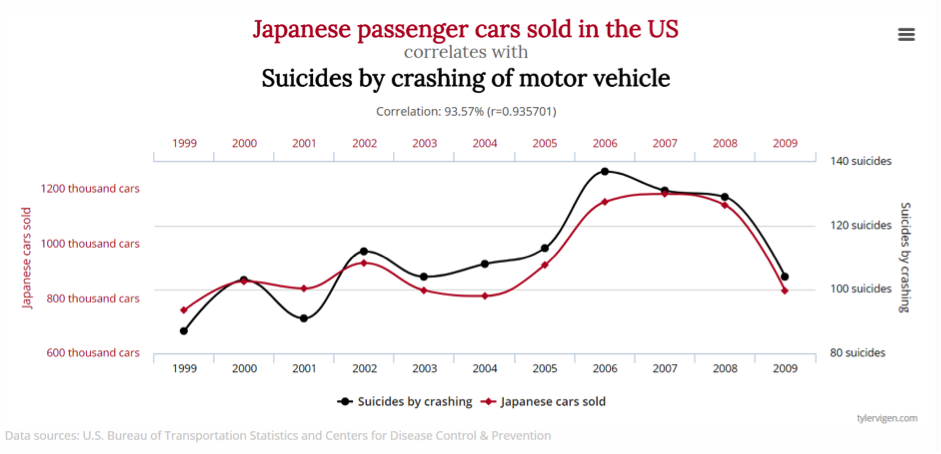
Fig. 5. Premier écueil : on peut mesurer une forte corrélation entre deux statistiques, alors qu’il n’y a pas de liens de causalité entre les deux. Ici le nombre de voitures japonaises vendues aux USA suit une évolution identique au nombre de suicides au volant. Evidemment, il est ridicule d’en conclure que l’un s’explique par l’autre !
L’existence de fortes corrélations entre une variable A et une variable B peut laisser penser que A cause B, mais cela peut-être totalement faux. Il est fréquent que les variations de A et B soient causées par un facteur C qui influence les deux autres, voire que A et B n'aient rien à voir l'un avec l'autre.
Prenons un exemple tiré des « Ranking Factors » : plusieurs études trouvent une corrélation entre la présence du mot clé de la requête dans le nom de domaine et le fait d’avoir des bons classements. Mais si on s’intéresse à ce qui cause cette amélioration des classements, deux hypothèses peuvent être émises :
- L’algorithme de classement de Google prend vraiment en compte la présence du mot clé comme signal.
- L’algorithme de classement de Google prend en compte la présence du mot clé dans les textes d’ancre des liens qui pointent vers la page comme signal, et la présence du mot clé dans l’URL (a fortiori dans le domaine) maximise les chances de la reprise des mots clés dans le texte du lien.
En fait, ce qui cause cette corrélation, c’est peut être la première hypothèse, la seconde, ou les deux à la fois ou … une autre. Et l’étude des statistiques ne permet pas, seule, de trancher.
Ce phénomène de facteur explicatif caché est appelé par les statisticiens français l’ « effet Cigogne ». Pourquoi ce nom ? Parce qu’il existe une corrélation entre le taux de natalité et la présence de cigognes dans les communes. Conclusion : les cigognes apportent les bébés ! En fait la natalité est juste plus forte dans les villages que dans les villes, et les villages ont plus de chance d’accueillir des cigognes qu’une grande ville ! La variable cachée, c’est le contexte urbain ou rural.
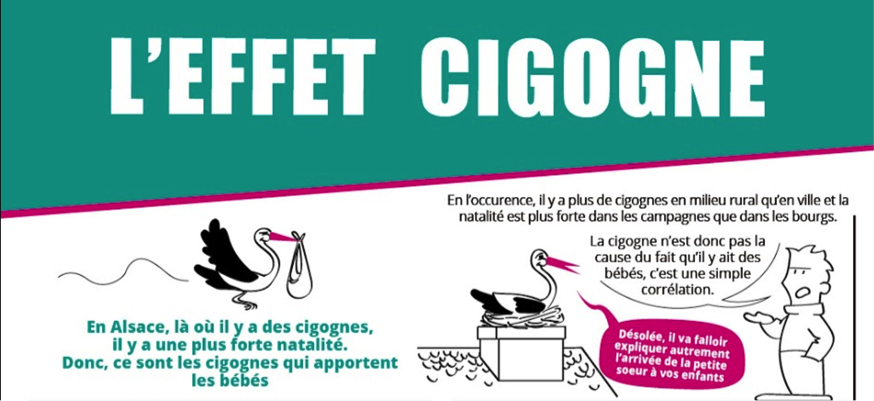
Fig. 6. L’effet cigogne (illustration issue de http://leblogdekalam.blogspot.fr/).
Bref, l’analyse des corrélations ne donne aucune information fiable sur ce qui est à l’origine de l’amélioration des classements. Ce qui doit inciter à la plus grande prudence concernant l’interprétation des études sur les « ranking factors » à base de corrélations de Spearman.
Peut-on analyser de manière scientifique l’importance des « ranking factors » dans l’algorithme de Google ?
Puisque le recours au sondage ne garantit pas la justesse des résultats obtenus, ni l’analyse statistique à l’aide des corrélations de Spearman, existe-t-il des méthodes plus sérieuses pour découvrir quelles sont les « vrais » critères importants ?
Quelques travaux de recherche ont étudié des méthodes pour faire du « reverse engineering » sur les critères de classement. Les méthodes utilisées sont assez éloignées des corrélations de Spearman. La plupart des travaux exploitent des outils d’apprentissage automatique (à base de SVM, ou de réseaux de neurone) pour « apprendre » quels sont les critères importants. En revanche, ces recherches ont été arrêtées à un stade expérimental, et aucune équipe de chercheurs n’a réalisé d’analyse complète.
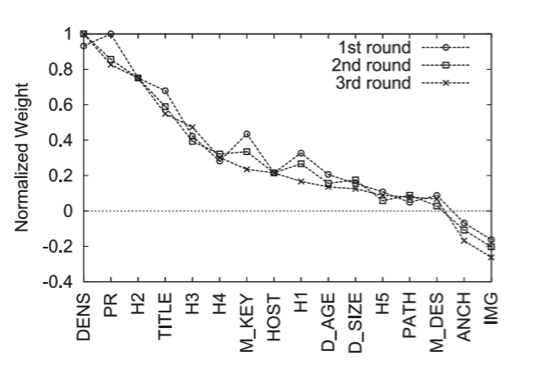
Fig. 7. Un exemple des poids obtenus avec une SVM dans l’étude de SU, HU et al.
Ces approches sont pointues, mais parfaitement réalisables par les éditeurs d’outils comme Searchmetrics ou SEMRush, qui disposent des données brutes nécessaires pour réaliser ces études. Pourquoi ne le font-ils pas ?
La principale explication qui vient à l’esprit c’est que ces études sont publiées avant tout dans le cadre d’opérations marketing, et que l’objectif de communication est parfaitement atteint avec le niveau de scientificité actuel. Et que les efforts de mise au point d’une méthode plus scientifique sont sans commune mesure avec le retour sur investissement attendu.
Des données intéressantes, à interpréter avec la plus grande prudence, et avec un intérêt opérationnel limité
En attendant de voir une approche un peu plus robuste, il faut donc en conclure que les études sur les « principaux Ranking Factors » ne tiennent pas leurs promesses.
Lorsqu’elles sont faites par sondage, elles n’indiquent pas les critères par ordre d’importance, mais ce que les référenceurs croient être importants. C’est intéressant si on fait des études sociologiques sur les professionnels du secteur, ou si on étudie la façon dont apparaissent, se maintiennent puis disparaissent les croyances au sein de la communauté SEO. Mais aucune conclusion opérationnelle sérieuse ne peut être tirée de ces sondages.
Les études de corrélation de Moz ou de Searchmetrics sont faites avec une approche plus scientifique, mais qui n’est pas exempte de biais méthodologiques majeurs. Dans la pratique, les corrélations trouvées sont le plus souvent faibles, peu concluantes. Et l’interprétation de ces corrélations, même quand elles sont fortes, est délicate, parfois même piégeuse.
Le plus intéressant à observer, ce sont les informations cachées au milieu de ces études :
- Les critères qui font débat entre référenceurs : savoir que l’importance d’un facteur de classement ne fait pas l’unanimité permet de regarder avec un œil plus critique les préceptes des Gourous du SEO sur ces points-là.
- Les corrélations négatives, ou faibles, pour des critères soit disant « majeurs ». Si un critère a réellement une influence, cela produit normalement une corrélation observable avec les classements. Si ce n’est pas le cas, il est possible que l’absence de corrélation reflète… l’absence de rôle joué par ce critère !
Ces études méritent donc d’être lues, analysées, décortiquées, mais avec un vrai regard critique, et surtout sans essayer d’en tirer des conclusions définitives sur les critères à travailler dans un contexte donné. Et peut-être verra t-on apparaître prochainement des études plus scientifiques sur ces « ranking factors »…
Bibliographie
Méthodes de découvertes des “ranking factors” :
An Analysis of Factors Used in Search Engine Ranking
Castillo et Bifet
http://airweb.cse.lehigh.edu/2005/bifet.pdf
How to Improve Your Search Engine Ranking: Myths and Reality
AO-JAN SU, Northwestern University Y. CHARLIE HU, Purdue University ALEKSANDAR KUZMANOVIC, Northwestern University CHENG-KOK KOH, Purdue University
https://networks.cs.northwestern.edu/publications/a8-su.pdf
Analysing Google rankings through search engine optimization data
Michael P. Evans
Information Systems, University of Reading, Reading, UK
https://pdfs.semanticscholar.org/fa1b/590775bc82e7984c86d3f49ad544866c3ae5.pdf
![]() Phlippe Yonnet
Phlippe Yonnet
Directeur Général de l'agence Search-Foresight, groupe My Media (http://www.search-foresight.com)

 de nous rejoindre
de nous rejoindre