

 Depuis sa naissance, le métier du SEO est indissociablement lié à toutes sortes d’investigations, de tests et de recherches. On peut même dire que la remise en question, la volonté de tester, d'étudier, de casser les légendes urbaines font partie de l’ADN de toute personne qui fait du SEO. Le mois dernier, nous avons établi les bases de la mise en place de ces tests. Ce mois, nous voyons 5 exemples avec des expérimentations visant mieux comprendre la charge des fichiers .htaccess, les balises « canonical », Google News, le cache Google et Discover...
Depuis sa naissance, le métier du SEO est indissociablement lié à toutes sortes d’investigations, de tests et de recherches. On peut même dire que la remise en question, la volonté de tester, d'étudier, de casser les légendes urbaines font partie de l’ADN de toute personne qui fait du SEO. Le mois dernier, nous avons établi les bases de la mise en place de ces tests. Ce mois, nous voyons 5 exemples avec des expérimentations visant mieux comprendre la charge des fichiers .htaccess, les balises « canonical », Google News, le cache Google et Discover...
 Depuis sa naissance, le métier du SEO est indissociablement lié à toutes sortes d’investigations, de tests et de recherches. On peut même dire que la remise en question, la volonté de tester, d'étudier, de casser les légendes urbaines font partie de l’ADN de toute personne qui fait du SEO. Le mois dernier, nous avons établi les bases de la mise en place de ces tests. Ce mois, nous voyons 5 exemples avec des expérimentations visant mieux comprendre la charge des fichiers .htaccess, les balises « canonical », Google News, le cache Google et Discover...
Depuis sa naissance, le métier du SEO est indissociablement lié à toutes sortes d’investigations, de tests et de recherches. On peut même dire que la remise en question, la volonté de tester, d'étudier, de casser les légendes urbaines font partie de l’ADN de toute personne qui fait du SEO. Le mois dernier, nous avons établi les bases de la mise en place de ces tests. Ce mois, nous voyons 5 exemples avec des expérimentations visant mieux comprendre la charge des fichiers .htaccess, les balises « canonical », Google News, le cache Google et Discover...
Les tests et les études sont probablement les moyens les plus efficaces pour apporter de la clarté dans nos méthodes de travail, casser les incertitudes omniprésentes, comprendre mieux comment fonctionne le moteur de recherche et comment l’influencer.
Dans notre premier article le mois dernier, nous avons passé en revue la base théorique nécessaire pour la mise en place correcte des études : typologie d’investigations à mener, de données à utiliser. Nous avons abordé les concepts importants du protocole de test et de la méthodologie, sans oublier des multiples biais méthodologiques et cognitifs capables de ruiner tout le travail.
Maintenant, il est temps de passer à la pratique et voir sur des exemples de tests et d’études la mise en place des points dont nous avons parlé.
Test #1 : Combien de redirections peut-on mettre dans .htaccess ?
Les migrations et les refontes sont des chantiers sur lesquelles de nombreux consultants et responsables SEO sont sollicitées sans cesse (heureusement). Et les plans de redirections en font partie intégrante.
Dans le cas de restructurations importantes, on doit mettre en place des redirections pages par page. Et une question légitime qu’on se pose souvent est la suivante : à quel point ces redirections - dont le volume peut facilement se calculer par milliers - risque d’impacter les performances du site ?
Hypothèse : Dans le cadre de ce 1er test, nous avons formulé une hypothèse suivante : Existe-t-il une limite de volume de lignes de redirections qu’on peut ajouter dans le fichier .htaccess, à partir de laquelle celui-ci dégrade le temps de chargement ?
Environnement :
- Serveur mutualisé en mode « pas cher ».
- Nouveau sous-domaine.
- Fichier html minimaliste avec un seul paragraphe de texte sans fichiers de styles ni de scripts connectés.
Mesure : Selon la documentation du serveur Apache, celui-ci avant d’accéder à une page web va consulter le fichier .htaccess pour vérifier s’il existe des directives à appliquer. C’est-à-dire que l’indicateur qu’on va mesurer doit être le plus proche du début du chargement de la page. Parmi tous les indicateurs liés aux webperfs, c’est le TTFB (Time to First Byte – temps d’accès à la page bien avant le chargement de son contenu) que nous avons logiquement sélectionné.
Pour le mesurer, on utilisera la console de Chrome en simulant 2 environnements d’accès à la page :
- Connexion fibre ;
- 3G Fast.
Critère : TTFB
Outil : Chrome DevTools (Connexion fibre vs 3G Fast).
Réserves : les résultats peuvent être différents sur des serveurs plus performants.
Résultats : Même sur un serveur bon marché, le volume de redirections allant jusqu’à 10 000 ne pose pas de problème au niveau du temps d’accès.
- A partir de 25 000 lignes de redirections, l’accès à la page est ralenti de 0,14s.
- A partir de 50 000 lignes de redirections, la latence se situe déjà au niveau de 0,23s.
- 1 millions de lignes de redirections va retarder l’accès à la page de 4s.
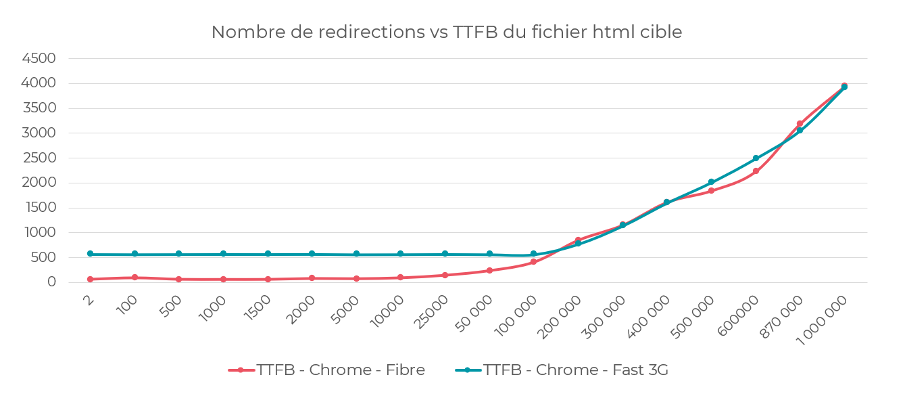
Impact du nombre de redirections page-par-page dans le fichier .htaccess sur le TTFB.
Test #2 : La balise Canonical cross domaine est-elle une solution fiable ?
Souvent en quête de plus d’audience, les éditeurs de sites ont recours à la syndication de leurs contenus sur des plates-formes populaires tiers. L’objectif est pragmatique : améliorer la portée de ses contenus en bénéficiant de l’audience « habitant » sur les plates-formes en question.
Comme on peut s’en rendre compte, le point le plus délicat est la duplication du contenu : notre article sera à la fois publié chez nous et sur un site externe.
Ainsi du point de vue SEO, une question légitime se pose : comment profiter de l’audience de la plate-forme distante toute en gardant ses acquis SEO, notamment les positions ?
Parmi les solutions proposées par Google, on trouve la mise en place de la balise « canonical » qui va relier les deux articles et assurer notre originalité. Le souci est que cette balise n’est pas une directive (comme la balise meta robots "noindex"), mais plutôt une suggestion pour Google qui peut la respecter ou pas.
Ce sera l’objet de notre 2ème étude.
Hypothèse : Dans le cas de la diffusion de nos contenus sur des sites tiers, la balise « canonical» est-elle une solution fiable pour ne pas dégrader ses performances SEO ?
Environnement : Terrain (conditions et pages réelles, positionnées)
Méthodologie : Pour étudier cet aspect, il nous faut trouver une plate-forme qui permet de publier nos contenus tout en ayant la possibilité d’indiquer dans la balise « canonical» la page source sur laquelle le contenu est déjà publié et donc considérée comme originale. Parmi les différents agrégateurs de contenus, nous avons sélectionné Medium.com qui respecte les critères imposés.
- 150k articles de Medium.com exportés au total.
- 2 876 articles gardés ayant une la balise « canonical» vers une source externe.
- Nous avons utilisé les en-têtes H1 comme mots-clés et avons vérifié les positionnements.
- Positions comparées de l’article sur Medium et sur le site d’origine.
Résultats :
- Dans 42% c’est la page d’origine de l’article qui se positionne dans les résultats de Google (celle vers laquelle pointe la balise « canonical»).
- Dans 36% des cas c’est l’article sur Medium.com qui se positionne.
- Dans 22% des cas, aucun des sites ne se positionne.
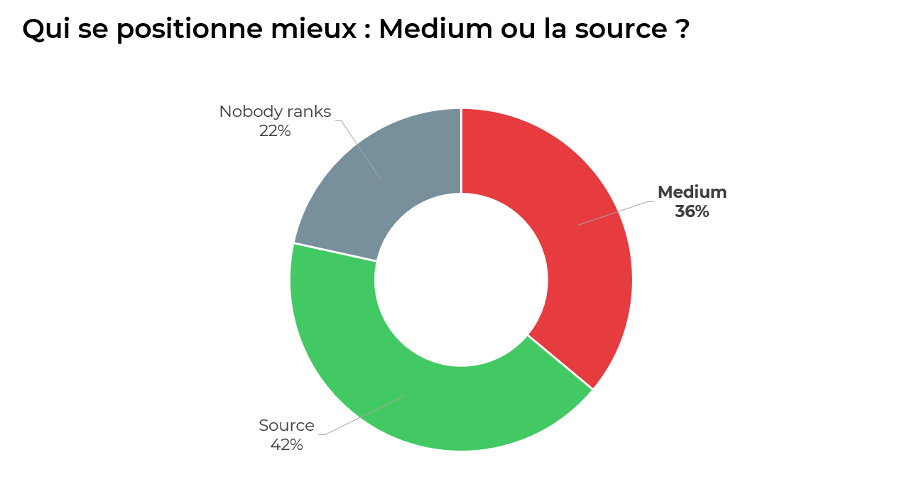
Qui se positionne mieux : Medium ou la source ?
Si on s’arrêtait sur ces premiers résultats, on serait en plein biais d’ancrage (quand on prend des décisions basées sur la 1ère impression).
La bonne question qu’on doit se poser à cette étape est la suivante : dans le cas de non-positionnements de la page d’origine, est-ce que le problème est vraiment du côté de la balise « canonical» ?
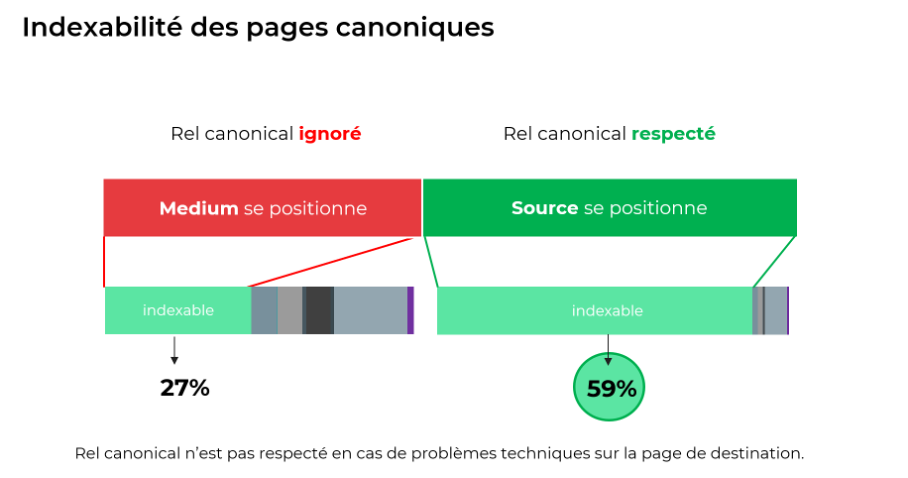
Pour aller plus loin, vérifions l’état technique des pages vers lesquels pointe la balise « canonical».
Parmi les cas où c’est Medium qui se positionne, la majorité des pages vers lesquelles pointe la balise « canonical» ne sont pas indexables (répondent en 404, contiennent une directive noindex).
Si on ajuste le ratio avec les nouvelles données reçues on obtient les résultats suivants : la balise « canonical» a été respectée par Google et dans 59% des cas a permis à la page source de l’article de se positionner dans les résultats de Google. Ce qui est un résultat plutôt satisfaisant et il s’agit d’une méthode assez efficace.
Il est possible d’aller encore plus loin. En plus de la balise « canonical», Medium permet également aux auteurs d’afficher à la fin des articles un lien HTML vers la page source (« Originally published at … »).
Et cela s’avère une solution efficace pour indiquer encore davantage à Google que l’article en question est une republication de l’article publié ailleurs.
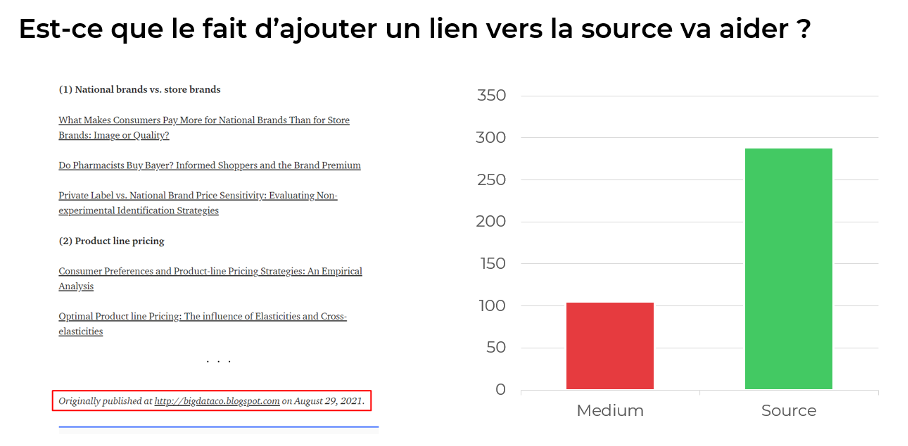
Un lien direct vers la source augmente fortement les chances de la page d’être considérée comme original.
Etude #3. Google Actualités : quand Google refuse de lire nos articles...
Très souvent à l’origine des recherches SEO se trouve la curiosité, mais il y a également des cas où les recherches sont imposées par des besoins et des problèmes réels.
En 2018, nous avons commencé à travailler avec 20minutes.fr pour améliorer la visibilité SEO de leur site média. Une des premières choses signalées par le client était une incertitude que les articles soient correctement visibles dans les résultats de Google Actualités. En effet, bizarrement, certains articles n’apparaissaient pas dans Google Actualités, d’autres avait une visibilité bien plus basse en moyenne.
Problème : Certains articles de 20minutes.fr ne passaient pas ou étaient peu visibles dans Google Actualités.
Investigation : Vérifier s’il y a des problèmes de lecture d’articles par Google et si oui, en détecter la cause.
Méthodologie :
- Nous avons pris un échantillon de 70 articles toutes thématiques confondues et les avons soumis à l’outil de dépannage d’articles dans https://partnerdash.google.com/. Dans l’ancienne version de l’espace d’éditeurs, cet outil permettait de vérifier si Googlebot News arrivait à extraire correctement le contenu des articles. (Malheureusement après la mise à jour en 2019 l’outil de dépannage n’existe plus 🙁 )
- Dès les premières vérifications nous avons constaté que Google réussissait à extraire seulement une partie de l’article. A l’issue de chaque soumission, nous avons noté tous les cas où Google faisait une troncature d’article et l’élément qui l’a provoquée.

Sur 70 articles, 18 ont été extraits entièrement, les 52 autres articles ont été tronqués.
Sur notre échantillon d’articles, nous avons noté tous les éléments en notant à quel moment le robot de Google News cessait de l’explorer :

Dans 32 cas sur 52, Googlebot-News arrêtait de lire l’article après un encart « A lire aussi » suggérant au lecteur un lien vers un autre article.
Techniquement, l’encart ne présentait rien de particulier (un <div> avec un paragraphe), mais comme il était intégré souvent tout au début de l’article, Google ne prenait en compte qu’un ou deux paragraphes, ce qui ne permettait pas aux articles de remonter dans Google Actualités.
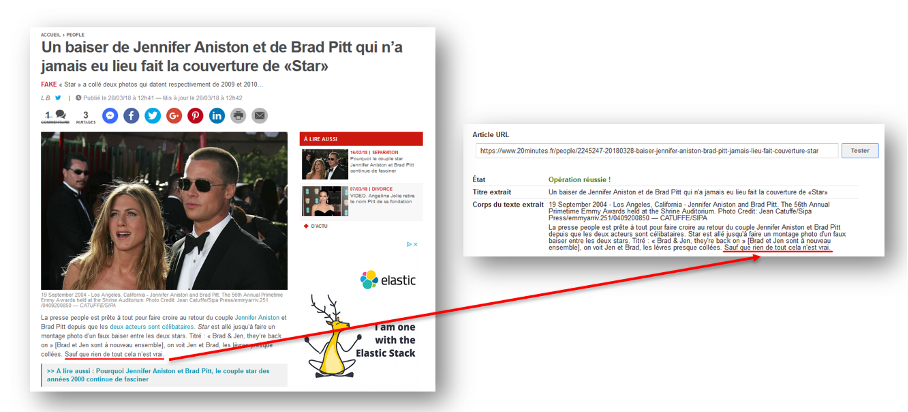
Une fois que ces liens ont été retirés du corps d’articles (déplacés à la fin), les pages ont regagné en visibilité dans Google Actualités.
Enseignement de cette étude : essayer de ne pas intégrer des éléments hétérogènes dans le corps d’articles car le robot d’exploration de Google News peut les considérer comme signalant la fin de l’article.
Test #4. Pourquoi une page peut ne pas avoir une version cache dans Google ?
Un jour un de nos clients nous a signalé un problème sur son site : certaines pages du site avaient bien une version en cache sur Google, alors que d’autres non. Les pages n’avaient pas de directive noarchive qui sert habituellement à interdire la sauvegarde de la page dans le cache de Google.
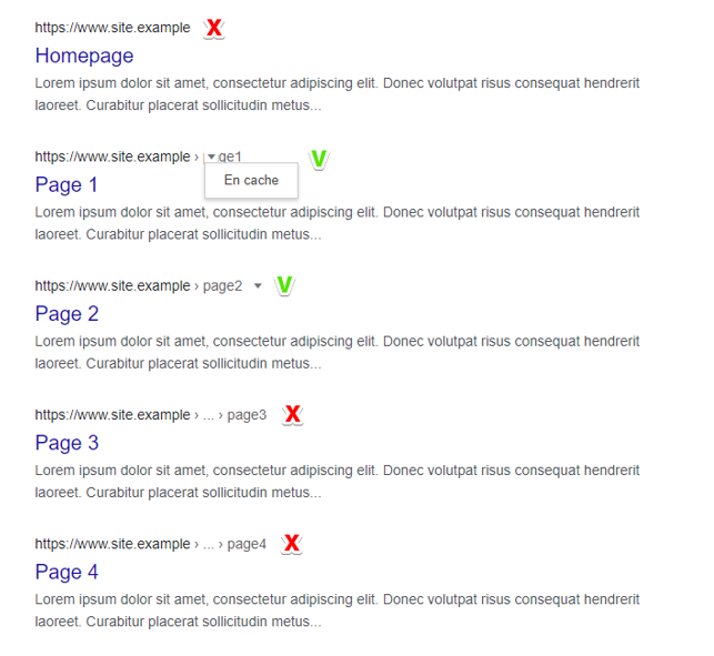
Exemple de résultats de recherche sur la commande site:nomdusite.fr (résultats anonymisés) : certaines pages ont une version cache, d’autres non.
Une raison de plus de faire une étude !
Hypothèse et objet de l’étude : Il apparaît qu’il y a un point spécifique à toutes les pages qui n’ont pas de version cache, différent par rapport aux pages qui n’ont pas ce problème. Quel est cet indicateur et à partir de quelle valeur cela interdit la mise en cache ?
Méthodologie :
- Exporter depuis les résultats de Google dans les quantités égales les pages ayant une version en cache et celles qui ne l’ont pas.
- Crawler avec Screaming Frog SEO Spider toutes ces pages en récupérant le maximum d’indicateurs techniques et éditoriaux.
- Comparer les indicateurs pour deux types de pages et identifier celui ou ceux qui font différence.
Résultats :
A l’issue de cette approche, beaucoup d’indicateurs ont été passés en revue et il y en a finalement eu un qui indiscutablement a montré une corrélation maximale : le poids HTML de la page.
Pour rappel, le poids HTML est le volume de code source HTML calculé en octets (1 caractère, chiffre, lettre ou un espace fait 1 octet).
La première liste telle que l'a ressortie le crawler paraît une peu chaotique et ne dit probablement grand-chose. Mais la magie du tri par ordre décroissant met en évidence son impact sur la mise en cache :
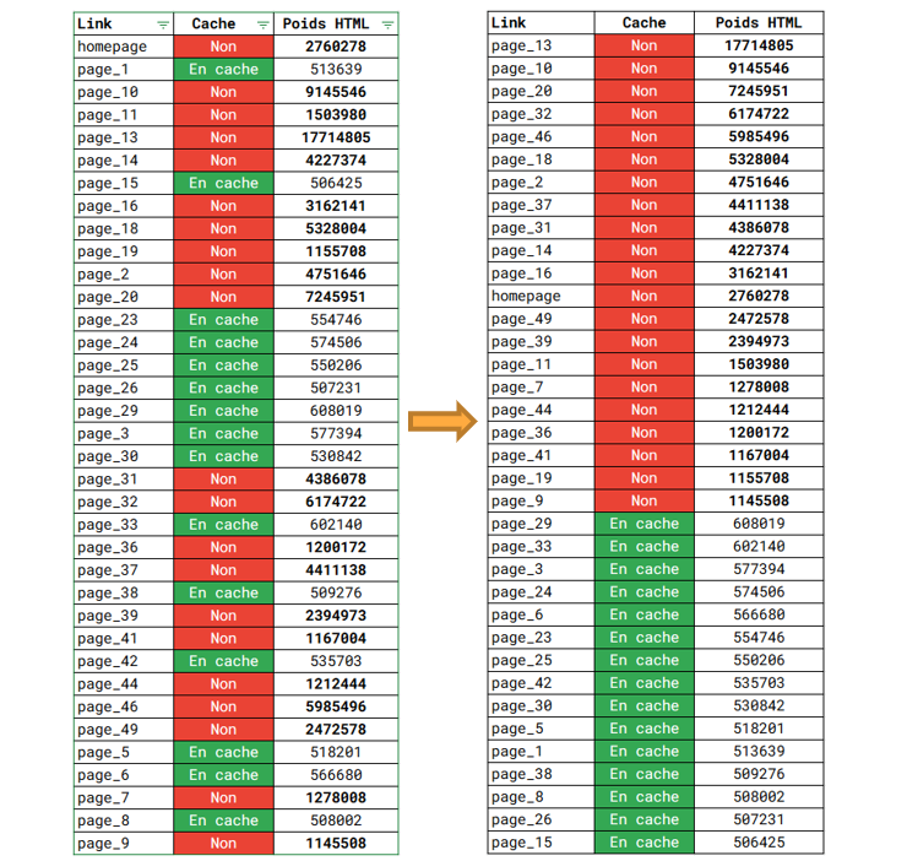
Corrélation entre le poids HTML de la page et la présence de sa version en cache sur Google.
Ainsi, Google ne va pas garder la version de la page dont le poids HTML dépasse 1 Mo (c’est-à-dire 1 million de caractères).
Les porte-paroles de Google ont précisé à maintes reprises que la présence ou l’absence de la version cache n’influence aucunement les positionnements de la page. En même temps, cette étude a permis d’identifier le problème du poids de la page qui a été dû au framework AngularJS déployé de manière non optimale.
Etude #5. Google Discover : réduire la zone d’inconnu
Sorti officiellement en 2019, Google Discover a très vite attiré l’attention par les volumes d’audience envoyés aux sites web.
Pour rappel, Google Discover est un système de recommandation qui propose des sélections de pages en fonction des centres d’intérêt d’utilisateurs d’Android et d’applications de Google.
Comme il s’agit du trafic gratuit, de plus dans l’environnement de recherche de Google, normalement cela rentre dans le périmètre de travail de consultants SEO, ou tout du moins de ceux parmi nous qui travaillent avec les sites médias.
Google Discover et difficulté de son étude.
Google Discover est un environnement très particulier constitué de nombreuses contraintes :
- Résultats 100% sélectionnés par l’intelligence artificielle,
- Absence de mots-clés classiques remplacés par les centres d’intérêt,
- La documentation plus que concise (les recommandations de Google pour apparaitre dans Discover se limitent à « créez des articles tendances avec des titres pertinents (sans abuser) et des images larges ».
- Comme Discover existe dans les applications mobiles, il est impossible de scraper de larges échantillons de données de sites différents. On n’est pas limité aux données de nos sites personnels.
- Au moment où ces lignes étaient écrites, l’API Discover n’existait pas encore et il était impossible d’extraire rapidement toutes les données étant obligés de recourir aux exports manuels.
Pourtant, avec toutes ces contraintes, peut-on finalement apprendre quelque chose sur le fonctionnement de Google Discover ?
La 1ère question à laquelle on peut répondre avec certitude : Faut-il être obligatoirement référencé dans Google Actualités pour apparaître dans Google Discover ?
De différentes observations apportent une réponse claire et nette : « non » !
- Tout d’abord, si on analyse les pages apparaissant dans Discover, on constatera qu’elles apparaissent également sur les autres leviers SEO : celui de Google News et Google organique classique. C’est juste une question de sujet tendance.
- Une autre preuve : des e-commerçants peuvent voir les fiches de leurs produits phares apparaissant régulièrement dans Google Discover. Logiquement, elles ne sont pas référencées dans Google Actualités.
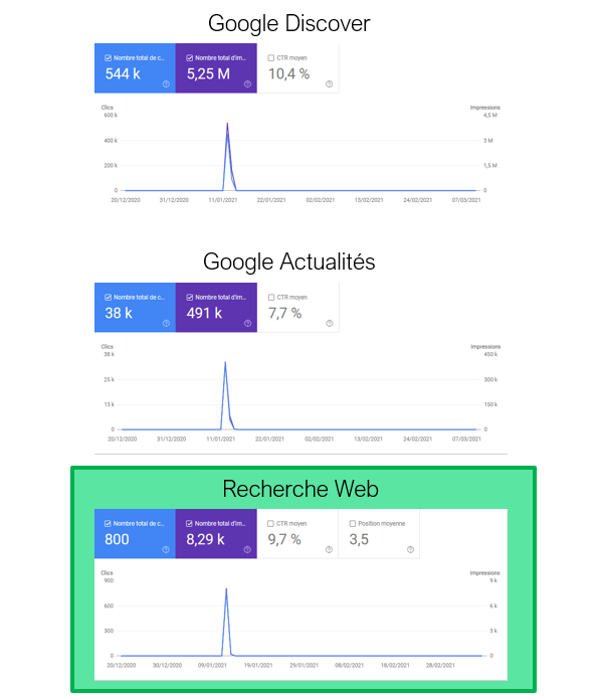
Apparition d’un même article sur Google Discover, Google Actualités et recherche web.
Google Discover est un exemple assez parlant de de la façon dont, en réorganisant et enrichissant les rapports de base, on peut apporter plus de clarté dans le fonctionnement de l’outil.
Par exemple, nous pouvons associer les pages aux dates d’apparition dans Google Discover et analyser l’évolution du nombre de pages apparaissant chaque jour dans Discover.
On est purement ici sur l’analyse statistique. Cette vue trouve son utilité en cas de baisse subite de trafic depuis Discover : analyser si réellement moins d’articles y apparaissent.
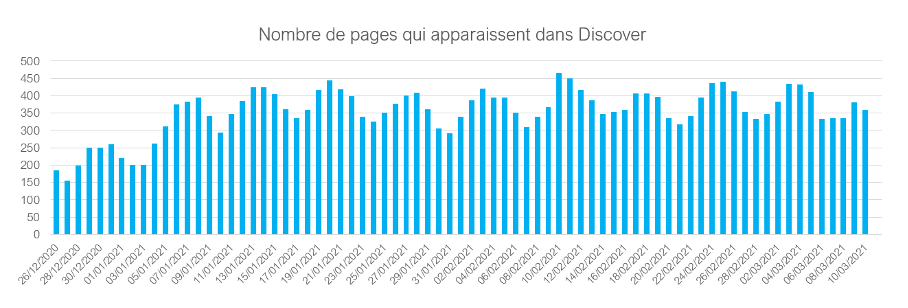
Exemple de vue : nombre de pages apparaissant par jour dans Discover sur un site média.
Comme nous avons en notre possession les articles date par date, nous pouvons calculer la durée de vie de nos pages dans Google Discover.
Avec tout le caractère éphémère du trafic Discover, on trouve néanmoins des pages qui apparaissent pendant 10-20 jours. L’analyse de ces pages permet de réorienter la campagne éditoriale vers la création d’articles potentiellement plus efficaces dans Google Discover :
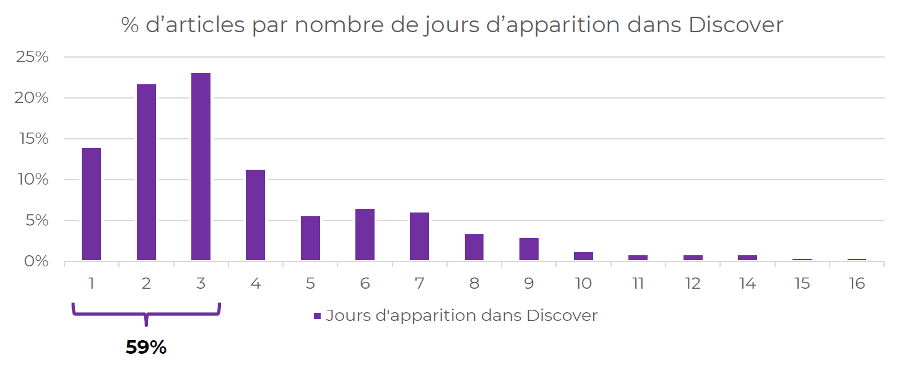
Répartition des pages d’un site média par nombre de jours d’apparition dans Google Discover.
On peut aller plus loin et enrichir les données fournies par la Search Console. Ainsi, nous pouvons crawler les pages apparues dans Google Discover, en extraire leur date de publication réelle et la comparer avec celle d’affichage dans Discover.
Cette analyse nous permet de voir très clairement que les pages apparaissant dans Google Discover sont majoritairement récentes. Sur le graphique ci-dessous, ont peut voir les résultats pour un site média français :
- 36% d’articles apparus dans Google Discover ont été publiés le jour même ;
- 88% d’articles ont été publiés il y a au maximum 3 jours.
Néanmoins, il est utile d’analyser les patterns des vieux articles qui remontent dans Discover.
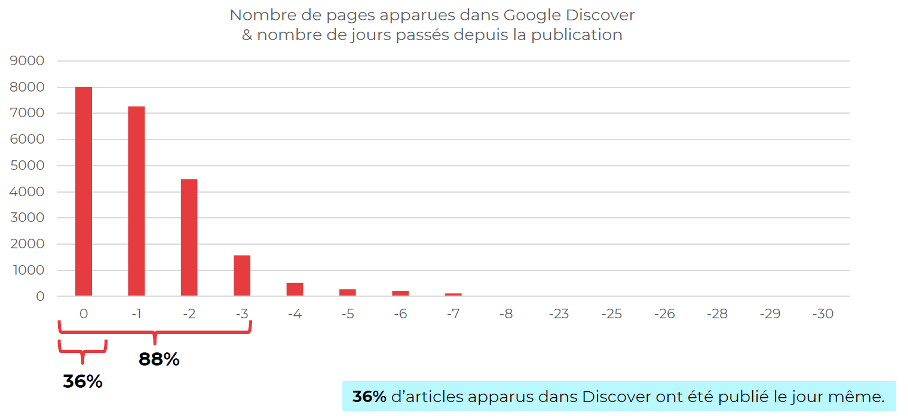
Écart en jours entre la date de publication d’article et date d’apparition dans Google Discover sur un site média français.
Les sites médias ont souvent à côté de la date de publication une date de modification, si l’article a évolué depuis sa publication. En la récupérant, nous pouvons comparer les performances d’articles qui ont été modifiés et qui sont restés sans changement.
Les résultats obtenus sur un grand site média français ont témoigné que la modification de l’article permettait de rallonger le cycle de vie en moyenne de 16%.
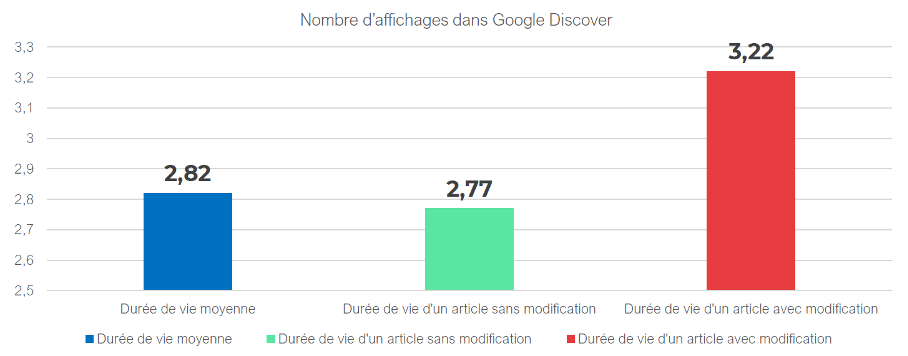
La modification de l’article et de sa date de mise à jour permet de rallonger le cycle de vie d’un article en moyenne de 16%.
En crawlant les pages, on peut également récupérer leurs titres et croiser leur longueur avec la clickabilité (CTR) dans Google Discover. Par exemple, pour comprendre si les ce sont des titres courts ou longs attirent plus l’attention d’usagers de Discover.
Quant aux résultats observés sur plusieurs sites médias, en règle générale, plus le titre est long, meilleur est son taux de clics dans les résultats de Discover. La raison est probablement simple : un titre long occupe une superficie plus grande, ce qui se ressent beaucoup sur les écrans mobiles.
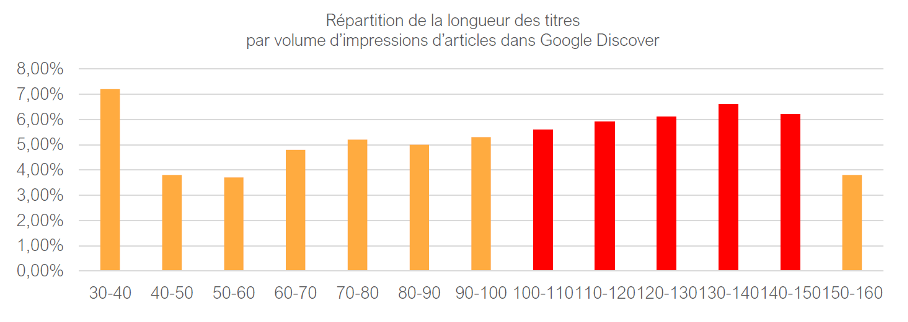
Des en-têtes plus longs génèrent des taux de clics plus élevés dans Google Discover.
On peut aller encore plus loin et analyser les titres, non seulement du point de vue quantitatif, mais aussi qualitatif. Il est notamment possible de réaliser une analyse sentimentale et étudier quels titres marchent le mieux : neutres ou colorées, subjectifs ou objectifs.
Sur des analyses de titres de plusieurs sites médias français, on a constaté que les titres donnant un avis, une opinion sur un fait génèrent bien plus d’impressions dans Discover que des titres neutres.
Quant au sentiment partagé par le titre, les résultats sont moins concluants. Les titres avec un sentiment positif ont cependant l’air de performer mieux.
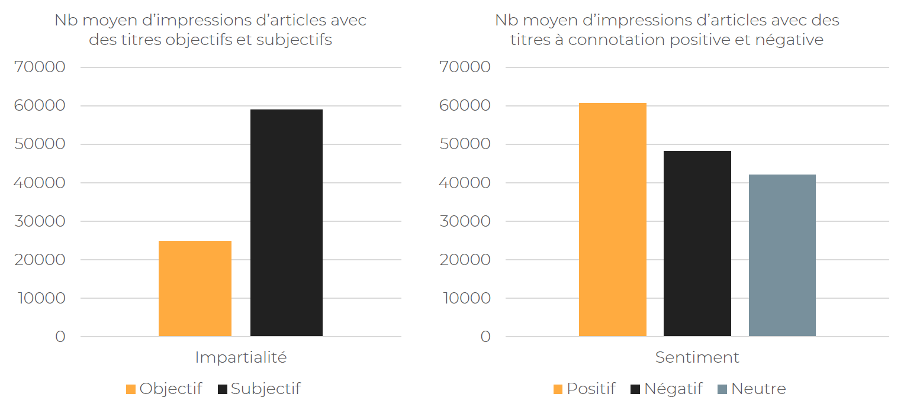
Les titres donnant une opinion, partageant une émotion positive génèrent plus d’impressions dans Google Discover.
Quels sont les thèmes d’articles qui apparaissent le plus souvent dans Discover ? Comme on le sait bien, Google Discover propose des résultats basés sur nos centres d’intérêts. Ces centres d’intérêt sont nombreux, se calculant en milliers.
Evidemment on ne peut pas s’adapter à tous les centres d’intérêt, mais on peut identifier les sujets communs qui marchent le mieux :
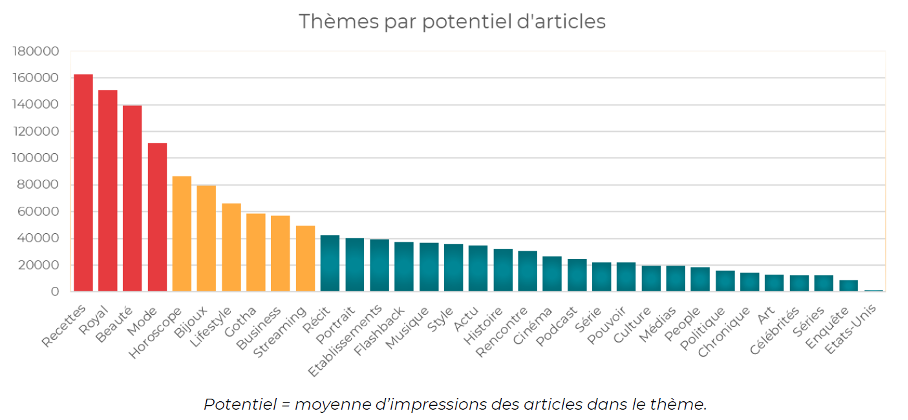
Analyse des sujets les plus performants dans Google Discover pour un magazine en ligne français.
Faire ce genre d’études permet de mieux comprendre quels sujets sont affichés le plus souvent dans Google Discover. Et si un site média vit des baisses d’audience d’actualité classique, on peut suggérer aux équipes de journalistes de miser sur certains sujets qui auront plus de chance d’apparaitre dans Discover. Et les chiffres d’audience fournis par Google Discover sont clairement très intéressants !
Pour conclure
Comme on l’a vu sur les exemples ci-dessus, les tests et études SEO peuvent prendre des formes différentes et se réaliser dans des contextes différents.
Ils permettent d’apporter des réponses aux questions courantes (redirections dans .htaccess), confirmer ou infirmer des pratiques SEO (balise canonical cross-domaine), éclaircir certaines particularités de fonctionnement de Google auprès de nos clients (Google cache) ou enlever (un peu) un voile d’inconnu sur les nouveaux outils comme Google Discover.
Nous espérons que cette série d’articles vous a motivé à faire également des investigations de votre côté !

![]() Alexis Rylko, directeur technique SEO chez iProspect (https://www.iprospect.com/ & https://alekseo.com/)
Alexis Rylko, directeur technique SEO chez iProspect (https://www.iprospect.com/ & https://alekseo.com/)

 de nous rejoindre
de nous rejoindre