

 Le fichier robots.txt est une composante essentielle dans l'art de mettre en place sur son site web un crawl de qualité par les robots des moteurs de recherche. Mais sa syntaxe n'est pas toujours si simple que cela et les erreurs sont parfois fréquentes. Voici une petite revue d'effectif des bonnes pratiques à mettre en place pour avoir le moins de surprises possible...
Le fichier robots.txt est une composante essentielle dans l'art de mettre en place sur son site web un crawl de qualité par les robots des moteurs de recherche. Mais sa syntaxe n'est pas toujours si simple que cela et les erreurs sont parfois fréquentes. Voici une petite revue d'effectif des bonnes pratiques à mettre en place pour avoir le moins de surprises possible...
 Le fichier robots.txt est une composante essentielle dans l'art de mettre en place sur son site web un crawl de qualité par les robots des moteurs de recherche. Mais sa syntaxe n'est pas toujours si simple que cela et les erreurs sont parfois fréquentes. Voici une petite revue d'effectif des bonnes pratiques à mettre en place pour avoir le moins de surprises possible...
Le fichier robots.txt est une composante essentielle dans l'art de mettre en place sur son site web un crawl de qualité par les robots des moteurs de recherche. Mais sa syntaxe n'est pas toujours si simple que cela et les erreurs sont parfois fréquentes. Voici une petite revue d'effectif des bonnes pratiques à mettre en place pour avoir le moins de surprises possible...Le fichier robots.txt est un atout majeur pour maîtriser le crawl des moteurs et autres outils sur un site web. Placé à la racine d’un site (ex : www.monsite.com/robots.txt), il permet via différentes directives l’accès ou non à certaines ressources par les crawlers. Cela peut concerner des URL non pertinentes par exemple (filtres à facettes, URL techniques, URL liées à l’interface d’administration, etc.) afin d’améliorer la qualité des pages indexées, mais aussi le crawl budget pour les sites à forte volumétrie de pages.
Il est visité régulièrement par les robots d’exploration des moteurs de recherche, et certains outils (ex : aspirateurs de site web) ne les contrôlent que lorsqu’il y a appels spécifiques. Nous passerons en revue dans cet article les erreurs communes relatives au fichier robots.txt, ainsi que des astuces pour mieux optimiser ce fichier et en faciliter sa lecture et son maintien dans le temps. Mais revenons avant tout sur une notion importante relative au crawl et à l’indexation.
Crawl ne rime pas avec indexation
Ce fichier est souvent mal compris : il ne faut pas croire qu’il permette de désindexer des URL, mais plutôt de restreindre le crawl sur des URL, et donc de potentiellement d’empêcher l’indexation de pages spécifiques puisqu’elles ne peuvent pas être crawlées.
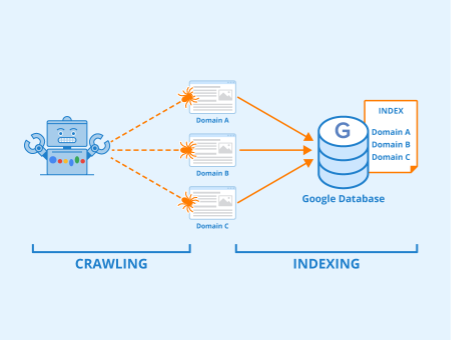
Différences entre crawl et indexation. Author: Indexing Seobility - License: CC BY-SA 4.0
Pour désindexer des pages, il est nécessaire de passer par la balise <meta name=robots content="noindex"> (ou via les en-têtes HTTP avec la directive X-Robots-Tag). Il faut bien comprendre qu’une page crawlable ne sera pas forcement indexée (pertinence, duplication, problème technique ou directive noindex), et qu’à l’inverse une page non crawlable peut parfois être indexée (ex : restriction dans le robots.txt ultérieure à l’indexation, indexation malgré une restriction !)
Google et le robots.txt
Toujours efficace ?
Bien que Google soit censé respecter le fichier robots.txt, il est possible qu’il remonte malgré tout dans ses résultats, des pages bloquées dans le fichier robots.txt.
Il peut s’agir d’URLs qui reçoivent plusieurs liens externes, que Google indexera sans même les visiter, en utilisant le texte descriptif / ancre de lien comme information pour juger de sa thématique, et éventuellement renommer le titre de la page dans les résultats. Il indexera juste l’URL et non son contenu puisqu’il ne peut pas visiter la page, mais elle pourra malgré tout remonter sous cette forme dans les pages de résultats :

Page présente dans l'index malgré une restriction.
La directive Noindex ? plus d’actualité
Bien que non documentée, Google prenait en compte auparavant la directive « Noindex : /url-a-desindexer » du robots.txt. Elle permettait la désindexation de plusieurs URL voire de l’ensemble d’un répertoire après plusieurs semaines (voire mois dans certains cas), et s’avérait extrêmement pratique, mais s’éloignait de la fonction initiale du standard robots.txt, à savoir maîtriser le crawl.
Cette commande n’est malheureusement plus prise en compte depuis le 1er septembre 2019. Google en avait fait l’annonce il y a plus de 2 ans via son compte « Google Search Central » sur Twitter :
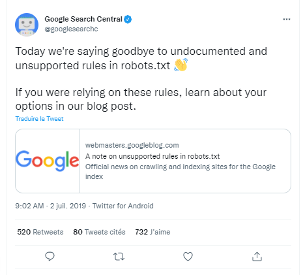
Fin de la prise en compte du Noindex dans le robots.txt
L’article relatif à cette information est toujours disponible ici : https://developers.google.com/search/blog/2019/07/a-note-on-unsupported-rules-in-robotstxt . A noter que la directive est ignorée depuis cette date, et qu’il est préférable de passer par d’autres méthodes pour la désindexation.
Directives User-agent
La directive « User-agent : » permet de cibler des moteurs et crawlers spécifiques. La directive « User-agent : Googlebot » indique que les règles qui suivront seront destinées au moteur Googlebot. Une liste spécifique des crawlers utilisés par Google est disponible sur le site Google Search Central : https://developers.google.com/search/docs/advanced/crawling/overview-google-crawlers?hl=fr
Regroupement
Il est possible d’attribuer des règles différentes pour chaque robot d’exploration, par exemple :
User-agent : Bingbot
Disallow: /images/pictos/
Disallow: /search/
User-agent : Googlebot
Disallow: /images/pictos/
Dans le cas où un ensemble de règles (Allow, Disallow) concerneraient plusieurs robots d’exploration/crawlers, il est possible de regrouper les règles de la façon suivante :
User-agent : Bingbot
User-agent : Googlebot
/images/pictos/
On simplifiera ainsi la lecture et la maintenance du fichier par des humains (à titre anecdotique, il existe d’ailleurs un standard humans.txt pour l’équivalent du robots.txt par les humains, dédié à citer les personnes ayant participé à la création d’un site, ex : https://www.google.com/humans.txt).
Attribution des directives
Il est donc courant de rencontrer des fichiers robots.txt avec plusieurs blocs en fonction des « user-agent » auxquels s’adressent les règles. On peut donc avoir des règles spécifiques à certains robots, et des règles communes à l’ensemble des robots.
Attention toutefois à une spécificité qui n’est pas gérée de la même façon par les différents robots d’exploration (Bingbot ne gère pas les directives ci-dessous de la même manière). Le standard veut que dès qu’un robot est ciblé via une directive User-agent, ex : « User-agent : Googlebot », le robot en question ne tienne compte que des règles du bloc qui lui sont associées, et donc pas des règles présente dans la directive « User-agent : * » qui s’adresse à l’ensemble des robots.
Avec le fichier ci-dessous, Googlebot pourra crawler le répertoire « /private/ » :

Mauvaise configuration du robots.txt
Dans la mesure où une directive s’adresse spécifiquement à lui, il ne tiendra pas compte de la directive « User-agent : * ». Si l’on souhaite empêcher le crawl de Google dans le répertoire private, il sera donc nécessaire de répéter la directive « Disallow : /private/ » dans le bloc dédié aux directives de Googlebot :

Directives pour chaque user-agent
N.B : l’affichage de ce type de répertoires en clair dans le robots.txt n’est pas très sécurisé, un utilisateur mal intentionné pourrait tenter de visiter ce répertoire qui semble confidentiel… N’oubliez pas que les humains peuvent accéder au fichier robots.txt de n’importe quel site !
Syntaxe des directives
Des erreurs fréquentes de syntaxe sont effectuées sur ce fichier robots.txt. Voici un petit mémo sur des éléments à respecter pour éviter un crawl non souhaité, ou l’inverse :
Casse et encodage
Les crawlers qui utilisent le fichier robots.txt respectent la casse, ce qui signifie que si vous avez des URL en majuscule et d’autres en minuscules, les règles de votre fichier doivent en tenir compte. Cela ne concerne que les directives « Allow : » et « Disallow : », et pas vos déclarations « User-agent » : « User-agent :GOOGLEBOT » sera aussi bien compris que « User-agent : googlebot ».
Par ailleurs, l'encodage des caractères du fichier robots.txt doit se faire en UTF-8. En effet, Google peut ignorer les caractères qui ne sont pas dans la plage de caractères UTF-8, ce qui pourrait rendre invalides les règles du fichier robots.txt.
Attention également aux caractères invisibles qui peuvent invalider certaines règles (cas déjà rencontré). L’utilisation d’un éditeur hexadécimal avait permis d’identifier un caractère invisible dans les éditeurs de texte standards.
Début et fin de chaine
Slash en début de règle
Il est préférable de placer un slash au début des URL contenues dans le fichier robots.txt. En cas d’utilisation de de wildcard (* = n’importe quel caractères répété plusieurs fois), les règles pouvaient être mal comprises :
![]()
Règle pas assez spécifique
La règle ci-dessus n’empêchait pas le crawl des URL de commentaires. La règle adéquate aurait du être :

Règle corrigée avec un slash
Ce problème avait généré plusieurs erreurs par le passé, en remontant des alertes dans Google Webmaster Tools (ancienne version de la Search console). Google avait ensuite précisé : « Si nous trouvons un chemin d'accès sans barre oblique initiale, nous pouvons faire comme si elle y figurait. » ce qui était plutôt rassurant, mais par sécurité, mieux vaut respecter ce slash en début d’URL.
Voici l’article relatif à cette problématique : http://www.abondance.com/actualites/20160225-16197-google-a-modifie-son-mode-de-lecture-des-fichiers-robots-txt.html
Fin de règle
Par défaut, une règle Allow ou Disallow ne concerne que le début des URL. A titre d’exemple, la règle suivante :
Disallow: /fichiers/ cible toute les URL qui commencent par /fichiers/. Il n’est donc pas nécessaire d’ajouter un wildcard à la fin de cette dernière (Disallow: /fichiers/*), l’URL /fichiers/repertoire/monfichier.html sera bien bloquée avec la directive « Disallow : /fichiers/ ».
Si l’on souhaite définir à l’inverse une fin d’URL, il est nécessaire d’utiliser le caractère $ qui représente une fin de chaîne. Pour n’autoriser que le crawl de la racine d’un répertoire et pas de son contenu, on pourra utiliser les deux instructions suivantes avec le caractère $ pour indiquer une fin de chaîne :
User-agent:*
Disallow : /categorie/
Allow : /categorie/$
L’URL /categorie/ sera crawlée, mais pas l’URL/categorie/sous-categorie/.
Cela peut s’avérer pratique dans certains cas, notamment sur les sites e-commerce ayant des moteurs à facettes, ou encore pour des sites en construction dont on ne voudrait faire indexer que la page d’accueil.
Mise en correspondance des règles
Depuis que Google exécute le Javascript et tente d’avoir une vision des pages qu’il crawle au plus proche de ce que voient les utilisateurs finaux, il n’est pas rare de voir des autorisations de crawl pour les JS et CSS via la directive « Allow : » uniquement sur ces fichiers (ex : Allow : /*.js, Allow : /*.css). Bien que cela parte d’une bonne intention, ces règles ne fonctionneront pas quand elles concernent des fichiers placés à l’intérieur de répertoires restreints au crawl.
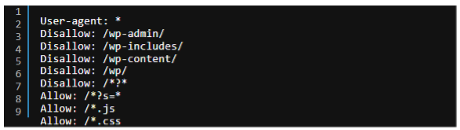
Problème syntaxique avec la directive Allow
En effet, il est précisé dans la documentation de Google que : Lors de la mise en correspondance des règles robots.txt avec les URL, les robots d'exploration utilisent la règle la plus spécifique en fonction de la longueur de son chemin.
Si l’ensemble des fichiers que l’on souhaite autoriser au crawl se trouvent dans le répertoire « /wp-content/ », il faudra supprimer les deux dernières règles ci-dessus et les remplacer par :
Allow : /wp-content/*.js
Allow : /wp-content/*.css
Cela réside dans le fait que Google tient compte en priorité de la règle qui concerne le plus long chemin (nombre de caractères) pour crawler ou non des URL. Google utilise un autre exemple pour illustrer ce comportement avec l’URL http://example.com/page.htm et les directives suivantes :

Mise en correspondance des règles Allow et Disallow
La règle qui sera applicable est "Disallow: /*.htm", car elle correspond à plus de caractères dans le chemin de l'URL de la directive, et est donc plus spécifique. La page /page.htm ne sera donc pas crawlable.
Règles contradictoires ?
En cas de directives qui seraient contradictoires, Google précise dans sa documentation qu’il utilisera la règle la moins restrictive : Dans le cas de règles contradictoires, y compris celles comportant des caractères génériques, Google utilise la règle la moins restrictive.
Afin d’illustrer cet exemple, la règle applicable sera « Allow : /folder » avec les directives mentionnées ci-dessous, car c’est la moins restrictive.

Comportement du crawl de Google avec des règles contradictoires
Avec ces différents comportements et pour éviter tout crawl sur des éléments non souhaités (où à l’inverse tout blocage sur des éléments que l’on souhaite voir crawlés), une phase de vérification via l’outil de test proposé par Google reste votre meilleure arme pour vérifier l’ensemble de vos règles.
Outil de test du robots.txt
L’outil de Google est disponible à cette adresse : https://www.google.com/webmasters/tools/robots-testing-tool
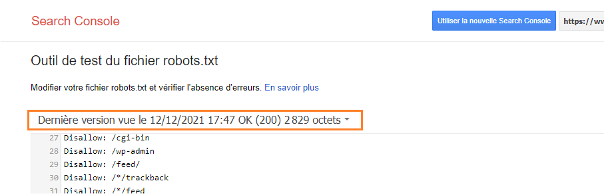
Outil de test du robots.txt proposé par Google
Il vous suffit de sélectionner la propriété relative à votre site pour effectuer vos tests. Google utilisant la dernière version mise en cache comme le montre la capture ci-dessus, vous pouvez tout à fait tester vos nouvelles règles en écrasant les règles importées dans l’outil en modifiant le champ textarea :
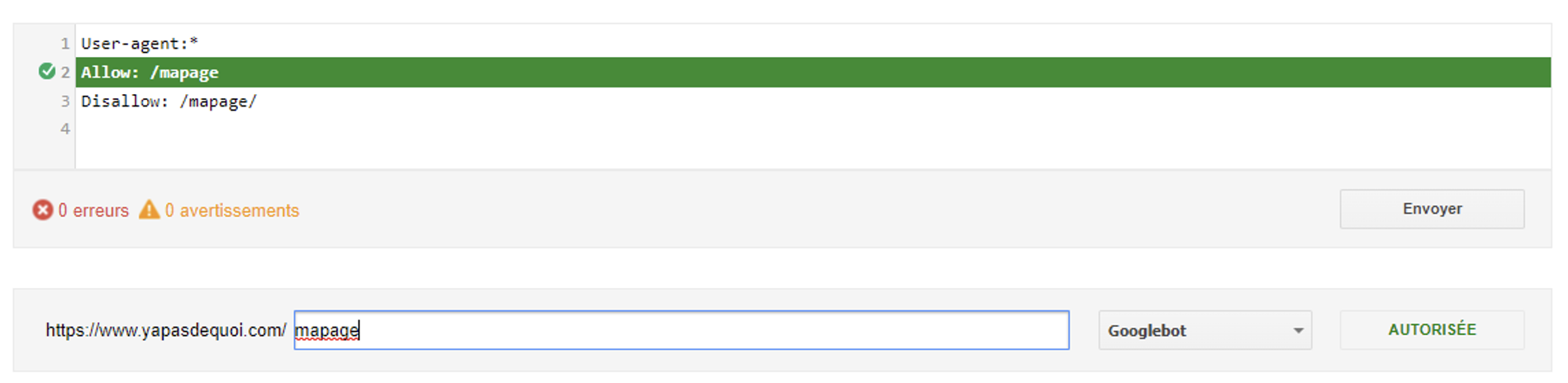
Possibilité de tester de nouvelles règles en direct sans modifier le fichier en ligne
Les autres moteurs proposent également leur propre outil de test, pour lesquelles il n’est pas possible de tester des règles en direct (fichier robots.txt sur le serveur utilisé) :
Bing : https://www.bing.com/webmasters/robotstxttester
Yandex : https://webmaster.yandex.com/tools/robotstxt/
En cas de maintenance
Une autre astuce intéressante concerne les sites Web en maintenance, qui peuvent renvoyer des erreurs 503. En cas de maintenance sur votre serveur (mise à jour de base de données, site en chantier, etc.), il peut être utile de renvoyer un statut HTTP 503 sur l’appel du fichier robots.txt. Cela mettra en pause les crawlers de Google de façon temporaire. Tant que le fichier « /robots.txt » répondra via un code 503, le crawl de Googlebot sera mis en pause jusqu’à ce que le fichier réponde à nouveau en 200.
Cela est utile dans la mesure où on limitera les sollicitations du serveur pour accélérer la phase de maintenance, et éviter que trop de ressources CPU soient occupées par le serveur Web et les requêtes de Googlebot.
Ressources
En complément, si vous vous intéressez à la façon dont Google interprète les fichiers robots.txt, la société a mis votre disposition l’analyseur (parser) utilisé par le moteur sur Github à cette adresse : https://github.com/google/robotstxt. Vous pourrez ainsi mieux comprendre le standard ERP (Robots Exclusion Protocol) si vous avez des connaissances en développement.
Accès aux différentes documentations relatives au robots.txt :
Google : https://developers.google.com/search/docs/advanced/robots/intro
Bing : https://www.bing.com/webmasters/help/how-to-create-a-robots-txt-file-cb7c31ec
Qwant : https://help.qwant.com/bot/
Yandex : https://yandex.com/support/webmaster/controlling-robot/robots-txt.html?lang=en
Baidu : https://www.baidu.com/search/robots_english.html

![]() Aymeric Bouillat, Consultant SEO senior chez Novalem (https://www.novalem.fr/)
Aymeric Bouillat, Consultant SEO senior chez Novalem (https://www.novalem.fr/)