

 Le contenu dupliqué sur Internet est un problème aussi vieux comme le Web lui-même. Une facilité absolue de copie (voire de pillage) de contenu propre à l’espace web multipliée par des constellations de solutions techniques non-optimisées comme les paramètres de tracking ou les erreurs humaines engendre des milliards de pages doublons à côté des pages déjà existantes. Ceci en fait une des tâches prioritaires à gérer par les moteurs de recherche. Et comme d’habitude, ce que veut Google se répercute inévitablement sur le travail des responsables SEO. Le mois dernier, nous avons passé en revue les différents types de contenus dupliqués, les algorithmes de détection et les particularités de traitement du contenu dupliqué par Google. Ce mois-ci, nous abordons les méthodes et outils permettant de l’identifier et bien sûr de le corriger.
Le contenu dupliqué sur Internet est un problème aussi vieux comme le Web lui-même. Une facilité absolue de copie (voire de pillage) de contenu propre à l’espace web multipliée par des constellations de solutions techniques non-optimisées comme les paramètres de tracking ou les erreurs humaines engendre des milliards de pages doublons à côté des pages déjà existantes. Ceci en fait une des tâches prioritaires à gérer par les moteurs de recherche. Et comme d’habitude, ce que veut Google se répercute inévitablement sur le travail des responsables SEO. Le mois dernier, nous avons passé en revue les différents types de contenus dupliqués, les algorithmes de détection et les particularités de traitement du contenu dupliqué par Google. Ce mois-ci, nous abordons les méthodes et outils permettant de l’identifier et bien sûr de le corriger.
 Le contenu dupliqué sur Internet est un problème aussi vieux comme le Web lui-même. Une facilité absolue de copie (voire de pillage) de contenu propre à l’espace web multipliée par des constellations de solutions techniques non-optimisées comme les paramètres de tracking ou les erreurs humaines engendre des milliards de pages doublons à côté des pages déjà existantes. Ceci en fait une des tâches prioritaires à gérer par les moteurs de recherche. Et comme d’habitude, ce que veut Google se répercute inévitablement sur le travail des responsables SEO. Le mois dernier, nous avons passé en revue les différents types de contenus dupliqués, les algorithmes de détection et les particularités de traitement du contenu dupliqué par Google. Ce mois-ci, nous abordons les méthodes et outils permettant de l’identifier et bien sûr de le corriger.
Le contenu dupliqué sur Internet est un problème aussi vieux comme le Web lui-même. Une facilité absolue de copie (voire de pillage) de contenu propre à l’espace web multipliée par des constellations de solutions techniques non-optimisées comme les paramètres de tracking ou les erreurs humaines engendre des milliards de pages doublons à côté des pages déjà existantes. Ceci en fait une des tâches prioritaires à gérer par les moteurs de recherche. Et comme d’habitude, ce que veut Google se répercute inévitablement sur le travail des responsables SEO. Le mois dernier, nous avons passé en revue les différents types de contenus dupliqués, les algorithmes de détection et les particularités de traitement du contenu dupliqué par Google. Ce mois-ci, nous abordons les méthodes et outils permettant de l’identifier et bien sûr de le corriger.Comment identifier le contenu dupliqué ?
Des multiples méthodes et outils, gratuits comme payants, sont à notre disposition pour identifier le contenu dupliqué.
Opérateurs de recherche de Google
C'est probablement la solution la plus simple et efficace, car elle ne demande pas de recourir aux outils spécialisés : prendre une séquence de 6-10 mots du texte, l’encadrer dans les guillemets (droits) et la saisir dans le champ de recherche de Google. Si notre site n’est pas positionné 1er, Google ne nous considère pas comme source et inévitablement dégrade en visibilité.
Les raisons peuvent être très variées et doivent dans ce cas être recherchées :
- Le texte que nous avons utilisé, n’était pas original au départ, mais copié d’une autre source.
- Notre texte est original, mais a été repris par un autre site (sans ou avec une mauvaise volonté).
- Il y a des problèmes d’accessibilité de notre page ce qui résulte au fait que Google préfère en choisir une autre plus stable.
- Notre site manque fortement en autorité et c’est le plus fort qui est sélectionné par Google.
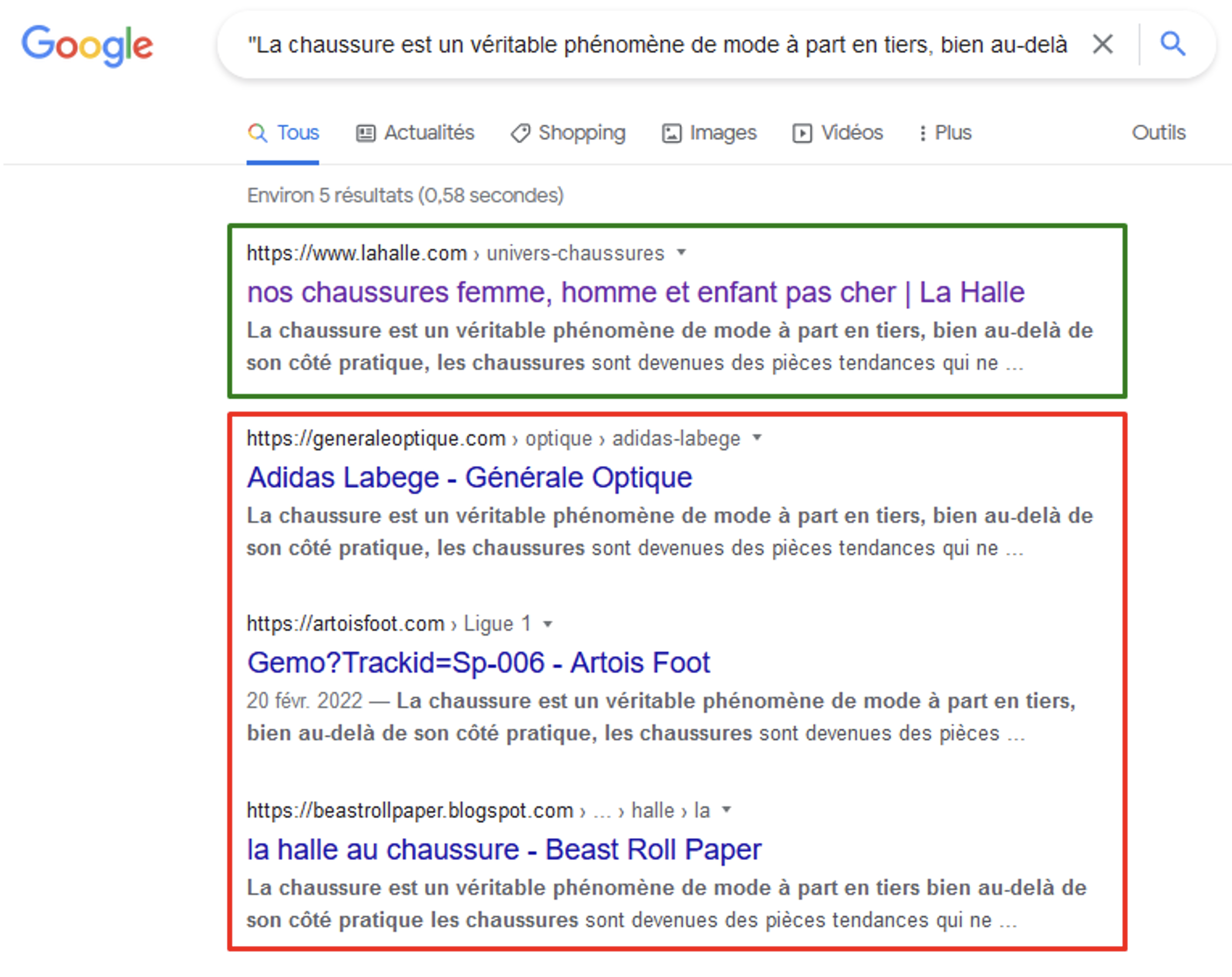
Le texte publié sur la page « Chaussures » de La Halle se retrouve en 1ère position sur la 1ère phrase.
3 autres sites auraient probablement copié le texte, néanmoins La Halle en est toujours considéré comme source.
En associant le passage cible dans les guillemets avec l’opérateur « site : », nous pouvons identifier des duplications internes :
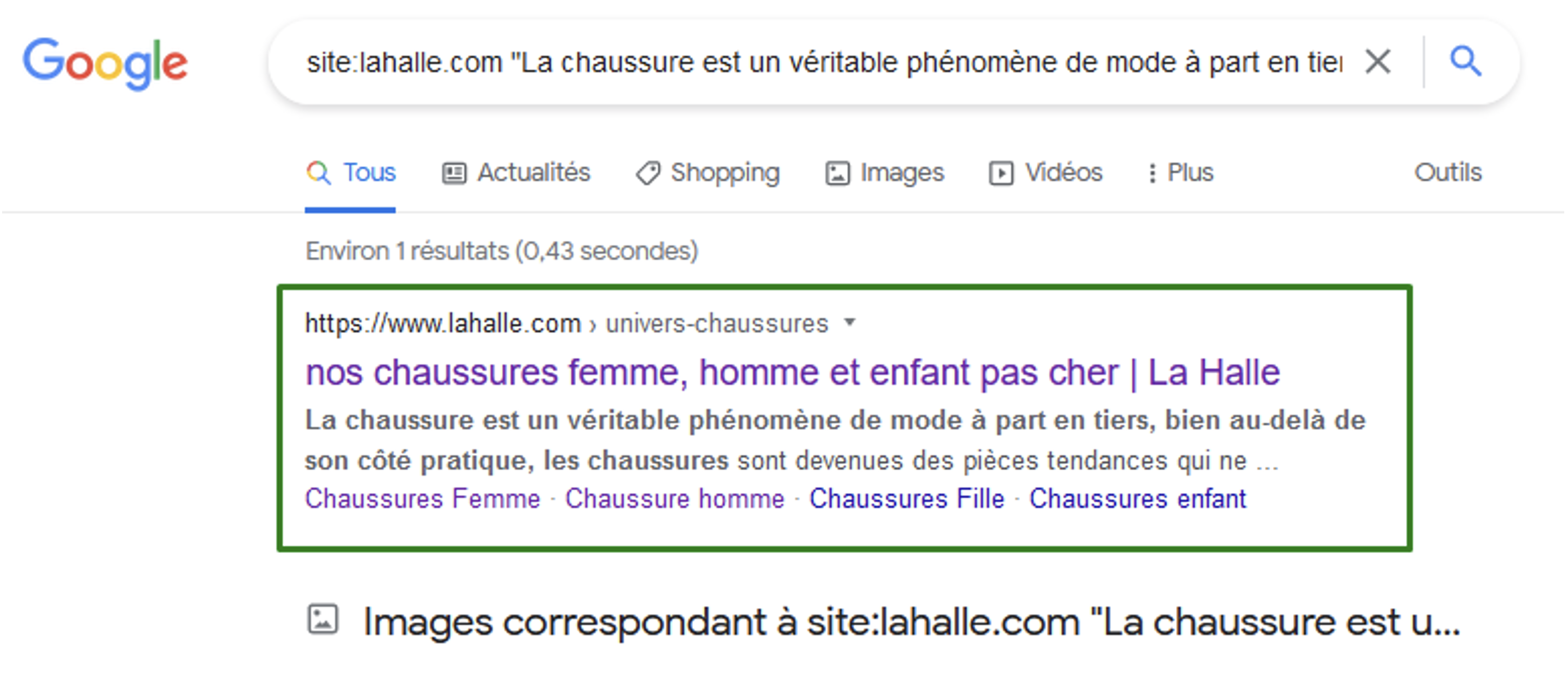
Sur la phrase cible au sein du domaine lahalle.com, une seule page est affichée :
il n’y a pas d’autres utilisations du texte sur d’autres pages du site.
Google Search Console
Le rapport de couverture de la Search Console depuis les dernières mises à jour affiche les détails sur les pages en double, notamment les erreurs possibles d’utilisation de l’attribut rel=canonical :
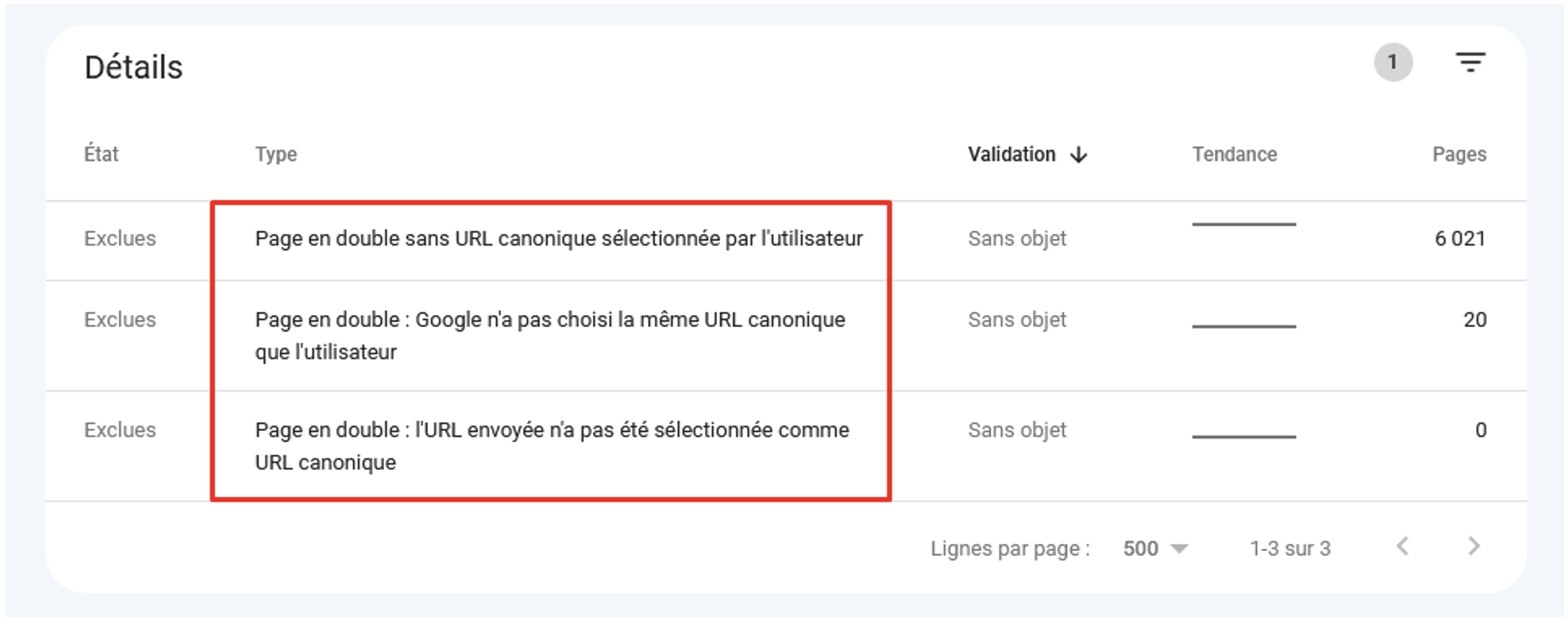
Cas de contenus en double signalés par la Search Console (Couverture > Pages exclues).
Pour 20 pages, Google a préféré ne pas respecter l’attribut rel=canonical dans le code source.
Screaming Frog SEO Spider
Pour permettre à l’outil de détecter les doublons partiels (avec l’algorithme de MinHash), il est nécessaire d’activer cette option dans : Configuration > Contenu > Doublons :

Activer la détection de doublons partiels dans Screaming Frog SEO Spider.
Screaming Frog permet de préciser la zone du contenu pour ne pas prendre en compte le mega menu par exemple (Contenu > Domaine) et le seuil à partir duquel la page sera considérée un doublon. Contrairement à la recherche de doublons exacts, cette fois-ci l'outil comparera le contenu textuel sans faire attention à ce comment celui-ci est mis en page.
Pour rappel, les valeurs de similarité ne sont pas visibles par défaut et nécessitent le lancement de l’analyse de crawl (Analyse de crawl > Commencer) :

Rapport de doublons partiels de Screaming Frog. Les pages sont triées par taux de similarité.
Copyscape
Lancé en 2004, Copyscape est un service de détection de plagiat en ligne qui vérifie si un contenu texte similaire apparaît ailleurs sur le Web.
Contrairement à la vérification dans résultats de Google, Copyscape ne vous dira pas si vous êtes reconnu comme source ou pas. Cependant, il est très utilisé par les fournisseurs de contenus payants pour détecter les cas d’utilisation illicite, même si le contenu a été réécrit. Copyscape permet de mettre en place des alertes pour être notifiées en cas de nouvelles utilisations de vos contenus.

Exemple de recherche sur Copyscape.
Siteliner
Si vous avez un petit site et souhaitez vérifier rapidement s’il y a des doublons internes, Siteliner développé par les équipes de Copyscape peut vous être utile. En version gratuite, vous pouvez analyser jusqu’à 250 pages. L’outil recherche à la fois les doublons exactes et partiels, néanmoins il prend en compte également les éléments transversaux du site.

Rapport de contenu dupliqué de Siteliner.
Killduplicate
Killduplicate permet de soumettre votre site et de veiller à l’apparition du plagiat ou de cas de vol de contenu. Directement depuis l’interface, vous pouvez réagir aux cas d’utilisation non-autorisée de vos contenus en contactant le propriétaire du site, son hébergeur ou en déposant une plainte DMCA auprès de Google.

Interface de Killduplicate.
Comment éviter ou corriger le contenu dupliqué ?
Lorsqu'il s'agit de prévenir ou de corriger tout type de problèmes SEO, il est toujours judicieux d'essayer de corriger la cause première du problème plutôt que de dissimuler les symptômes. Et le contenu dupliqué n’en est pas une exception.
Par exemple :
- Pour prévenir le problème de contenu dupliqué à cause des paramètres de tracking, penser à les introduire avec un hash (#) au lieu d’un point d’interrogation ou ampersand. Les urls avec # ne sont pas suivi par le robot de Google et des copies de pages ne sont pas ainsi créées.
- Pour prévenir le problème d’URLs dynamiques, penser à mettre en place en amont une structure d’URLs réécrites avec un ordre fixe. Ce n’est pas par hasard que les plus gros acteurs e-commerce mettent en place pour leurs pages produits les urls plates ne contenant pas de noms de catégories.
https://www.fnac.com/Apple-iPhone-13-6-1-5G-128-Go-Double-SIM-Noir-minuit/a16258373/w-4
https://www.courir.com/fr/p/jordan-air-jordan-1-low-bred-toe-1495129.html
https://www.zalando.fr/k-swiss-port-baskets-basses-blackwhite-ks112o02q-q11.html
- Mettre en place au sein du site les URLs relatives (/page/) permettra d’éviter plus tard des erreurs humaines de poses de liens avec ou sans www ou sur HTTP au lieu de HTTPS.
Dans le cas où ce n’est pas possible (trop cher, trop long, CMS obsolète etc.), différentes solutions techniques peuvent corriger ou réduire un éventuel impact négatif des cas de duplication.
- Redirections 301 – une solution radicale, mais très efficace pour les cas de figures où on n’a pas besoin de garder en même temps la page d’origine et la page dupliquée.
- Attribut rel canonical – une solution de support qui est utilisable dans les cas où l’internaute doit pouvoir accéder à la fois à la page source et la page dupliquée, par exemple la page AMP ou version mobile dédiée.
Lors de la syndication de contenu sur d’autres sites, ces derniers proposent souvent la mise en place de l’attribut rel canonical (Yahoo News ! et Medium permettent de le faire).
- La directive « noindex, nofollow » est la solution ultime pour désindexer le contenu dupliqué indésirable. On a tendance à le mettre en place sur les versions imprimables, passer dans les en-têtes des fichiers PDF si on n’a pas l’intention de les positionner.
Google pénalise-t-il les sites pour du contenu dupliqué ?
La position de Google concernant la pénalisation pour du contenu en double est similaire à tout autre type d'action sur le site. En soi, le contenu dupliqué, qui est souvent créé de manière involontaire et qui représente d'ailleurs près d'un tiers de toutes les pages sur Internet, n'est pas punissable.
En même temps, comme dans le cas des liens factices ou du cloaking, toute manière intentionnelle de tromper les utilisateurs ou de manipuler les résultats de recherche est passible de sanctions :
« En conséquence, le classement du site peut être affecté, ou le site peut être retiré définitivement de l'index Google, auquel cas il ne s'affichera plus dans les résultats de recherche » (source).
Les derniers cas de figure observés dans les résultats de recherche de Google confirment ces propos.
La propagation de widgets « Autres Questions Posées » dans les SERPs de Google a donné naissance à un mouvement jusque-là inédit de création de sites composés entièrement de questions et réponses scrapées automatiquement. Ces sites, ne produisant pas de contenus quelconques, republient en quantités énormes des réponses toutes faites depuis d’autres sites web.
Exemple 1 :
- lisbdnet.com – lancé fin 2021, en mars 2022 a dépassé 9 millions visites organiques (Semrush).
- le 25 avril 2022 la visibilité du site s’écroule.

Courbe de visibilité de Lisbdnet.com (source : Sistrix)

Au moment de rédaction de cet article, le site entier est désindexé.
Exemple 2 :
- Réseau de sites du même type avec avec faq-ans.com en tête (1,5 million de visites organiques par mois).
- Le 23 mai 2022, tous les sites du réseau se sont retrouvés désindexés dans Google.

Estimation du trafic organique des sites du réseau au 11 mai 2022.

Courbe de visibilité de Faq-ans.com (source : Sistrix)
Nous ne savons pas exactement quel type de sanctions a été infligé, manuelles ou algorithmiques. Cependant, ce qui est évident et certain, c’est qu’ils ont été pénalisés pour du contenu dupliqué déployé délibérément et tentative de manipulation de l'algorithme.
Conclusion
Le contenu dupliqué est l'un des sujets les plus importants auquel historiquement est confronté tout consultant SEO ou moteur de recherche. Avec une croissance exponentielle du Web chaque année, le problème ne fait que prendre de l’ampleur.
Du point de vue du moteur de recherche le contenu en double n'apporte pas de valeur ajoutée, gaspille des ressources de calculs au détriment de l’exploration des pages réellement utiles, occupe un espace de stockage, énorme à l’échelle du Web.
Quant aux propriétaires de sites et SEO, les enjeux sont aussi importants : le contenu dupliqué détourne Googlebot des pages prioritaires, perturbe la pertinence en faisant positionner les doublons, dilue la popularité précieuse dont les vraies pages auraient pu profiter.
Il est important de comprendre comment Google identifie et traite le contenu dupliqué, notamment les algorithmes de hachage, shingles et de clustering. Et évidemment, il faut garder en tête d’éventuelles pénalités qui peuvent être infligées par Google pour l’utilisation du contenu dupliqué à mauvais escient.

![]() Alexis Rylko, directeur technique SEO chez iProspect (https://www.iprospect.com/ & https://alekseo.com/)
Alexis Rylko, directeur technique SEO chez iProspect (https://www.iprospect.com/ & https://alekseo.com/)

 de nous rejoindre
de nous rejoindre