
Comme vu dans notre article du mois dernier, les enjeux d’une refonte de site web sont multiples et impactent de nombreux corps de métiers. Une refonte, c’est également l’occasion de faire mieux : remettre à plat ce qui a marché, ce qui a moins bien fonctionné, et analyser l’existant en vue de la migration des URL. Nous allons aborder dans cet article cette analyse de l’existant afin de faire un état des lieux des URL à rediriger (en cas de modification de leur structure), pour conserver le trafic SEO existant, voire même le faire progresser.
 Par Aymeric Bouillat
Par Aymeric BouillatAnalyser et prioriser les URL
En cas de modification d’URL, il sera nécessaire d’établir la liste des URL à rediriger, et de les prioriser pour ne pas passer à côté de celles ayant le plus de poids SEO. Afin de conserver la visibilité des URL les plus importantes, la première étape consistera à crawler l’ensemble du site à la manière de Google pour avoir une liste exhaustive des URL existantes, en récupérant des données liées aux performances de ces pages.
L’outil Screaming Frog Seo Spider est tout à fait adapté à cette tâche, puisqu’il est capable de simuler le passage d’un crawler comme GoogleBot pour récupérer l’ensemble des URL, tout en les associant à un certain nombre de KPI issus d’outils externes comme Google Search Console, Google Analytics (données trafic) ou encore Ahrefs et Majestic (données backlinks).
La figure 1 montre comment utiliser les connecteurs pour remonter un maximum d’informations pour chaque URL via cet outil.
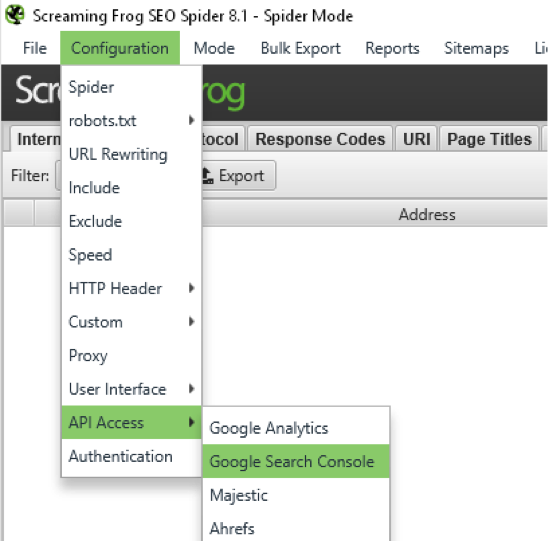
Fig. 1. Crawler le site en récupérant des informations issues d’outils externes.
Il vous faudra dans un premier temps autoriser l’accès à Screaming Frog SEO Spider aux API externes. Une fois l’outil autorisé à récupérer les données en provenance des API, sélectionnez le site à analyser (fig. 2).
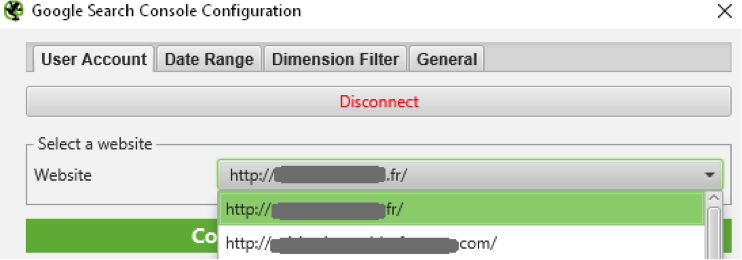
Fig. 2. Connexion de Screaming Frog Seo Spider à l’API Search Console.
Plusieurs options sont disponibles dans les onglets de chaque API (Date Range, Dimension Filter, General pour Google Search Console). Il est préférable de travailler sur les données des trois derniers mois, pour avoir un peu d’historique, et de sélectionner l’association entre les URL avec et sans trailing-slash pour limiter le traitement des doublons. Vous pourrez également ne pas tenir compte de la casse dans le cas où votre site gère indifféremment ce type d’URL au niveau du serveur.
La connexion à une API telle que Google Analytics peut être pertinente dans certains cas, afin de remonter des URL qui ne seraient pas visibles dans la Google Search Console, mais qu’il serait utile de rediriger malgré tout dans une stratégie plus globale (URL d’affiliation, URL publicité, URL générant du trafic via des sites référents, etc.)
Une fois les éléments de base du crawl configurés (respect du robots.txt, vitesse de crawl, type de ressources à crawler, etc.), vous pouvez lancer votre crawl afin de récupérer l’ensemble des KPI relatifs aux URL de votre site, une connexion à une API d’analyse de liens entrants tel que Ahrefs ou Majestic serait un plus, pour prendre en compte les URL générant peu de trafic mais recevant des liens de qualité, et pouvant transmettre de la sémantique à votre site via les ancres de liens.
La totalité des données pourra être exportée au format XLSX (Excel) plutôt que CSV, ce dernier posant parfois des problèmes lors de l’importation sous Excel. Vous aurez ainsi votre base de travail en vue de la mise en place du plan de redirections (fig.3).
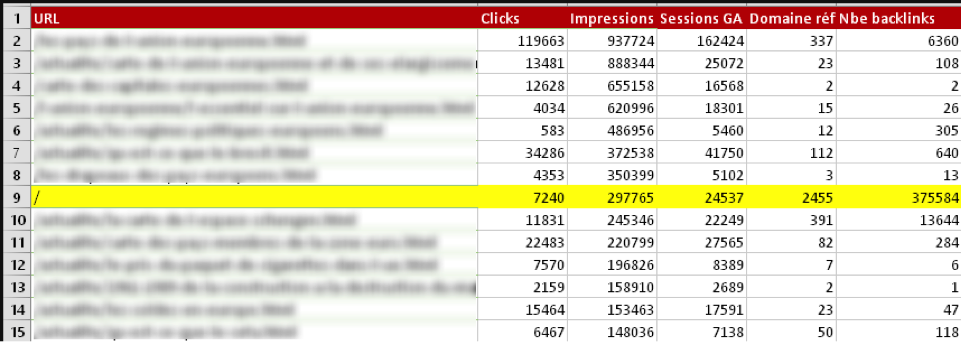
Fig. 3. URL les plus performantes à rediriger en priorité.
Tenir compte de toutes les URL : utiliser différentes sources
Certains types d’URL qui ne seraient pas détectées par défaut par Google Analytics comme les .pdf par exemple, peuvent être remontés via des outils comme Google Search Console. Des URL qui ne sont plus exploitées dans le maillage du site peuvent également recevoir des liens externes et générer du trafic, soit via le SEO, soit via les sites référents entre autres.
![]() Aymeric Bouillat
Aymeric Bouillat
Consultant SEO Senior, SEO Hackers (https://seohackers.fr/)




![Copyright Trolling en France : comprendre et contrôler les abus d’une pratique controversée [Partie 2] - Stéphanie Barge](https://www.reacteur.com/content/uploads/2024/05/2024-05-reacteur-stephanie-barge.png)
![Copyright Trolling en France : comprendre et contrôler les abus d’une pratique controversée [Partie 1]- Stéphanie Barge](https://www.reacteur.com/content/uploads/2024/04/2024-04-reacteur-stephanie-barge.png)

