
Vous avez un site web et vous proposez donc en ligne un contenu qui représente une certaine valeur – financière ou autre – à vos yeux. Dans ce cas, il y a de fortes chances pour que d’autres personnes, plus ou moins bien intentionnées, mettent en place des procédures automatisées et des robots pour « scraper » (copier/coller) vos informations afin de les utiliser sans votre accord. Pourtant, il existe des méthodes pour éviter ce vol potentiel ou pour le surveiller, afin d’agir par la suite. En voici quelques-unes…
 Par Benoît Chevillot
Par Benoît ChevillotIntroduction
Le web grandit et grossit à une vitesse incroyable, de plus en plus de services sont interconnectés via les API (Application Programming Interface), permettant de récupérer les données de manière standardisée. Que vous ayez besoin de récupérer des données web de manière innocente, légitime ou illégitime, il est encore dans de nombreux cas nécessaire de récupérer la donnée par ses propres moyens. : c’est à dire en scrapant.
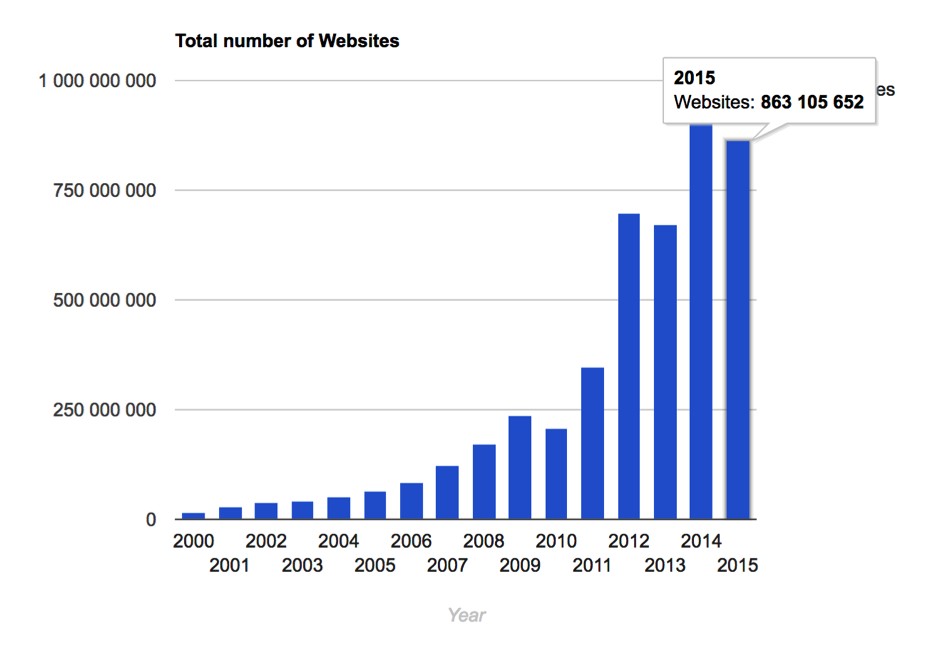
Fig.1 Nombre de sites sur le Web. Source : http://www.internetlivestats.com.
Le scraping est vieux comme le Web et le seul moyen de récupérer une donnée depuis un autre site web (à la genèse du web tel que nous le connaissons) était de récupérer la page via un outil spécialisé ou simplement via son bon vieux navigateur en enregistrant la page sur son disque dur local.
Tous les outils nécessaires pour extraire et traiter la donnée étaient déjà présent : Curl, Xpath, … (Xpath 1.0 est une recommandation W3C depuis le 16 Novembre 1999, la première version de Curl date de 1997).
Les outils classiques pour contrôler le scrap sur son site (robots.txt, user agent) sont arrivés en même temps que le Web (1994 pour robots.txt et 1989 pour http).
Puis, rapidement, sont arrivés les « aspirateurs de sites » qui ne faisaient pas dans le détail et récupéraient tout un site de manière massive, comme Httrack (1998).
![]() Benoît Chevillot
Benoît Chevillot
Consultant SEO, DivioSeo (http://divioseo.fr)




![Copyright Trolling en France : comprendre et contrôler les abus d’une pratique controversée [Partie 2] - Stéphanie Barge](https://www.reacteur.com/content/uploads/2024/05/2024-05-reacteur-stephanie-barge.png)
![Copyright Trolling en France : comprendre et contrôler les abus d’une pratique controversée [Partie 1]- Stéphanie Barge](https://www.reacteur.com/content/uploads/2024/04/2024-04-reacteur-stephanie-barge.png)

