
Lors du récent SEO Camp’us, Sylvain Peyronnet et Kevin Richard ont présenté les résultats d’une étude à grande échelle qu’ils ont réalisée pour tenter de comprendre quels sont les vrais critères de pertinence d’un moteur de recherche comme Google. Cet article explique l’objectif de cette étude, la méthodologie utilisée ainsi que ses principaux résultats et les conclusions qu’on peut en tirer en termes d’importance relative d’un critère par rapport à un autre. Avec à la clé la fin de quelques mythes sur le SEO…
Ce mois-ci nous allons aborder un sujet que nous avons évoqué lors de la dixième édition du Seo Camp’us et plus précisément lors de la conférence « Les SERPs ont parlé : comment font ceux qui performent en 2018 ? » par Kevin Richard (créateur de l’outil Seobserver [1]) et Sylvain Peyronnet (votre humble serviteur).
L’objectif de cette conférence était de faire un retour assez succinct sur les résultats d’une étude des sites qui se positionnent bien en 2018, et grâce à Abondance, nous pouvons ici en donner une vision plus complète dans ces pages, pour le plus grand nombre.
Nota : Tous les résultats présentés dans ces articles ont été obtenus par le duo Kevin Richard – Sylvain Peyronnet.
L’objectif : valider ou invalider des hypothèses concernant les critères de positionnement
Le sujet de discussion préféré des référenceurs web est bien entendu Google et les positions des sites. Et il n’est pas rare de lire tout et son contraire concernant les trucs et astuces qui permettent de bien se positionner : il faut des liens, il ne faut pas de liens pourris, il faut du contenu, mais il faut du bon contenu, il faut remplir la meta keywords, ou pas, il faut… etc. Bref, un vrai folklore existe autour des critères de ranking, et c’est seulement par des études statistiques complètes qu’on peut espérer réussir à comprendre ce qui est important pour le moteur, et surtout ce qui ne l’est pas.
Tout d’abord, qu’est-ce qu’une étude statistique des critères de positionnement ? C’est finalement assez simple : il s’agit de prendre un grand nombre de mots-clés, un grand nombre de pages web plus ou moins bien positionnées pour ces mots-clés, puis d’analyser les caractéristiques de ces pages pour déterminer ce qui a été important pour le moteur dans la création des SERP associées.
Au delà de la méthodologie que l’on va expliquer plus en détails dans la suite de cet article, ce qui va compter est de formuler puis de valider ou invalider des hypothèses issues de notre expérience métier.
La méthodologie : quels mots-clés ?
La première question que nous nous sommes posée est celle de la typologie des mots-clés à utiliser. En effet, il est très largement probable que certains types de mots-clés soient traités différemment par un moteur comme Google car ils sont porteurs d’une intention spécifique de l’internaute. Par exemple, les mots-clés indiquant une marque sont dans ce cas. Nous avons ainsi choisi d’exclure de notre étude les mots-clés navigationnels (dont les marques font partie).
C’est Kevin Richard qui a créé cette méthodologie. Basiquement, on pourrait croire que c’est la présence d’une box de knowledge graph qui va permettre de déterminer l’intention navigationnelle d’un mot-clé, mais en pratique ce n’est pas du tout le cas. Nous allons utiliser deux caractéristiques structurelles de la SERP :
- La présence d’un big snippet (liens de site ou Sitelinks). En effet, les sites bénéficiant d’un big snippet pour une requête sont des sites de type marque avec la requête en intention navigationnelle.
- La présence du même domaine de manière très importante dans la SERP, par exemple sur les 5 premiers résultats. Dans ce cas la requête est significativement navigationnelle pour le moteur.
Ensuite, nous avons pris un échantillon de 20 000 requêtes, triées par intérêt décroissant. Qu’est-ce que l’intérêt ? C’est un mix entre le CPC, la compétition et le volume de recherche de la requête. En utilisant cette métrique, on peut ainsi savoir si une requête va être susceptible de donner lieu à “la compétition SEO”. Nous nous sommes assurés d’avoir des requêtes “importantes” et d’autres moins “cotées”.
La méthodologie : quels sites et quelles caractéristiques ?
S’agissant d’une étude des critères de positionnement des sites web, l’étape suivante est bien entendue de décider quels sont les sites web qui seront analysés. Pour aller au plus simple, nous avons pris les 100 premiers résultats selon Google pour les requêtes choisies plus haut. Ainsi nous avons pris en compte le top 100 de chaque requête.
Concernant les caractéristiques, nous en avons analysé un grand nombre :
- Présence du site dans le top Similarweb.
- Eléments de réassurance présents sur le site.
- Site en HTTPS, avec de la publicité adsense ou un tag analytics.
- Présence d’un favicon.
- TrustFlow (TF) et CitationFlow (CF) de l’URL.
- TF et CF du domaine.
- Plus globalement la plupart des métriques liées aux liens, comme par exemple le nombre de liens référents en follow, le nombre de domaines référents, par type de liens (homepage ou ailleurs par exemple).
- Les rangs en terme de métriques au niveau de la SERP. En effet, il semble que ce qui compte n’est pas tant la valeur du CF ou du TF que la rang de cette valeur parmi les compétiteurs. En effet, si la compétition pour un mot-clé se situe entre des sites avec des petites valeurs de CF, peut-être suffit-il d’un CF moyen pour être bien positionné, ce serait donc la valeur relative qui serait importante.
La plupart de ces informations sont des données fournies par Majestic. Et c’est grâce à ces données que l’on va pouvoir élaborer sur les critères de positionnement par la suite.
La méthodologie : quels outils d’analyse ?
Pour étudier ces données, il n’existe pas d’outil universel qui permette de tirer des conclusions définitives. C’est au contraire l’utilisation de plusieurs outils qui va nous permettre de trouver de “l’intelligence” dans cette data. Pour cela, nous allons faire :
- De l’analyse toute bête en regardant des proportions et en calculant des pourcentages.
- Des diagrammes de corrélation pour déterminer les métriques qui sont “similaires”.
- Des forêts de décision avec Random Forest pour voir si on peut prédire les positions, de manière fine ou plus grossière.
Le dataset : quelques faits…
Tout d’abord, après nettoyage des données mal formées, notre dataset contient environ 1,6 millions de lignes, chacune correspondant à un couple requête – URL.
Les TF que l’on retrouve pour toutes ces URLs vont de 0 à 98, avec un médian à 8 et une moyenne à 10,97 : en moyenne les TF sont plutôt bas.
Les CF des URLs vont de 0 à 92, avec une médiane à 16, et une moyenne à 15,77 : les CF sont sensiblement plus hauts que les TF.
Le ratio moyen entre TF et CF est de 0.51, mais on retrouve un ratio maximum de 3.33 : il existe au moins un site dont le TF est plus du triple du CF !
Lorsque l’on regarde la même information pour les domaines, les chiffres grimpent : les TF vont alors de 0 à 100 avec un médian à 27 et une moyenne à 32.53, tandis que les CF vont de 0 à 100 avec un médian à 36 et une moyenne à 37.65. Le ratio moyen est alors de 0.797, avec un maximum à… 12 !
Notre dataset contient des sites qui ne sont pas nécessairement en français (car des sites étrangers à très fortes métriques se positionnent sur des mots-clés francophones), nous allons les exclure pour la suite. Au final, nous allons utiliser un dataset qui contient environ 1 million de lignes.
Nous avons ensuite analysé les “petits” critères de positionnement. Pour voir s’ils ont un impact, un test très simple est à faire : calculer le pourcentage de sites dans le top1, top3, top5, top10, etc. qui possèdent le critère en question.
Par exemple, si on prend le critère de présence d’un élément de réassurance type mention légales ou autre, on voit qu’environ 75% des URLs du dataset le possède, mais que ce pourcentage est de 75% aussi pour les top20, top10, et ensuite 76 ou 77% pour les top5, top3 et top1. Avec les zones d’incertitude de mesure, ces valeurs sont toutes finalement indiscernables, et il n’y a donc aucun biais favorable ou défavorable au positionnement lié à des éléments de réassurance…
Concernant les autres critères de ce type, nous avons pu montrer que :
- Il existe un très léger biais en faveur du mot-clé dans le Title quand on monte dans le classement (presque 58% de présence globalement, mais 62% pour les 20 premières positions et jusqu’à 65% pour le top1, la première position).
- La présence d’Adsense, d’Analytics ou d’un favicon n’a aucun lien avec le positionnement.
- Les sites bien placés par Similar web ont tendance à être bien positionnés dans les SERP de Google.
- Il y a plus de sites en HTTPS dans les sites bien positionnés (attention, on rappelle que corrélation et causalité sont deux choses différentes !).
Bref, avec quelques calculs de pourcentages, on peut voir des biais (des corrélations donc) entre quelques critères simples et le positionnement.
Corrélation : on ne voit rien ! ou presque…
Puisque l’on est concentré sur la notion de corrélation, continuons d’explorer cet aspect, via un immense diagramme de corrélation.
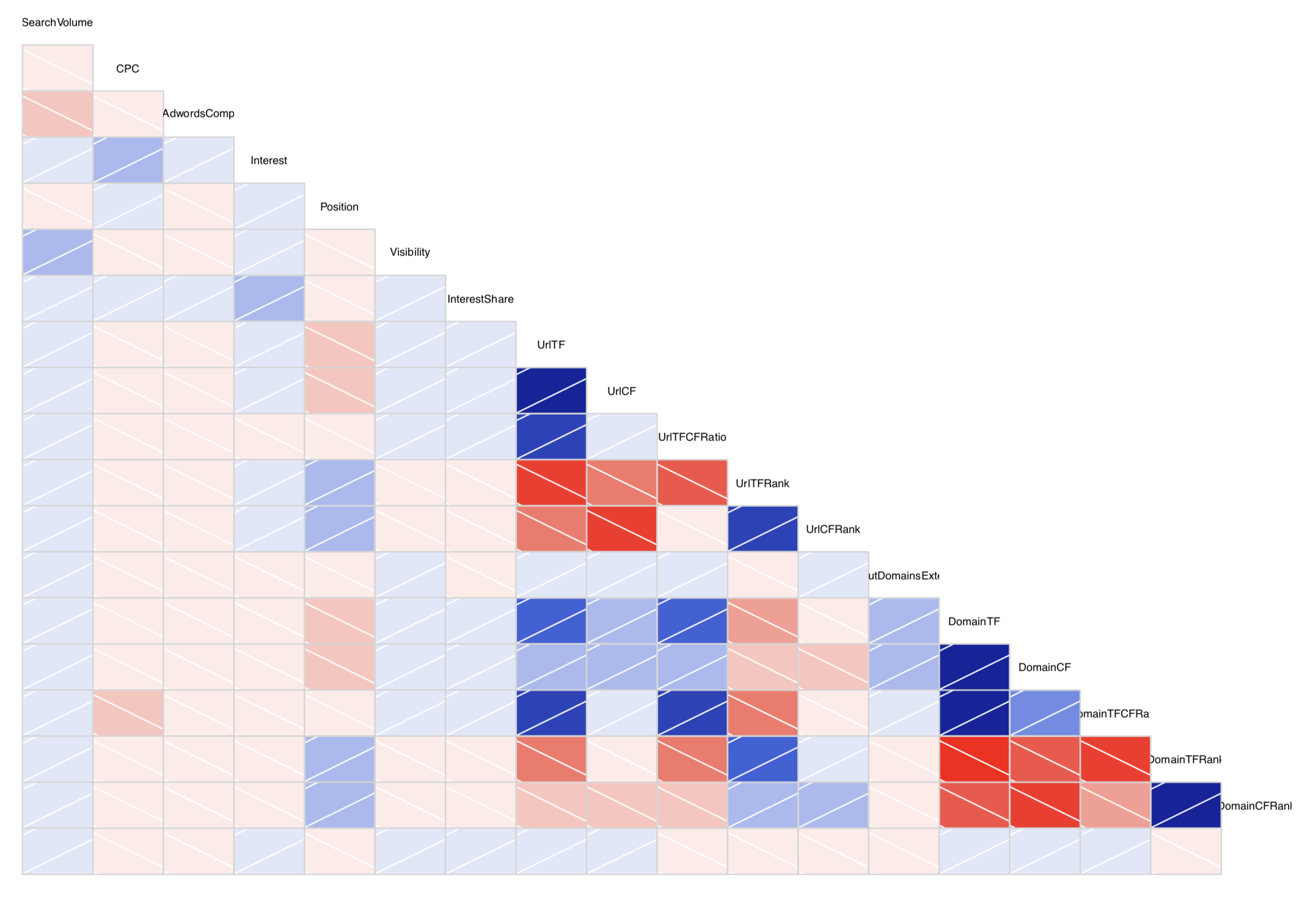
Fig.1. Diagramme de corrélation des métriques sur le dataset complet.
Un diagramme de corrélation est un graphique qui permet de voir les variables qui sont “en relation”. Chaque case correspond à un couple de variables observées (ici nos métriques type TF, CF, etc.) et plus une case est foncée, plus la corrélation est forte.
Quand la case est rouge, la corrélation est négative : lorsqu’une variable monte, l’autre descend. En revanche, une case bleue indique une corrélation positive : les deux variables montent et descendent ensembles.
La figure 1 est le diagramme de corrélation associé à notre dataset. On ne constate pas de corrélation très forte en dehors de celles qui sont très attendues comme par exemple le CT et le TF ensemble (les deux ont tendance à augmenter ensemble, même si ce n’est pas à la même vitesse). En dehors de cela, on ne peut pas dire grand chose, à part sur un point amusant : il existe une corrélation entre le CPC et le ratio TF versus CF du domaine. C’est en fait assez naturel : plus une thématique est compétitive, plus la pratique va être de faire des opérations de netlinking offensive, avec donc un ratio adapté.
La seule conclusion à ce stade est qu’il va falloir faire une analyse plus fine, en utilisant des outils plus efficaces, issus du machine learning.
Random forest : on commence à y voir plus clair
L’outil que nous avons choisi pour cette étude est Random Forest (voir [2] pour l’article de Wikipédia correspondant). Si nous avons choisi cet algorithme de machine learning, c’est pour sa capacité à classer les variables par ordre d’importance (voir l’article original [3] de Breiman à ce propos).
Nous n’allons pas expliquer ici comment fonctionne Random Forest, ni comment l’utiliser en détail. Il s’agit tout simplement d’utiliser une des nombreuses implémentations sur notre dataset. Nous avons choisi ici d’utiliser l’implémentation standard en R (plus d’informations sur R et Random Forests en R dans les références [4] et [5]).
Si en pratique vous voulez refaire ce type d’étude, il est cependant conseillé de se faire assister la première fois pour éviter certains écueils méthodologiques (il faut notamment retravailler le dataset pour assurer que les classes de positions soient “balancées”, c’est-à-dire de tailles équivalentes en terme d’échantillonnage).
La figure 2 présente le classement de l’importance des variables pour des prédictions différentes. 4 types de prédictions y sont présentées : tout d’abord le top1, c’est-à-dire que l’on veut prédire quelle sera l’URL placée en première place dans la SERP, ensuite le top3 qui permet de prédire si une URL sera dans les trois premières, le top5 pour les 5 premières et le top10 pour les 10 premières. Plus la barre verte est grande plus la variable est importante pour prédire le top en question.
Première constatation : plus on veut prédire “large”, plus le pourcentage d’erreur augmente. Mais nonobstant ce phénomène, on voit que dans tous les cas, le signal le plus important reste le rang en termes de CF de l’URL. Sur les signaux suivants, les choses sont moins claires. On voit que le rang en termes de CF du domaine intervient, mais aussi celui en terme de TF. Il semble bien que le CF pour l’URL et le domaine soit le critère le plus important, suivi du TF pour le domaine pour passer une URL dans le top10, et que ce qui va arbitrer entre les pages du top10 sera le nombre de domaines référents.
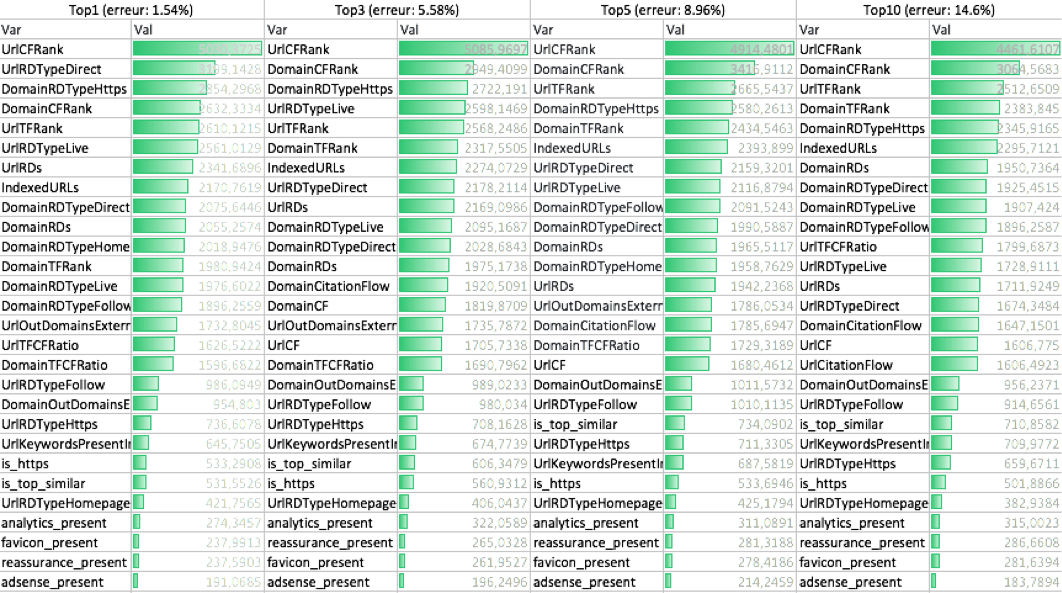
Fig.2. Importances des variables selon les classes à prédire.
Glossaire
Les métriques présentées dans la figure 2 étant désignées de manière un peu cryptiques, voici une explication plus fine de ce qu’elles sont :
- UrlCFRank et UrlTFRank : il s’agit du rang dans la SERP à 100 positions de la page en terme de CF (ou TF), c’est donc un nombre entre 1 et 101.
- DomainCFRank et DomainTFRank : même notion que ci-dessus, mais au niveau du domaine.
- UrlRDs et DomainRDs : il s’agit du nombre de domaines référents vers l’URL ou vers le domaine.
Parfois il existe un typage qui suit, par exemple DomainRDTypeDirect, il s’agit alors des domaines référents vers le domaine, qui sont de type direct. Pour en savoir plus sur chacun des types, il faut se diriger vers le site de Majestic car il s’agit des types de référents de cet outil. - IndexedURLs : nombre d’URLs indexées pour ce domaine.
- UrlOutDomainsExternal et DomainOutDomainsExternal : nombre de liens sortants, en terme d’URLs différentes ou de domaines différents.
- UrlTFCFRatio et DomainTFCFRatio : ratio TF sur CF de l’URL ou du domaine.
- Les derniers critères sont les critères simples : présence d’Adsense, d’Analytics, d’un favicon, etc. Ils sont assez clairs dans leur nommage.
On voit également que les rangs sont plus importants que les valeurs absolues : il faut être la meilleure des pages éligibles au positionnement plutôt que de dépasser des valeurs “symboliques”. En terme de SEO, les phrases du type “il faut un CF au dessus de 20” ne sont finalement que de la poudre de perlimpinpin.
Enfin, on voit sur ce tableau que les critères hors linking (analytics, HTTPS, etc.) sont en bas du classement : ils sont moins important que le linking.
Une question que les SEOs se posent souvent est celle de faire ou non des liens vers des sites externes. Cette étude montre que la question n’a pas lieu d’être : en faire ou ne pas en faire ne changera pas le positionnement, ou alors à la marge.
Cette étude a un manque évident : il n’y a pas de prise en compte de la sémantique dans les signaux monitorés. Dans une étude indépendant menée pour analyser l’impact d’un outil de sémantique comme YourText.Guru [6], nous avons montré que la sémantique est un critère important lorsque les métriques de linking (CF et TF) sont plutôt de valeurs faibles ou moyenne, mais qu’au delà d’un certain stade, le linking va nettement surpasser la sémantique.
Même si le discours des moteurs est de dire que le contenu est roi, cela reste discutable pour les pages à très forte popularité.
Enfin, un dernier signal n’est pas mesurable du tout : c’est le signal de qualité perçue par les utilisateurs. Ce signal dépendant de l’interaction des utilisateurs avec l’ensemble de la SERP, il n’est pas possible de l’estimer sans être le moteur lui-même.
Conclusion : les leviers principaux
Au final, que peut-on conclure d’une telle étude ? Un petit nombre de faits :
- Les métriques de l’URL sont importantes. Beaucoup de SEO pensent que le moteur va donner plus d’importance au domaine qu’aux pages, c’est faux, la popularité de la page, et en particulier le fait d’être parmi les plus populaires, est le critère le plus important.
- En terme de métriques liées au domaine, c’est le TF qui est important pour rentrer dans le top 10, mais ensuite ce n’est plus une variable d’arbitrage aussi importante.
- On peut faire des liens vers des sites externes sans craindre des pertes de positions, mais cela n’en fera pas gagner non plus.
- La ratio TF/CF est une métrique qui permet de détecter le spam.
Voilà de quoi méditer en attendant la prochaine lettre !
References
[1] https://www.seobserver.com/
[2] https://fr.wikipedia.org/wiki/For%C3%AAt_d%27arbres_d%C3%A9cisionnels
[3] http://chem-eng.utoronto.ca/~datamining/dmc/docs/rf.pdf
[4] https://www.r-project.org/
[5] https://cran.r-project.org/web/packages/randomForest/randomForest.pdf
![]() Sylvain Peyronnet, fondateur de la régie publicitaire sans tracking The Machine In The Middle (http://themachineinthemiddle.fr/).
Sylvain Peyronnet, fondateur de la régie publicitaire sans tracking The Machine In The Middle (http://themachineinthemiddle.fr/).






![Copyright Trolling en France : comprendre et contrôler les abus d’une pratique controversée [Partie 2] - Stéphanie Barge](https://www.reacteur.com/content/uploads/2024/05/2024-05-reacteur-stephanie-barge.png)
![Copyright Trolling en France : comprendre et contrôler les abus d’une pratique controversée [Partie 1]- Stéphanie Barge](https://www.reacteur.com/content/uploads/2024/04/2024-04-reacteur-stephanie-barge.png)


4.5