

L’algorithme BERT nous a montré, il y a quelques mois de cela, que les moteurs de recherche actuels avançaient rapidement en termes de compréhension de la requête et de l’intention de recherche de l’utilisateur. Mais de nouveaux travaux et brevets, notamment autour de l’antique PageRank, nous montrent que l’importance de la richesse sémantique et la qualité des contenus devient elle aussi capitale pour obtenir une visibilité optimale. Et il en sera certainement de même à l’avenir. Plongée dans l’univers des nouveaux algorithmes…
 Par Sylvain Peyronnet
Par Sylvain Peyronnet
Le sujet du PageRank est un sujet que nous avons déjà abordé à plusieurs reprises dans ces pages il y a maintenant plusieurs années (c’était notamment le cas en mars 2017 dans le troisième article du cyle sur les algorithmes des moteurs de recherche). A l’époque, nous avions abordé la notion de surfeur aléatoire (que je vais rappeler très brièvement ici) et celle de PageRank thématique.
Le surfeur aléatoire ne date pas d’aujourd’hui ni même d’hier, mais plutôt d’avant-hier 😉 C’est en effet en 1998 que les auteurs de la référence [1] (Larry Page et Sergey Brin en tête) mettent en avant ce modèle. L’évolution en un modèle thématique basé sur un ensemble de thématiques choisies à l’avance est dûe à Taher Haveliwala et date de 2003, avec mise en application autour de 2007. Comme on le voit, là aussi ce n’est pas très récent.
Mais que s’est-il passé ensuite ? Est-ce qu’il y a eu de la nouveauté ? Oui bien sûr. Tout d’abord Google a fait passer un brevet sur la notion de PageRank raisonnable (en 2012) que nous avons évoqué en décembre 2017 dans ces mêmes pages. Mais après ? Pendant plusieurs années, notre seule possibilité était de spéculer, mais il y a eu récemment plusieurs publications scientifiques, souvent très techniques, qui donnent des pistes extrêmement importantes (et parfois impactantes) sur la vision actuelle du PageRank pour un moteur à l’échelle de ce qu’est Google.
C’est de cela dont nous allons parler dans cet article.
Back to the future : pour se rafraîchir la mémoire
L’idée du PageRank est de quantifier la popularité, qui est une notion liée au comportement des internautes, de manière formelle. Pour cela, les auteurs de l’algorithme ont créé un modèle mathématique de l’internaute : le surfeur aléatoire. Le PageRank va alors “compter” la fréquence de passage du surfeur aléatoire sur chaque page web, et c’est cela qui va donner une popularité à chacune des pages.
Concrètement, le surfeur aléatoire voyage de pages en pages en suivant les liens au hasard, mais de temps en temps (15% du temps selon l’article d’origine de Page et Brin) il va se “téléporter”, c’est-à-dire que plutôt que de suivre un lien au hasard, il va sauter sur une page web choisie au hasard dans l’index du moteur.
Cette notion de surfeur aléatoire a une incidence très forte sur le netlinking (pour en savoir plus sur le sujet, je vous envoie vers les précédents numéros de réacteur, ou vers le chapitre du livre [4]).
Quelques années après Brin et Page, Taher Haveliwala révolutionne la notion de PageRank avec le PageRank thématique. Sans entrer dans les détails, il suffit de savoir que l’idée est de moduler la probabilité de suivre un lien sur une page par la proximité en termes de thématique de la page source du lien et de sa page cible. Par exemple, si le surfeur aléatoire s’intéresse à la thématique des voitures, et que depuis un site qui parle de voiture il a le choix de suivre un lien vers un site sur la réparation des voitures ou un lien vers un site qui parle de location de villa, il y a une plus grande chance qu’il suive le premier lien plutôt que le second.
Cette notion de PageRank thématique a eu un impact important (lors de l’update Caffeine) pour le SEO. A partir de sa mise en action, il a fallu que les opérations de netlinking soient faites avec des liens thématisés. On notera aussi, pour la petite histoire, que c’est le PageRank thématique qui est le “moteur” de ce que l’on appelle souvent le cocon sémantique.
Enfin, la dernière modification bien connue est celle du surfeur raisonnable : on va pondérer les liens selon leur emplacement dans la page. Un lien au sein du contenu aura alors plus de pouvoir de transmission de popularité que (par exemple) un lien dans le footer.
Tout cela, c’est connu et c’est le passé, mais où en est-on aujourd’hui ?
Il existe toujours une abondante littérature scientifique sur le sujet du PageRank, mais c’est très récemment (en avril 2020) qu’a été présenté un article très intéressant [5], assez judicieusement intitulé “Scaling PageRank to 100 Billion Pages”. L’auteur de cet article est Stergios Stergiou, dont vous n’avez sans doute jamais entendu parler. Il est d’abord passé par Yahoo et est chez Google depuis quelques mois seulement, mais il a déjà à son actif plusieurs faits d’armes spectaculaires dans la mise en place massive d’algorithmes pour le Web (avec par exemple la mise en oeuvre de Word2vec sur 10 milliards de documents avec des temps de calcul de 2h par itération). Nous allons donc commencer par parler de l’article piblié à cette occasion.
Le PageRank sur plus de 100 milliards de pages
Résumer un algorithme complexe capable de calculer le PageRank sur autant de pages n’aurait pas de sens ici (c’est bien trop technique). Ce qu’il faut savoir, c’est tout simplement qu’à ce niveau de taille de graphe, c’est une forme de simulation locale du surfeur aléatoire qui permet de réaliser le calcul. Dans le passé, on (les SEOs, mais aussi les autres) présentait souvent une belle équation pour le calcul du PageRank. Pour un graphe de plusieurs dizaines voire centaines de milliards de pages, c’est n’est plus réellement possible de voir le PageRank comme la solution d’une seule équation.
D’un point de vue intuition, le graphe du web va être distribué sur plusieurs machines de calcul. On va “simuler” localement le PageRank, mais parfois il faudra que le surfeur aléatoire “passe” d’une machine à l’autre. Comme fera-t-il ? Il doit accéder à des données qui sont sur d’autres machines, et pour faciliter le calcul, de savants calculs sont faits pour ne pas utiliser des index énormes pour faire passer le surfeur aléatoire. C’est un peu comme si on avait un répertoire téléphonique qui sait prédire qui on a le plus de chance d’appeler quand on veut passer un coup de téléphone : la plupart du temps il nous fera gagner du temps, mais parfois on devra naviguer dans une longue liste de contacts car on cherchera exceptionnellement à joindre quelqu’un qu’on ne contacte jamais.
Étonnamment, cela peut avoir un impact pour le SEO : si on veut avoir des métriques de popularité qui sont correctes le plus rapidement possible, on a intérêt à se positionner dans un ensemble de pages qui sont déjà bien connecté entre elles. C’est sans doute un effet très à la marge, mais cela vaut le coup d’avoir très rapidement plusieurs liens venant d’un même voisinage pour avoir un calcul plus rapide (quand on dit très à la marge c’est que l’on parle de gagner quelques heures au mieux).
Les performances de l’algorithme de Stergiou sont impressionnantes, il est 30 fois plus rapide que les précédents de l’état de l’art, avec environ 35 secondes de temps de calcul par itération de l’algorithme sur un graphe de quasiment 40 milliards de pages web. Calculer le PageRank sur un index de plusieurs centaines de milliards de pages est donc possible, avec des temps de calcul en heures ou en une poignée de jours, et c’est à la fois impressionnant et la garantie pour un grand moteur d’avoir une métrique de popularité toujours assez à jour malgré la volumétrie de l’index et sa dynamicité.
Est-ce que cela change le reste des processus SEO ? Absolument pas, bien au contraire, l’analyse de la structure du Web a toujours produit les signaux les plus importants pour les moteurs, et on voit que l’algorithmique mis en place est capable de suivre l’évolution de la volumétrie du Web, ce qui légitime encore plus le travail de linking des SEOs.
La vraie info n’est jamais celle qu’on croit
Ce qui est très intéressant dans la mise en avant de ce nouveau résultat sur le PageRank, ce n’est pas l’article en lui même, mais surtout le profil de l’auteur de l’algorithme. Bill Slawski a vu l’info sans rebondir dessus [6] lorsqu’il parle de Stergios Stergiou et reprend quelques éléments de son profil linkedin.
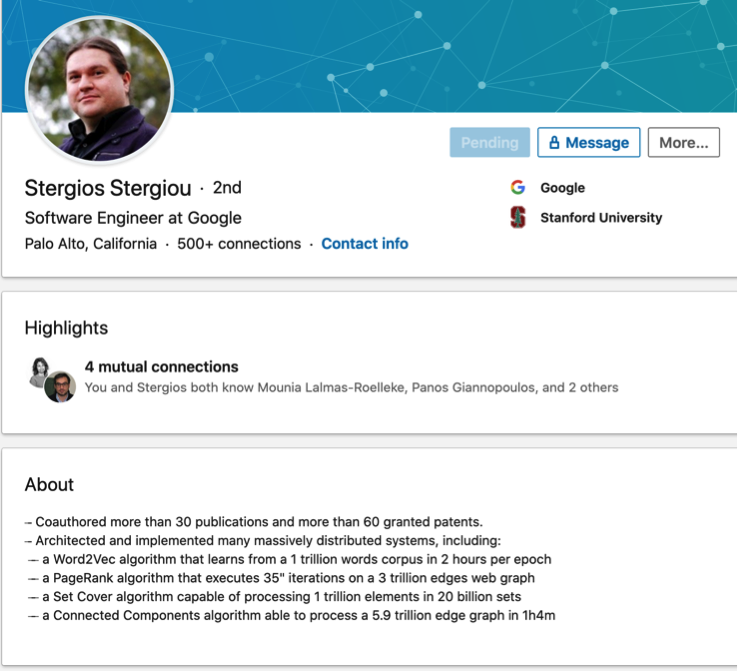
Fig. 1. Le profil linkedin de Stergios Stergiou..
Regardons ensemble et réfléchissons. On commence par le PageRank : il confirme bien le résultat de l’article de recherche, c’est plutôt bon signe, car on va maintenant regarder la ligne du dessus : une implémentation parallèle de word2vec sur un corpus de 1000 milliards de mots (voir l’article [7], qui date de 2017, autant dire une éternité à l’échelle des technologies des moteurs de recherche). Google a donc recruté un de ces ingénieurs capables de calculer en pratique la sémantique avec une méthode de vecteurs de contexte à l’échelle du Web.
C’est une information extrêmement importante. Autant on savait avec BERT que Google pouvait définir le contexte sémantique fin d’une requête pour mieux la comprendre, autant il est clair que maintenant le moteur peut aussi le faire pour absolument tous les contenus de l’index avec un modèle de chaque langue très fin. L’information est capitale car cela a un impact pour la rédaction des contenus : cela veut dire qu’un vocabulaire plus riche autour d’une même notion devient encore plus un avantage pour le positionnement.
Cela n’a l’air de rien, mais si le moteur propose des contenus légèrement plus riche, cela veut dire que l’algorithme de learning-to-rank va donner un peu plus de poids à la sémantique, ce qui finira par exclure les contenus les plus “bruts”, potentiellement des textes plus courts qui ne sont optimisés que par répétition de mots.
Les autres nouveautés sur le front du PageRank
Pour le reste, comme évoqué en introduction, il existe une littérature abondante sur le PageRank, mais la plupart du temps il s’agit plutôt d’adapter l’algorithme à des cas particuliers hors moteurs de recherche, ou à proposer des versions un peu nouvelle en termes de modélisation du surfeur aléatoire, mais sans que cela ne soit une rupture que pourrait réellement utiliser un moteur.
En revanche, sur les aspects pratiques, on trouve plus de nouveautés, avec des grosses sorties industrielles. Par exemple, NVidia propose via sa bibliothèque RAPIDS une implémentation multi-GPU du PageRank. Les résultats numériques sont très impressionnants avec un facteur d’accélération de x80 par rapport à des mises en oeuvre avec HADOOP ou SPARK. Mais ce qui n’est jamais dit sur ce type de travaux c’est que c’est très bien pour ceux qui font du PageRank pour un cas d’usage “maison” (mais qui peut-être industriel quand même), mais que pour un moteur de recherche, c’est tout simplement inutilisable.
En effet, une méthode efficace sur GPU est très performante jusqu’au moment où les structures de données ne sont plus gérables par les machines existantes, et à ce moment-là, ce n’est pas que le calcul est plus long, il n’est juste plus faisable.
Au final, tous les opérateurs qui visent des index de plus de 100 milliards de pages utilisent des techniques proches de celles de Stergios Stergiou, c’est par exemple notre cas dans le cadre du projet Babbar. Seule l’approche par simulation passe à l’échelle du Web, et des index qui sont de plus en plus grands.
Références
[1] Page, L., Brin, S., Motwani, R., & Winograd, T. (1999). The PageRank citation ranking: bringing order to the Web.
http://ilpubs.stanford.edu:8090/422/1/1999-66.pdf
[2] Haveliwala, T. H. (2003). Topic-sensitive PageRank: A context-sensitive ranking algorithm for web search. Knowledge and Data Engineering, IEEE Transactions on, 15(4), 784-796.
http://ilpubs.stanford.edu:8090/750/1/2003-29.pdf
[3] Ranking documents based on user behavior and/or feature data. Brevet Google.
http://bit.ly/1PND0i3
[4] Largillier, T., & Peyronnet, S. (2014). Algorithmique du web: autour du PageRank. Informatique Mathématique Une photographie en 2014. Presses Universitaires de Perpignan.
https://hal.archives-ouvertes.fr/hal-01147179/
[5] Stergiou, S. (2020, April). Scaling PageRank to 100 Billion Pages. In Proceedings of The Web Conference 2020 (pp. 2761-2767).
https://dl.acm.org/doi/pdf/10.1145/3366423.3380035
[6] http://www.seobythesea.com/2020/04/pagerank-2020/
[7] Stergiou, S., Straznickas, Z., Wu, R., & Tsioutsiouliklis, K. (2017, February). Distributed negative sampling for word embeddings. In Thirty-First AAAI Conference on Artificial Intelligence.
https://aaai.org/ocs/index.php/AAAI/AAAI17/paper/view/14956/14446
[8] https://medium.com/rapids-ai/rapids-cugraph-multi-gpu-pagerank-363aed1a2503
![]() Sylvain Peyronnet, concepteur de l’outil d’analyse de backlinks Babbar.
Sylvain Peyronnet, concepteur de l’outil d’analyse de backlinks Babbar.






![Copyright Trolling en France : comprendre et contrôler les abus d’une pratique controversée [Partie 2] - Stéphanie Barge](https://www.reacteur.com/content/uploads/2024/05/2024-05-reacteur-stephanie-barge.png)
![Copyright Trolling en France : comprendre et contrôler les abus d’une pratique controversée [Partie 1]- Stéphanie Barge](https://www.reacteur.com/content/uploads/2024/04/2024-04-reacteur-stephanie-barge.png)


5