

Il est très important en SEO de bien comprendre comment les choses se passent, quel sont le fonctionnement et les rouages de la Toile. Il en est ainsi de l’affichage d’une page web dans un navigateur. Cette action, qui semble simple a priori, est en fait une succession de tâches parfois très différentes sur lesquelles il peut être important de jouer pour optimiser l’UX, le SEO et les capacités techniques du serveur. Explications…
 Par Daniel Roch
Par Daniel RochOn parle souvent du temps de chargement d’une page web, et pourtant trop peu de personnes comprennent réellement comment se charge une URL (une page web) dans le navigateur de l’internaute. Trop peu d’individus connaissent aussi l’impact que cela peut avoir sur l’utilisateur, sur le référencement naturel ou encore sur l’infrastructure informatique d’un site.
Dans ce guide en deux parties, nous allons donc passer en revue ces différents aspects.
C’est quoi le chargement d’une page web ?
Un chargement en plusieurs étapes
Commençons par correctement définir le sujet : quand on parle du chargement d’une page web, on parle en réalité de plusieurs actions qui vont se dérouler plus ou moins simultanément :
- Le fait pour l’internaute de se connecter à une adresse web, en l’occurrence à un nom de domaine précis ;
- La génération du contenu par le serveur/site web si cela est nécessaire (c’est notamment le cas par défaut sur tous les CMS) ;
- Le téléchargement de tous les éléments de la page par l’internaute (les fichiers HTML, CSS, JS, images, etc.) ;
- L’affichage et le rendu final de la page dans le navigateur (et donc le chargement et l’exécution de tous ces fichiers).
On aborde alors souvent le sujet du temps nécessaire pour charger une page web. Et ce temps peut avoir lui aussi une importance cruciale.
Chargement Réel et ressenti
Quand on parle du chargement d’une page, il faut aussi garder en tête qu’il existe une différence entre le chargement réel (fichiers téléchargés et exécutés) et celui ressenti par l’internaute. En fonction des différentes étapes et de la conception technique de votre site, le visiteur peut ainsi le ressentir plus rapidement ou plus lentement que son chargement « réel ».
Prenons un exemple simple : la page se charge en 2 secondes pour l’internaute, mais un script finira de s’exécuter au bout de 4. Pour autant, entre la deuxième et la quatrième seconde, rien n’a changé visuellement sur le site. Le chargement réel est de 4 secondes et celui ressenti de 2.
Comprendre le waterfall
Avant de voir comment mesurer le chargement d’une page, l’impact de ce dernier et les bonnes pratiques à mettre en place, il faut d’abord comprendre les différentes étapes du chargement d’une page web. Nous pourrons les visualiser avec ce qu’on appelle le waterfall du chargement de la page. Et cela ressemble à ceci :
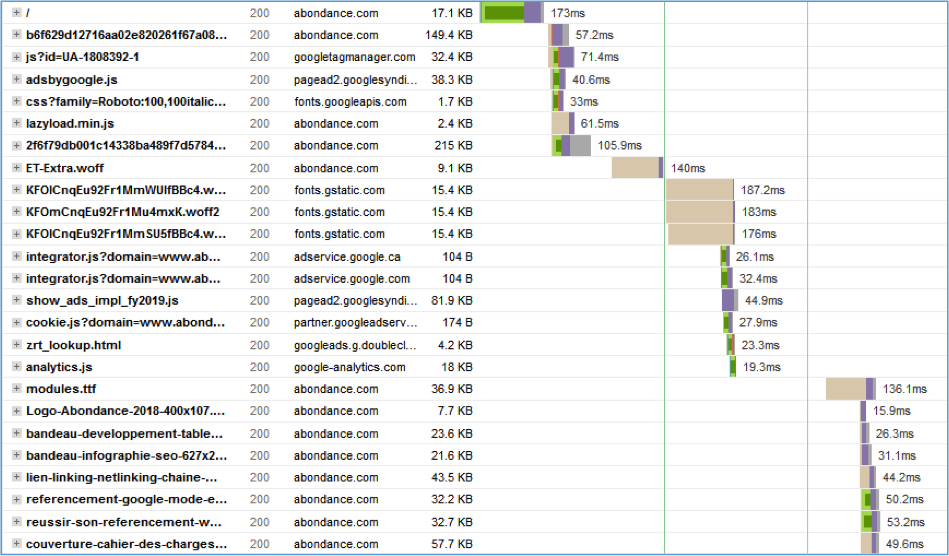
Fig. 1. Le waterfall de la page d’accueil d’Abondance.com (généré avec l’outil GtMetrix).
Le waterfall (chute d’eau) représente les différentes étapes du téléchargement d’une page :
- Chaque ligne est un fichier que le navigateur doit télécharger ;
- La seconde colonne indique l’entête de ce fichier (200 « fichier téléchargé », 404 « fichier introuvable », etc.) ;
- La 3ème colonne indique le nom de domaine où se trouve le fichier ;
- La 4ème affiche le poids du fichier ;
- Enfin, le rectangle de couleur à droite représente le temps que cela a pris, en millisecondes, pour le charger.
Ceci est important car une grande partie du chargement d’une page web dépend du téléchargement de ces fichiers. Et cette visualisation est celle qui en permet le plus facilement la compréhension. Vous pourrez retrouver cette visualisation dans les outils que l’on citera plus loin, mais aussi directement dans la console de votre navigateur :
- Sur Firefox dans l’onglet Réseau ;
- Sur Chrome dans l’onglet NetWork.
Ressources bloquantes
Il existe un certain nombre de ressources « bloquantes », c’est-à-dire sans lesquelles le navigateur n’affichera rien ou devra attendre avant de charger le reste. Il s’agit de base :
- Du contenu HTML (le code source) ;
- Des fichiers de mise en page CSS ;
- Des fichiers Javascript si on les charge de façon classique.
Par exemple, si une image de fond est définie avec un fichier CSS, cette ressource devra attendre le téléchargement puis l’analyse du CSS par le navigateur avant de pouvoir commencer à être téléchargée et affichée.
Heureusement, toutes les ressources ne sont pas bloquantes. Parfois, ces fichiers sont chargés de façon asynchrone, c’est-à-dire sans bloquer le chargement de la page. De même, les images sont la plupart du temps téléchargées en simultané, ou elles peuvent être téléchargées uniquement quand cela est nécessaire (avec la technique de Lazy-Loading). C’est pour cette raison que les pages web commencent à se charger et à s’afficher avant que l’ensemble des fichiers ne soient disponibles.
Comment se charge une page web ?
Voyons maintenant de façon plus précise ce que fait le navigateur.
1ère étape : la résolution du nom de domaine
C’est une étape indispensable : en tapant une nouvelle URL dans le navigateur, votre ordinateur doit trouver où se trouve ce site dans le monde, sur la Toile. C’est ce qu’on appelle la résolution DNS. Cela revient à trouver l’adresse IP du serveur pour ce nom de domaine. Pour imager cette problématique, c’est un peu comme si l’on cherchait une adresse postale dans les Pages Jaunes.
Cette image en anglais de Vladstudio explique parfaitement cela :

Fig. 2. Une explication visuelle de la résolution DNS – source : https://vlad.studio/fr/wallpaper/how_internet_works.
Gardez en tête que lors du chargement d’une page, vous aurez au minimum une résolution DNS, mais vous pouvez en avoir plusieurs si certaines ressources se trouvent sur d’autres noms de domaines. Ce sera le cas par exemple :
- Avec un script Google Analytics ;
- Avec les régies publicitaires ;
- Si vous affichez une vidéo de YouTube ou de Dailymotion ;
- Etc.
2ème étape : connexion TCP et requête http
A ce stade-là, vous savez où est le serveur qui héberge l’URL que vous voulez consulter. Votre ordinateur va alors établir une connexion (on appelle cela une connexion TCP). Dès que cette connexion est établie, le navigateur va envoyer une requête HTTP contenant sa demande, en d’autres termes « ceci est le contenu que je veux consulter ».
Voici ce à quoi cela ressemble :
| Request Version – HTTP/1.1 | |
| Host | www.abondance.com |
| Connection | keep-alive |
| Upgrade-Insecure-Requests | 1 |
| User-Agent | Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36 |
| Accept | text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3 |
| Accept-Encoding | gzip, deflate, br |
| Accept-Language | en-US,en;q=0.9 |
3ème étape : la génération du contenu
Dans certains cas, la page demandée est un document HTML simple, auquel cas on ira directement à l’étape 4.
Mais la plupart du temps, il faudra générer le contenu. C’est le cas notamment de tous les CMS pour lesquels on demande une URL et où la plateforme, sur le serveur, doit aller « chercher » en base de données les informations nécessaires pour son affichage. Sans paramétrage spécifique (sans solution de cache), cette génération à elle seule peut parfois prendre plusieurs secondes, surtout si votre CMS est mal optimisé (mauvais réglages, trop d’extensions, thème mal conçu, etc.). Bref, la page doit être « consrtuite » sur la base de différentes briques disponibles en base de données.
4ème étape : télécharger le document HTML
Le serveur web va enfin pouvoir envoyer la réponse HTTP demandée par le navigateur, et il va donc pouvoir renvoyer le contenu qui va avec.
Généré ou non, le navigateur devra ensuite télécharger le contenu HTML, c’est-à-dire le contenu brut de la page web, sans aucune image ni mise en page. Dans notre waterfall d el’exemple ci-dessus (figure 1), les étapes 1 à 4 ne correspondent qu’à la première ligne.
Si l’on reprend toujours l’image d’exemple, il aura fallu 173 millisecondes pour que le navigateur fasse la résolution DNS du nom de domaine d’Abondance, que le site génère (ou renvoie) le contenu HTML puis que le navigateur télécharge ce dernier.
5ème étape : télécharger les ressources
Une fois l’HTML récupéré, le navigateur va l’analyser. Il va pouvoir ensuite télécharger les ressources nécessaires les unes après les autres : CSS, JavaScripts, Images, Polices de caractère, etc. Dès qu’il le pourra, il commencera à afficher la page, même si toutes les ressources ne sont pas encore accessibles.
Cette 5ème étape correspond à l’ensemble des autres lignes du waterfall.
5ème étape (bis) : DOM et exécution des fichiers
Le code source de la page correspond à un contenu brut : c’est ni plus ni moins qu’une liste de balises HTML (sauts de ligne, liens, images, paragraphes et ainsi de suite). Mais pour lui permettre de l’afficher et d’interagir avec, le navigateur doit créer ce qu’on appelle le DOM (pour Document Object Model). Il doit analyser le contenu brut et le rendre utilisable.
Pour simplifier, le DOM est le squelette de votre page, et chaque balise HTML sera un des éléments du DOM. Ce DOM ressemblera à un arbre ou chaque élément va s’imbriquer ou suivre un autre.
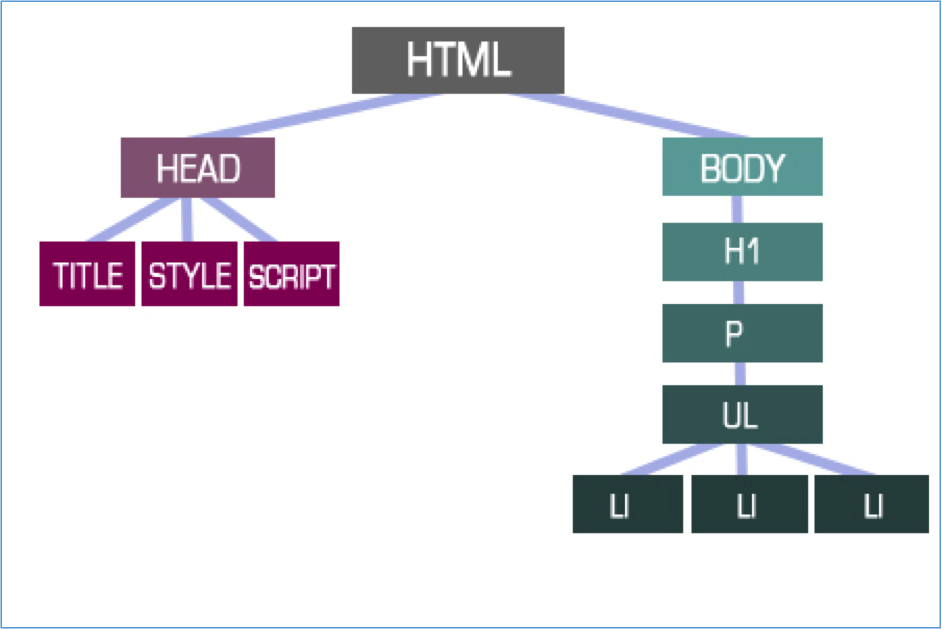
Fig. 3. Le DOM très basique d’une page web – Source http://41mag.fr/quest-ce-que-le-dom-dune-page-web.html.
Parfois, le navigateur va intervenir et modifier le code pour réparer des problèmes techniques. Heureusement d’ailleurs, car de nombreuses pages web contiennent des erreurs dans leur code HTML et le navigateur va quand même essayer de les afficher correctement. Le DOM ne correspond donc pas toujours au code source initial de la page.
Une fois téléchargés, le CSS et le Javascript iront ensuite s’appliquer sur le DOM. On peut ainsi avoir téléchargé toutes les ressources d’une page sans pour autant que cette dernière soit entièrement chargée : dans ce cas de figure, le DOM n’est pas encore entièrement initialisé ou alors certaines règles JS ou CSS n’ont pas encore eu le temps de s’exécuter entièrement.
Pourquoi le chargement d’une page est important ?
La manière dont on conçoit son site a un impact sur la façon dont chaque contenu se chargera. C’est notamment important pour la vitesse d’un site, mais aussi pour l’ordre de chargement et le rendu visuel de chaque élément.
Pour l’utilisateur
Pour le visiteur, c’est crucial. Si une page est trop lente :
- L’internaute risque de partir avant qu’elle ne soit chargée entièrement ;
- Il risque de ne pas continuer sa navigation ;
- Cela dégrade l’expérience utilisateur et l’image de marque.
Et cela peut aller très loin. Prenons un exemple concret : en 2012, Amazon estimait que si ses pages mettaient une seconde de plus à charger, cela leur ferait perdre 1,6 milliard de dollars par an (source : https://www.fastcompany.com/1825005/how-one-second-could-cost-amazon-16-billion-sales). En d’autres termes, cela nuit au ressenti de l’utilisateur et cela fait perdre de l’argent aux entreprises.
Il faut donc réduire au strict minimum les freins, que ce soit :
- Le temps de chargement total ;
- Le temps avant que les premiers éléments ne s’affichent ;
- Le poids total de la page ;
- Les effets visuels (si des éléments « bougent » pendant le chargement) ;
- Le nombre de fichier à télécharger ;
- etc.
Pour le SEO
Depuis plusieurs années, Google communiquait sur le fait que le temps de chargement était un critère important pour avoir un meilleur positionnement. Dans les faits, les référenceurs se sont vite rendu compte que l’impact n’était pas visible. C’est ce qui a été confirmé récemment par les équipes de Google qui ont avoué que la vitesse de chargement d’une page était un critère très faible : https://www.abondance.com/20200430-42659-google-confirme-le-temps-de-chargement-des-pages-est-un-critere-de-pertinence-de-tres-faible-poids.html
Cependant, cette notion a par contre un fort impact sur un aspect plus précis du référencement naturel : le crawl et l’indexation, c’est-à-dire la capacité pour Google et les autres moteurs de recherche à parcourir et à comprendre l’ensemble des URL.
Pour le serveur
Aspect trop peu souvent cité, la conception d’une page web impactera le serveur sur lequel le site est hébergé. En règle générale, une page lente signifie un site ou des fichiers non optimisés : pas de mise en cache, images trop lourdes, trop de fichiers, etc.
Si l’on améliore la vitesse d’un site et/ou la façon dont on affiche un contenu, on va ainsi soulager notre serveur web. On pourra ainsi accueillir plus de visiteurs en simultané, avec un coût moindre et un risque moins élevé de faire planter le serveur. On aura également un impact écologique positif car on aura moins de ressources à héberger, et un besoin plus faible de bande passante pour envoyer les fichiers aux internautes.
Conclusion
Voici donc pour cette première partie sur les fondamentaux du chargement d’une page web. Le mois prochain, nous terminerons cette vision globales sur la façon dont une page web se charge en évoquant les différents moyens de mesure à notre disposition, les notations, les indicateurs-clés, et une nombre important de bonnes pratiques à mettre en œuvre.
![]() Daniel Roch, consultant WordPress, Référencement et Webmarketing chez SeoMix (https://www.seomix.fr)
Daniel Roch, consultant WordPress, Référencement et Webmarketing chez SeoMix (https://www.seomix.fr)






![Copyright Trolling en France : comprendre et contrôler les abus d’une pratique controversée [Partie 2] - Stéphanie Barge](https://www.reacteur.com/content/uploads/2024/05/2024-05-reacteur-stephanie-barge.png)
![Copyright Trolling en France : comprendre et contrôler les abus d’une pratique controversée [Partie 1]- Stéphanie Barge](https://www.reacteur.com/content/uploads/2024/04/2024-04-reacteur-stephanie-barge.png)


5