 Les moteurs de recherche modernes comme Google ou Bing utilisent une pondération des différents critères de pertinence qu’ils utilisent, en fonction de l’intention de recherche détectée derrière la requête. Et pour tirer les ficelles et gérer ce poids attribué à chaque signal, c’est un algorithme nommé « Learning to Rank » qui va tenir la baguette pour configurer au mieux la balance de la pertinence. Voici comment il fonctionne…
Les moteurs de recherche modernes comme Google ou Bing utilisent une pondération des différents critères de pertinence qu’ils utilisent, en fonction de l’intention de recherche détectée derrière la requête. Et pour tirer les ficelles et gérer ce poids attribué à chaque signal, c’est un algorithme nommé « Learning to Rank » qui va tenir la baguette pour configurer au mieux la balance de la pertinence. Voici comment il fonctionne…
La légende (ou le storytelling de la société) dit que Google utilise plus de 200 signaux, voire même beaucoup plus si on en croit l’article [1] de Danny Sullivan qui évoque une conférence de Matt Cutts de novembre 2010 dans laquelle ce dernier évoque plus de 50 variations par signal. Techniquement, cela fait donc plus de 10 000 signaux ! Et on parle de 2010…
Mais si le moteur a autant de signaux, la question que l’on peut légitimement se poser est donc de savoir quels sont les signaux importants. Tout le monde n’en a pas conscience, mais il existe un algorithme dont le seul objectif est de déterminer l’importance des signaux, pour créer une fonction de classement unique en les pondérant. Cet algorithme, dont j’ai déjà parlé à plusieurs occasions (voir l’article [2] par exemple), a un nom générique : le learning-to-rank.
Vous l’avez compris, le learning-to-rank sera le sujet de cet article 😉
Un peu d’histoire
Le principe du learning-to-rank est un principe d’apprentissage automatique (machine learning), mais de manière assez étonnante, il aura fallu pas mal de temps pour que les moteurs de recherche se dotent d’un tel mécanisme. La principale raison est que les chercheurs en machine learning n’étaient pas forcément très intéressés par la recherche d’information pendant une assez longue période.
Les premières approches mises en place au sein d’un moteur se trouvent chez Altavista (voir le brevet de David Cossock, référence [3]). La figure 1, issue de ce brevet, est très explicite quant au principe de l’algorithme.
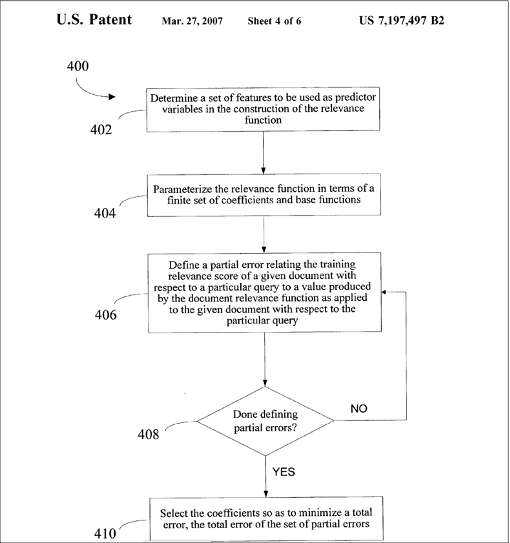
Un algorithme de learning-to-rank chez Altavista
L’idée est la suivante : on détermine tout d’abord les caractéristiques importantes pour le classement, on les pondère, on regarde l’erreur commise en termes de qualité de résultat, puis on modifie les pondérations pour améliorer la qualité, et on recommence…
L’idée est simple, mais la mise en pratique est complexe, et en réalité on ne sait pas dire à quel point l’algorithme était dynamique, s’ il était utilisé en temps réel, avec quelle entrée en termes de mesure de qualité.
Ce qui va tout changer pour les moteurs, ce sont les travaux de l’équipe de Chris Burges, chez Microsoft Bing (voir l’article [4]). Dans leur premier article, qui date de 2005, ils expliquent comment utiliser des réseaux de neurones pour faire de la descente de gradient pour apprendre le meilleur “mix” de signaux pour classer des résultats au niveau d’un moteur de recherche.
Dès les premiers tests, ce système – RankNet – est capable de calibrer le moteur de recherche en quelques heures, là où le précédent système – appelé le hollandais volant – mettait plusieurs jours. Par ailleurs, en utilisant des réseaux de neurones, il était possible de créer des mix de signaux non linéaires, ce qui change tout en termes de qualité de résultats (on en reparlera plus loin).
RankNet a été ensuite amélioré plusieurs fois, sous les noms de LambdaRank puis de LambdaMart, toujours chez Microsoft, puis ensuite chez les compétiteurs (Google a communiqué récemment sur TF-Ranking par exemple, voir la référence [5]).
Le learning-to-rank, comment ça marche ?
Vous expliquer les arcanes mathématiques de ce type d’algorithme ne rentre pas dans le cadre des articles de Réacteur, mais je vais vous expliquer par l’exemple comment cela fonctionne.
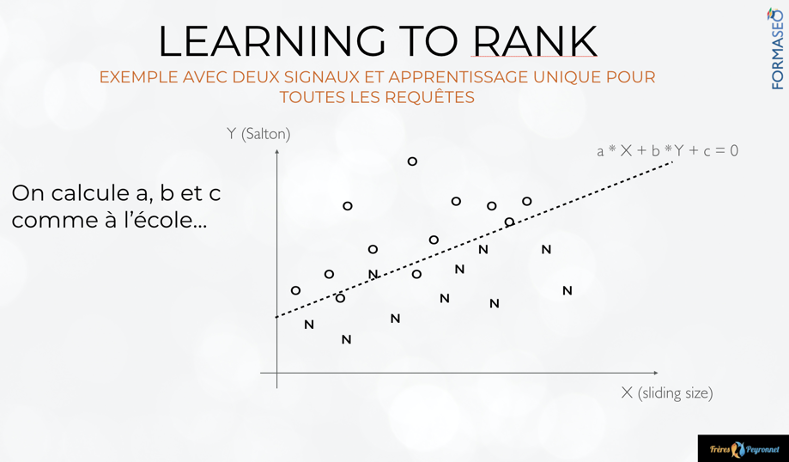
Le learning-to-rank, un exemple très basique
Dans la figure 2, tirée de la formation [6], j’ai indiqué par des “O” et des “N” le niveau de pertinence pour l’humain d’une URL. C’est-à-dire qu’un utilisateur m’a dit que pour une requête visée OUI ou NON, la page était pertinente ou pas. Chacune de ces URL est placée sur le plan selon la valeur de son signal “cosinus de salton” et de son signal “sliding size”. La définition de ces signaux n’a pas d’importance. Ce qui compte c’est le principe.
On voit que les pages sont “clusterisées” : en haut ,on a plutôt des pages pertinentes, en bas plutôt des pages non pertinentes. L’algorithme de learning-to-rank va apprendre les paramètres de la droite qui sépare les deux groupes, ce qui permet de trouver les pondérations de signaux qui vont donner un score adapté (haut pour ce qui est au-dessus de la droite, bas pour ce qui est en dessous). Quand une page est nouvelle dans l’index du moteur, il peut la positionner dans la figure, et dire si elle est pertinente ou non.
Périodiquement, le moteur peut réévaluer les pertinences “humaines” et se recalibrer. Un moteur comme Google peut le faire quasiment tous les jours, pour des groupes de requêtes qui sont dans une thématique et une intention similaire. C’est ainsi que certains signaux peuvent être importants pour une intention (par exemple commerciale) et pas pour une autre. L’exemple le plus étonnant est celui de la duplication de contenu : signal crucial sur l’informationnel (il ne faut pas être en duplication), peu signifiant sur le commercial.
Et l’humain dans tout ça ?
Bien entendu, ce qui a été un peu occulté ci-dessus est l’entrée “humaine” de l’algorithme. Comment est-ce qu’on mesure la qualité perçue par l’humain, et tout simplement qu’est ce qu’on lui demande de noter ?
Tout d’abord il faut bien comprendre que la mesure de la qualité perçue est implicite : on ne demande pas explicitement l’avis de l’humain, on le devine à partir de son comportement.
Il existe de nombreuses manières de faire cette mesure, une des plus intuitive est le click-skip. Le click-skip est un concept très simple : lorsque l’on fait une recherche sur le Web, l’ordre naturel de clic sur les résultats c’est 1-2-3-etc., mais si on fait (par exemple) 1-3-etc. Alors on a fait un click-skip de la page en 2eme position. Si le moteur monitore assez de click-skips, il peut assez vite prédire ce que les humains pensent des résultats.
Ce qui sera donné ensuite à l’algorithme de learning-to-rank est variable. Les premières approches (datant du début des années 1990) sont dites pointwise, c’est typiquement ce que j’ai évoqué dans le précédent exemple : on dit qu’une page est pertinente ou non pour calibrer le moteur.
Les approches modernes sont pairwise : on regarde si les humains préfèrent la page A à la page B, ou l’inverse. On va très exactement s’intéresser aux cas où le moteur fait une inversion par rapport à l’estimation humaine : on se concentre sur les erreurs de classement du moteur, dans le but de les éviter. RankNet, LambdaRank, LambdaMart utilisent une approche pairwise par exemple.
En fait, c’est très simple alors ?
Le principe est en effet très simple. Et on peut même aller plus loin : ce principe de séparation de l’espace par une droite se généralise, on parle de séparateurs dans des espaces plus complexes également. Et en fait, vous ne le savez peut-être pas, mais la science de ces séparateurs, et bien c’est en fait cela ce que la plupart des gens appellent l’intelligence artificielle (oui, si vous êtes un expert vous savez que j’exagère et que je suis réducteur à la fois, mais c’est bien une des idées fortes de la discipline).
En pratique, au niveau d’un moteur, il existe des milliers de signaux, et bien entendu, calibrer les pondérations ce n’est pas aussi simple que de tracer une droite. Il existe des algorithmes de machine learning qui vont par exemple faire ce que l’on appelle des arbres de régression, ce qui permet de faire du learning-to-rank efficace. C’est d’ailleurs typiquement ce qui a été utilisé par l’équipe de Microsoft pour construire RankNet et ses suivants.
Et le SEO ?
D’un point de vue SEO (le métier), les choses à faire sont assez claires pour une fois. Pour éviter que son site ne soit pas bien pris en compte par Google, il suffit d’éviter qu’il soit “click-skippé”. Pour cela il faut donc le rendre attractif dans la SERP.
Le meilleur moyen est de faire en sorte d’avoir un snippet attirant : belle promesse, artifice visuel, vous pouvez faire feu de tout bois du moment que le CTR est bon. Si vous faites du SEA à l’année, nul doute que vous avez déjà deviné que vos meta description doivent par exemple être très inspirées de vos annonces les plus performantes.
Pour le reste, il existe également de nombreuses astuces, mais elles dépassent assez largement le cadre de cet article introductif.
D’un point de vue SEO (ce que l’on voit en terme de classement sur le moteur), là aussi les choses sont assez claires : le moteur va monitorer les résultats en continu, pour des familles de requêtes qui portent des besoins informationnels similaires. In fine, il devient capable de se paramétrer tout seul, sans intervention humaine directe, pour répondre le mieux possible. Le point le plus important en terme de SEO, c’est que même si deux requêtes sont dans la même thématique, si elles sont sur des intentions de recherche différentes, le moteur peut utiliser différemment les mêmes signaux.
En conséquence, il devient encore plus important qu’avant de bien savoir quelles sont les intentions importantes pour les visiteurs que vous visez, et il est important de comprendre quels sont les signaux importants pour ces intentions. Pour cela, benchmarkez-vous avec vos concurrents pour les mêmes intentions.
Voilà, vous savez maintenant tout du learning-to-rank, vous n’avez plus qu’à mettre cette connaissance en musique 😉
Références
[1] https://searchengineland.com/bing-10000-ranking-signals-google-55473
[3] https://patents.google.com/patent/US7197497B2/en
[4] Burges, C., Shaked, T., Renshaw, E., Lazier, A., Deeds, M., Hamilton, N., & Hullender, G. (2005, August). Learning to rank using gradient descent. In Proceedings of the 22nd international conference on Machine learning (pp. 89-96).
https://icml.cc/2015/content/uploads/2015/06/icml_ranking.pdf
[5] https://ai.googleblog.com/2018/12/tf-ranking-scalable-tensorflow-library.html
[6] https://www.formaseo.fr/page/formation-seo-formaseo-algorithmie-des-moteurs-de-recherche

![]() Sylvain Peyronnet, concepteur de l’outil d’analyse de backlinks Babbar.
Sylvain Peyronnet, concepteur de l’outil d’analyse de backlinks Babbar.






![Copyright Trolling en France : comprendre et contrôler les abus d’une pratique controversée [Partie 2] - Stéphanie Barge](https://www.reacteur.com/content/uploads/2024/05/2024-05-reacteur-stephanie-barge.png)
![Copyright Trolling en France : comprendre et contrôler les abus d’une pratique controversée [Partie 1]- Stéphanie Barge](https://www.reacteur.com/content/uploads/2024/04/2024-04-reacteur-stephanie-barge.png)


5