
 Après avoir exploré la configuration de l’outil Screaming Frog et initié l’interprétation des crawls effectués les mois précédents, faisons place ce mois-ci à deux problématiques importantes : la présentation des dernières fonctionnalités de la version 14 de l’outil, ainsi que ses différentes (et nombreuses) possibilités de représentation graphique de l’arborescence d’un site. Et, là aussi, les fonctionnalités sont nombreuses !
Après avoir exploré la configuration de l’outil Screaming Frog et initié l’interprétation des crawls effectués les mois précédents, faisons place ce mois-ci à deux problématiques importantes : la présentation des dernières fonctionnalités de la version 14 de l’outil, ainsi que ses différentes (et nombreuses) possibilités de représentation graphique de l’arborescence d’un site. Et, là aussi, les fonctionnalités sont nombreuses !
Troisième article de la série sur le crawler Screaming Frog, après avoir vu comment bien configurer plusieurs paramètres son crawl, et analyser une partie des résultats tout en évitant des erreurs d’interprétation.
Nous verrons dans cet article les fonctionnalités de visualisation de l’outil, ainsi que l’option d’analyse d’exploration qui permet de calculer un certain nombre de métriques post-crawl.
Mais avant tout chose, nous allons rapidement passer en revue les nouveautés de la version 14.0 de l’outil, sortie le 23 novembre dernier.
Nouveautés de la version 14.0
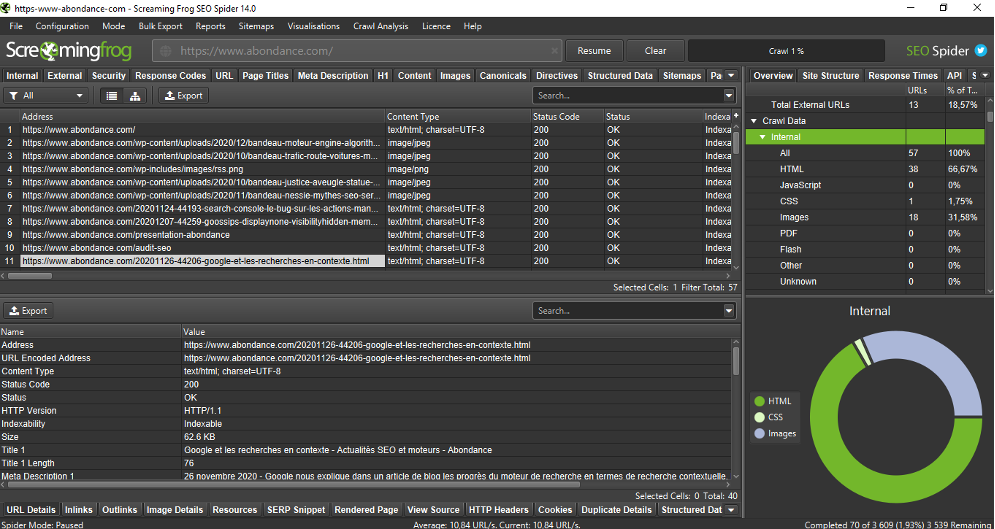
Modification de la couleur de l’interface (Menu Configuration > User interface > Theme)
Hormis l’arrivée de l’interface « Dark Mode » qui peut être plus agréable à l’œil, voici des nouveautés qui vous seront plus utiles d’un point de vue opérationnel:
- Possibilité de générer des exports via Google Sheets en ayant préalablement connecté votre compte (option également disponible pour les crawls préprogrammés et leurs exports) ;
- Extraction de l’ensemble des en-têtes http pour chaque requête : cela peut s’avérer très pratique pour identifier les directives de cache sur les URL spécifiques ;
- Possibilité de collecter les informations contenues dans les cookies.
Structure de site agrégée
L’apparition d’une nouvelle colonne dans l’onglet « Internal » peut s’avérer pertinente pour certains sites : il s’agit de la possibilité de connaitre le nombre d’URL en fonction de leur structure par répertoire (ou chemin, parfois virtuel via la réecriture d’URL) :
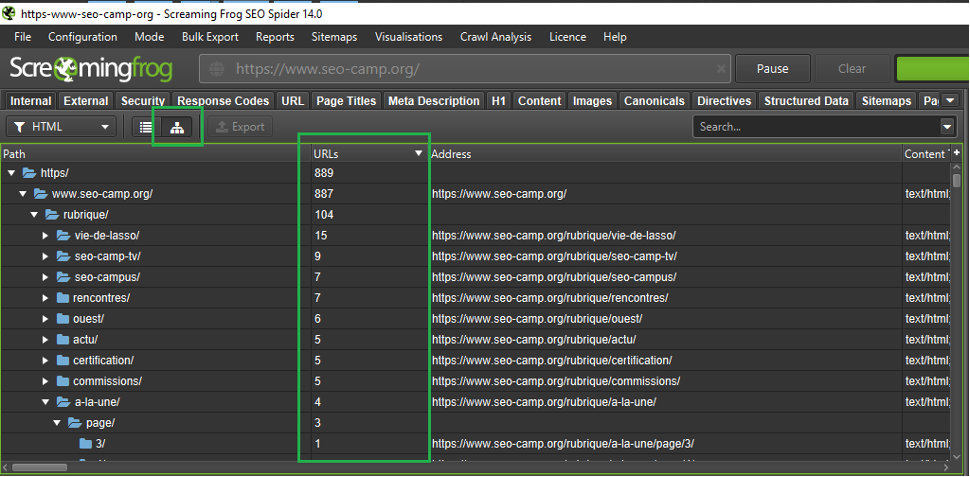
Structure agrégée du site avec le nombre d’URL par répertoire
On visualise ainsi rapidement le nombre de pages pour chaque catégorie du site, ce qui permet de se faire une bonne idée de ses contenus.
En complément, la partie graphique « Site structure » située dans la colonne de droite de l’outil, permet d’avoir cette vision avec la possibilité de naviguer niveau par niveau (à condition que les niveaux des répertoires représentent l’arborescence réelle des contenus pour que cela ait du sens) :
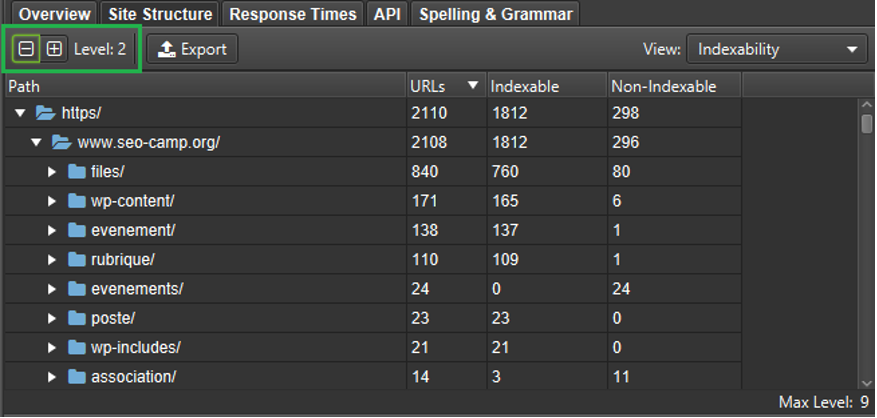
Vision « Site structure > Indexability » : regroupement des pages en niveau 2 des répertoires (en fonction des URL)
La navigation entre les niveaux de la structure des répertoires (à ne pas confondre avec la profondeur réelle des contenus, visible en utilisant « Crawl depth » dans le menu déroulant de ce volet) peut se faire grâce aux boutons « + » et « – ».
On peut ainsi voir pour chaque regroupement de contenu (en fonction des répertoires dans l’URL), différentes données dont :
- la répartition des codes réponses ;
- la profondeur des contenus ;
- l’indexabilité.
Ces données relatives à l’indexabilité aident à mieux visualiser les types d’éléments qui ne peuvent pas être indexés, comme les éléments contenus dans le répertoire « /evenements/ » dans l’exemple ci-dessus.
Pour ce qui est des codes réponses, on pourra rapidement isoler l’ensemble d’un répertoire pour lesquels les éléments qu’il contient répondent en 404 :
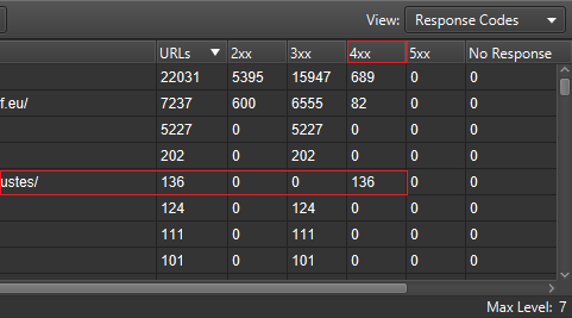
Vision « Site structure » par codes réponses
L’une des dernières nouveautés de la version 14.0 se trouve dans le graphique de cet onglet « Site structure », et permet de visualiser les codes réponses (et la crawlabilité restreinte via le robots.txt) des contenus en fonction de leur profondeur :
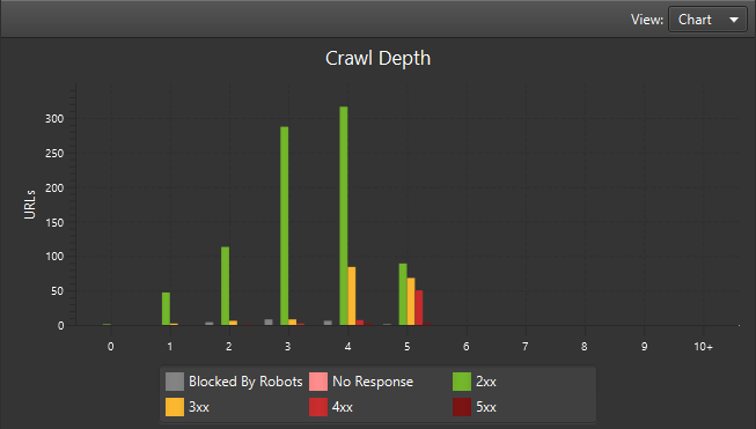
Profondeur des URL en fonction des codes réponses
Nous constatons ici un nombre particulièrement élevé d’erreurs 4xx (403, 404, etc.) au cinquième niveau de profondeur, ainsi que de nombreuses redirections en niveau 4 et 5.
Visualisation
Depuis 2 ans, Screaming Frog dispose de différents outils de visualisations. Ils permettent de mettre en avant certaines faiblesses SEO de sites, mais encore faut il bien comprendre la façon dont fonctionnent ces outils
Maillage
Dans les différents menus, le menu « Visualisations » permet d’avoir une représentation visuelle du site de deux façons différentes :
- « Force-Directed Directory Tree Diagram » permet d’effectuer une visualisation de la structure du site en fonction de l’arborescence des répertoires ;
- « Force-Directed crawl Diagram » permet d’effectuer une visualisation du maillage du site, en fonction du niveau de profondeur des URL.
Attention cependant, « Force-Directed crawl Diagram » ne représente pas l’intégralité du maillage interne, mais uniquement une partie de la navigation descendante, où ne sont affichés que le chemin le plus rapide via les liens pour arriver à chaque URL. Par exemple, si une page Catégorie est accessible depuis la page d’accueil, mais également via une page de sous-catégorie, c’est le chemin le plus rapide (via la homepage) qui sera dessiné.
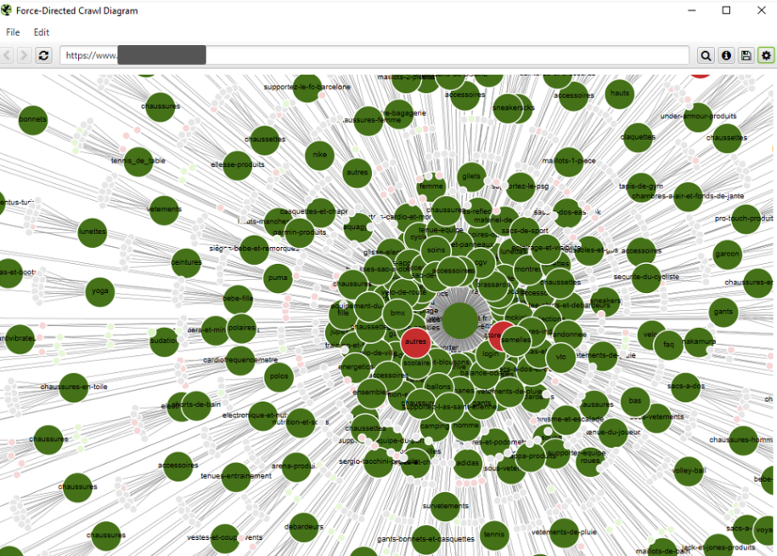
Visualisation – navigation descendante
Cette fonction, largement paramétrable, permet de visualiser différentes problématiques en fonction de la configuration effectuée :
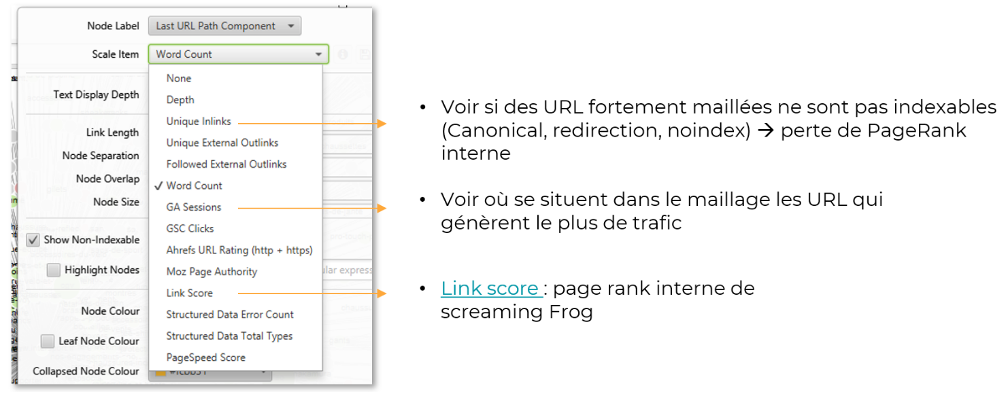
Paramétrage de la visualisation
La largeur de chaque cercle (représentant une URL précise) peut représenter différents KPI. Par défaut, ce diamètre est associé à la profondeur de l’URL (plus le rond est petit, plus l’URL est profonde).
Le fait de pouvoir afficher en rouge (couleur modifiable) les pages identifiées comme « Non-indexable » (URL non canoniques, pages en « noindex », pages redirigées », etc.) peut mettre en avant des fuites de popularité, avec du pagerank interne diffusé de à des pages non indexées :

URL maillées mais non indexables
Dans l’exemple ci-dessous, nous constatons la présence de nombreuses pages avec une URL canonique (après avoir survolé une partie des points rouges pour avoir le détail par URL), ce qui signifie la présence de liens vers ces pages qui déséquilibrent la structure du site, et augmente probablement le taux de crawl sur des URL pouvant être considérées comme dupliquées :

Présence d’un nombre important de pages avec une balise canonique en rouge
Pour isoler visuellement certaines URL en fonction de leur structure, il est possible d’utiliser des expressions régulières, via le champ suivant dans les paramètres de la visualisation. Ici, nous allons mettre en avant les URL qui contiennent des paramètres (ex : /path?cle=valeur) :
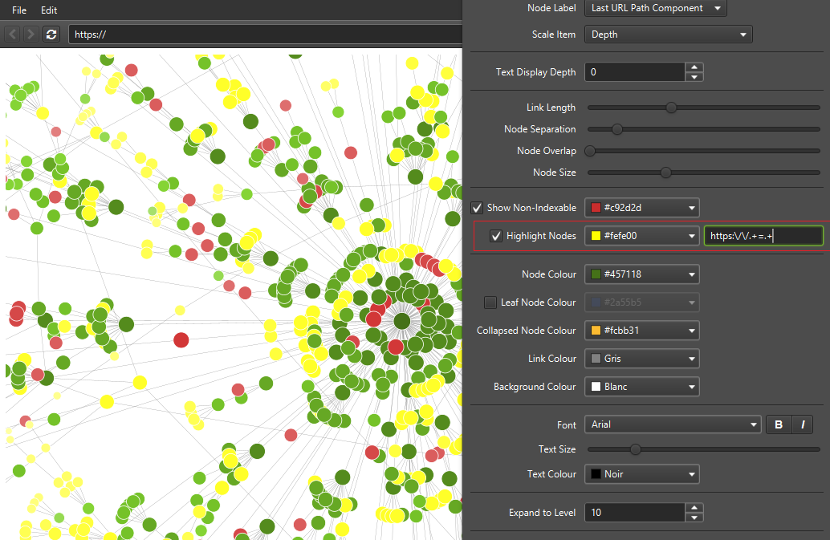
Utilisation d’expressions régulières dans la visualisation
Nous utilisons l’écriture suivante pour indiquer que nous cherchons les URL qui contiennent « = » dans l’URL : https:\/\/.+=.+
L’utilisation d’un mode de calcul du PageRank interne est également possible. Il faudra au préalable lancer un « Crawl analysis » dans le menu correspondant. Avant cela, en modifiant le « Scale item » sur « Unique Inlinks », on pourra visualiser les pages peu maillées (ou à l’inverse les pages fortement maillées) :
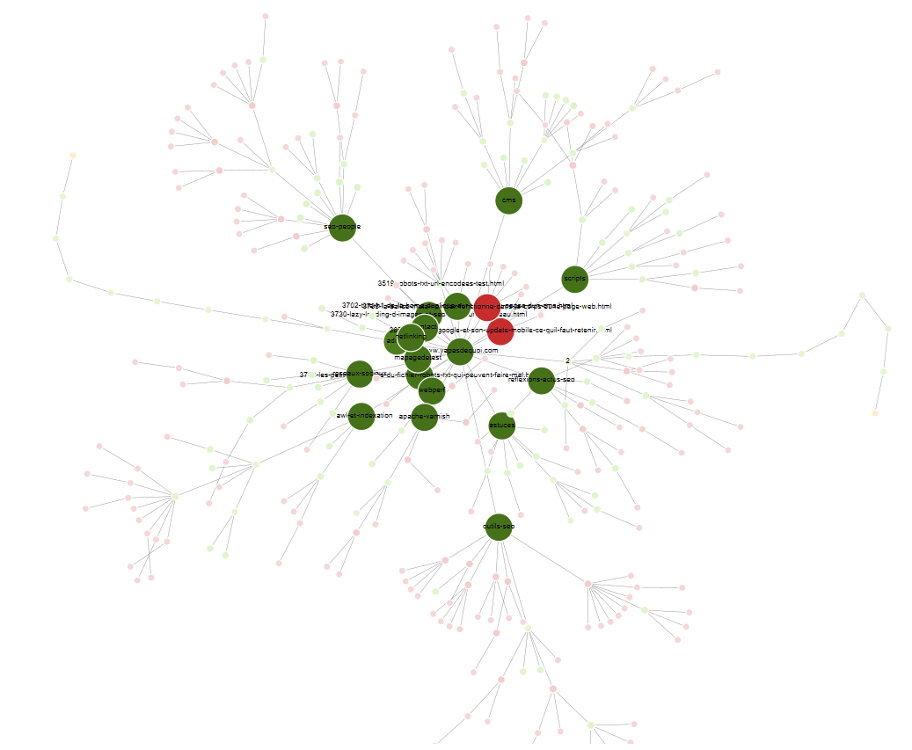
Les cercles les plus larges correspondent aux pages recevant de nombreux liens uniques
De la même manière, une fois connecté à la Search Console, on pourra visualiser de façon rapide où se situent les pages qui génèrent le plus de trafic (« Scale item » > « GSC clicks »), et mettre en avant les pages relativement hautes dans l’arborescence qui en génèrent peu…
Cette visualisation est disponible au global, mais également à partir d’une URL précise ce qui permettra une vision plus claire sur un groupe de pages :
Visualisation sur une URL spécifique
La même visualisation pour des URL spécifiques est également possible via un clic-droit directement sur le diagramme, puis l’option « Focus here » :
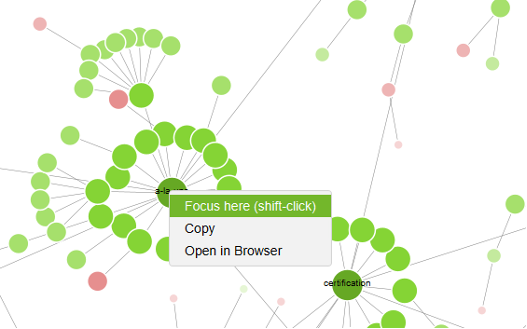
Focus à partir d’une URL spécifique
Dans l’exemple ci-dessous, nous pouvons facilement identifier un défaut de maillage sur la version mobile du site crawlée :
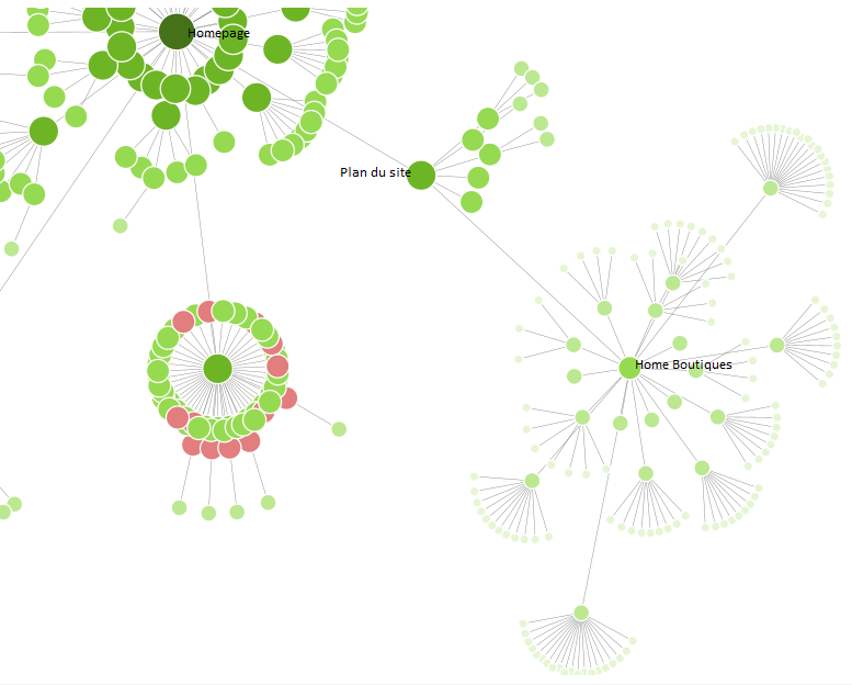
Visualisation d’un défaut de maillage sur une version mobile
Ce site vitrine avec des boutiques ayant pignon sur rue possède bien un lien depuis sa page d’accueil vers le store locator, mais uniquement dans sa version pour Ordinateur. La version mobile du site possède un menu différent, et ne propose pas de liens vers le store locator depuis la page d’accueil. Il est nécessaire de passer par la page « Plan du site » pour accéder aux boutiques, ce qui n’est pas idéal d’un point de vue utilisateur, et ne facilite pas la transmission de popularité vers les pages boutiques (et département) via la navigation descendante.
Ancres et corps d’une page
D’autres outils de visualisation sont disponibles, dont un qui permet de mettre en avant les principales occurrences dans un contenu, via un clic-droit sur une URL, puis « Visualisation » > « Body text word cloud » :
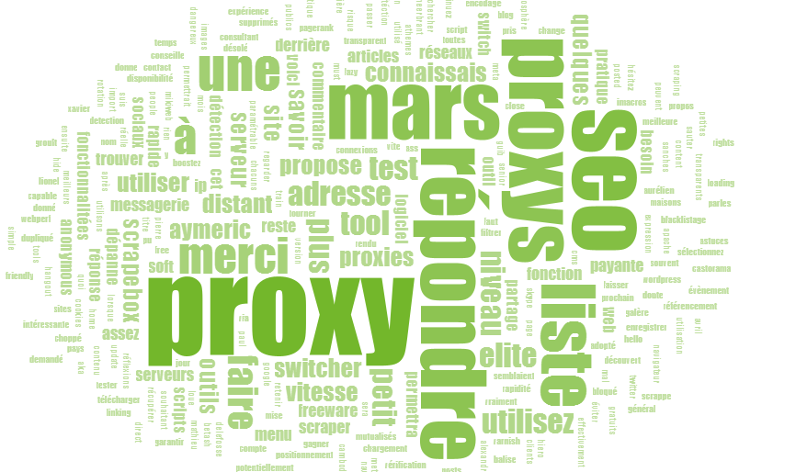
Visualisation des occurrences les plus fréquentes dans un contenu
Pour utiliser cette fonction, il est nécessaire d’extraire l’ensemble du code HTML pendant le crawl (Configuration > Extraction > Store HTML). Cela peut s’avérer pratique pour mettre en avant les principaux termes d’une page, et s’assurer qu’ils sont en corrélation avec les requêtes cibles.
En complément, il est également possible de créer un nuage de tags pour mettre en avant les ancres de liens les plus utilisées vers une URL (Visualisation > Inlink anchor text word cloud). Cela permettra de favoriser les variations sémantiques via les ancres de liens, dans une optique d’amélioration du maillage interne. Dans l’exemple ci-dessous, les ancres ne sont pas les plus pertinentes en terme de transmission de sémantique :

Nuage des ancres de liens vers une page
Cela ne renforce pas le poids de la page sur des requêtes plus ciblées (les mois de l’année étant peut pertinent).
Analyse approfondie avec « Crawl analysis »
Cette fonction, à exécuter une fois le crawl terminé, permet entre autres d’exécuter un certain nombre de comparaison entre les URL trouvées via différents moyens, et les URL crawlées.
On détectera ainsi les URL orphelines (URL trouvées mais ne recevant pas de liens), afin de mettre en évidence des problèmes de maillage (et/ou de configuration). Un calcul du pagerank interne (Link Score) pourra également être exécuté.
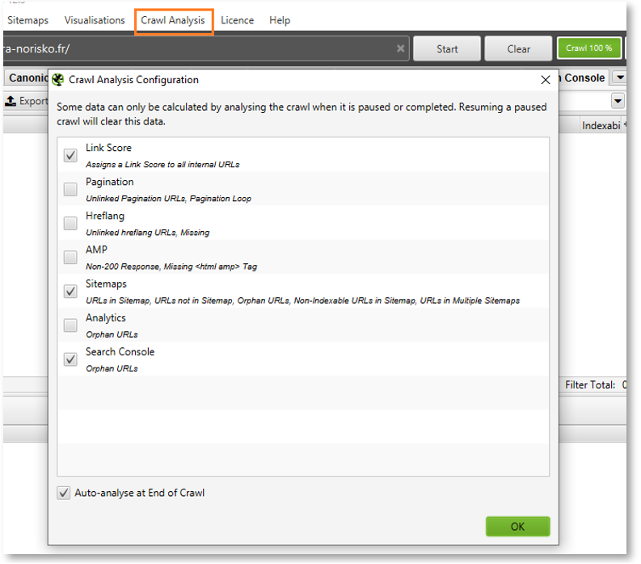
Crawl analysis
Voici les différentes comparaisons qui peuvent être effectuées entre les URL crawlées via des liens, et celles découvertes par d’autres biais que des liens :
- URL de pagination (balises prev/next) ne recevant pas de liens ;
- Balises hreflang manquantes ou non maillées ;
- URL AMP qui ne répondent pas correctement ou absence de bi-directionnalité (canonical vs AMP URL) ;
- URL maillées et absentes des sitemaps, URL présentes dans les sitemaps et non maillées, URL non-indexables dans les sitemaps, etc. ;
- URL détectées dans Google Search Console ou Google Analytics (ayant potentiellement généré du trafic ou des impressions), mais non découvertes via le système de liens.
Concernant les sitemaps, il aura fallu paramétrer en amont du crawl les URL de ces derniers :
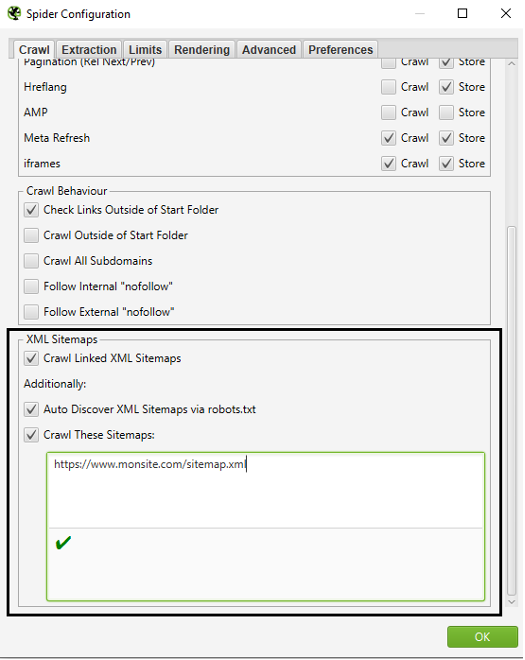
Utilisation des Sitemaps dans le cadre du crawl
Pour ce qui est des outils de Google, il est possible de les connecter a posteriori (Configuration > API access), puis de lancer des requêtes aux API avant de lancer la fonction « Crawl analysis » :
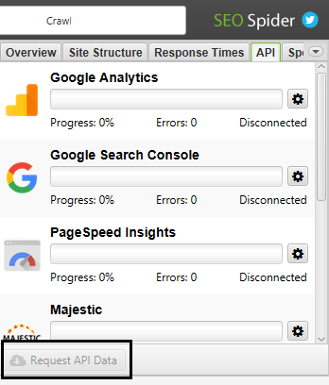
Requêtes vers les API afin de découvrir des URL orphelines
Pour chacun des éléments observés, de nouveaux filtres seront disponibles dans les onglets concernés. Voici un exemple pour la partie « Sitemaps » :
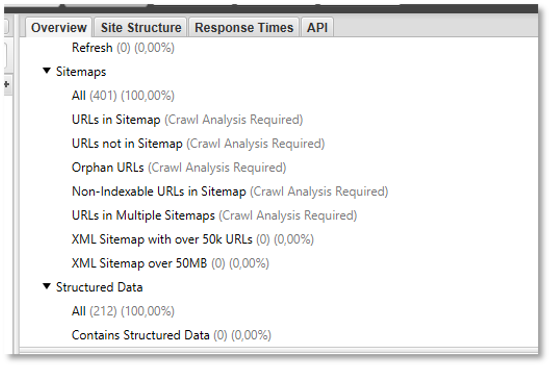
URL des Sitemap vs crawl : nécessité de lancer une analyse
Un fois l’analyse de crawl lancée, on pourra identifier la présence d’URL détectées dans les Sitemaps, mais qui ne reçoivent pas de liens via le maillage interne, afin de mener à bien les optimisations adéquates.
Un export de l’ensemble des URL orphelines est disponible dans le menu « Report » (Orphan pages), afin de découvrir l’ensemble des URL trouvées et non maillées, ainsi que leur provenance (Sitemap, Search Console, etc.). Cette fonction offre de réelles opportunités, afin de permettre une amélioration du maillage interne, les URL orphelines n’étant pas rares sur de nombreux sites web.
Une meilleure distribution de la popularité, tout en respectant les affinités sémantiques entre vos pages vous permettra donc d’améliorer votre visibilité.
Saviez-vous que les outils de crawl comme Screaming Frog recelaient tant de fonctionnalités ?

![]() Aymeric Bouillat, Consultant SEO senior chez Novalem (https://www.novalem.fr/)
Aymeric Bouillat, Consultant SEO senior chez Novalem (https://www.novalem.fr/)





![Copyright Trolling en France : comprendre et contrôler les abus d’une pratique controversée [Partie 2] - Stéphanie Barge](https://www.reacteur.com/content/uploads/2024/05/2024-05-reacteur-stephanie-barge.png)
![Copyright Trolling en France : comprendre et contrôler les abus d’une pratique controversée [Partie 1]- Stéphanie Barge](https://www.reacteur.com/content/uploads/2024/04/2024-04-reacteur-stephanie-barge.png)


5
4.5