
 S’il est un domaine finalement assez peu abordé en SEO, c’est bien le référencement des images, ce qui est étrange car le moteur de recherche de Google dédié à ce format est l’un des plus utilisés par les internautes dans le monde entier. Cette série de trois articles a donc pour objectif de comprendre comment cet outil fonctionne, comment est-ce qu’il peut générer du trafic sur un site et comment optimiser sa stratégie de visibilité pour cela. Après l’analyse du comportement des utilisateurs qui utilisent cet outil et les différents critères de pertinence utilisés par le moteur ces derniers mois, plongeons-nous dans l’avenir avec la recherche sensorielle qui fera peut-être bientôt partie de notre quotidien.
S’il est un domaine finalement assez peu abordé en SEO, c’est bien le référencement des images, ce qui est étrange car le moteur de recherche de Google dédié à ce format est l’un des plus utilisés par les internautes dans le monde entier. Cette série de trois articles a donc pour objectif de comprendre comment cet outil fonctionne, comment est-ce qu’il peut générer du trafic sur un site et comment optimiser sa stratégie de visibilité pour cela. Après l’analyse du comportement des utilisateurs qui utilisent cet outil et les différents critères de pertinence utilisés par le moteur ces derniers mois, plongeons-nous dans l’avenir avec la recherche sensorielle qui fera peut-être bientôt partie de notre quotidien.
 S’il est un domaine finalement assez peu abordé en SEO, c’est bien le référencement des images, ce qui est étrange car le moteur de recherche de Google dédié à ce format est l’un des plus utilisés par les internautes dans le monde entier. Cette série de trois articles a donc pour objectif de comprendre comment cet outil fonctionne, comment est-ce qu’il peut générer du trafic sur un site et comment optimiser sa stratégie de visibilité pour cela. Après l’analyse du comportement des utilisateurs qui utilisent cet outil et les différents critères de pertinence utilisés par le moteur ces derniers mois, plongeons-nous dans l’avenir avec la recherche sensorielle qui fera peut-être bientôt partie de notre quotidien.
S’il est un domaine finalement assez peu abordé en SEO, c’est bien le référencement des images, ce qui est étrange car le moteur de recherche de Google dédié à ce format est l’un des plus utilisés par les internautes dans le monde entier. Cette série de trois articles a donc pour objectif de comprendre comment cet outil fonctionne, comment est-ce qu’il peut générer du trafic sur un site et comment optimiser sa stratégie de visibilité pour cela. Après l’analyse du comportement des utilisateurs qui utilisent cet outil et les différents critères de pertinence utilisés par le moteur ces derniers mois, plongeons-nous dans l’avenir avec la recherche sensorielle qui fera peut-être bientôt partie de notre quotidien.Voici la 3ème et la dernière partie de notre feuilleton sur le référencement des images.
Dans la première partie de notre série, au mois de mai, nous avons passé en revue la part de la recherche d’images au global et par secteur d’activité, les questions de tracking et les particularités comportementales des internautes.
Dans la deuxième partie (juin), nous nous sommes focalisé sur l’optimisation des images et les critères de classement. À travers des tests réalisés pour notre étude, nous avons identifié les leviers efficaces du référencement des images.
Et finalement pour conclure, nous allons nous projeter sur l’avenir de la recherche visuelle et des possibles changements dans les résultats de recherche d’images.
Des informations associées vers la reconnaissance du contenu des images
Avril 2008. Beijing, Chine. Lors de la conférence annuelle WWW 2008, deux ingénieurs de Google, Yushi Jing et Shumeet Baluja présentent le rapport « PageRank for Product Image Search » dans lequel ils partagent leur vision du futur de la recherche visuelle.
Ce document est particulièrement intéressant, car Google y évoquait déjà les limites d’utilisation des données uniquement associées aux images (alt, nom du fichier, légende) pour classer celles-ci :
« Les moteurs de recherche commerciaux s’appuient souvent uniquement sur les indices textuels des pages dans lesquelles les images sont intégrées pour classer les images, et ignorent souvent entièrement le contenu des images elles-mêmes comme signal de classement ».
Les ingénieurs ont exprimé leur vision selon laquelle, pour classer de manière efficace les images, il était important de reconnaître le contenu de l’image (et non pas ce qui l’entoure) et mettre en place un système de pondération efficace comme le PageRank dans la recherche web classique.
Le problème est que le PageRank classique se base sur les hyperliens, et il n’est pas forcément adapté pour la recherche d’images (ce sont les pages web qui sont reliées moyennant les liens, mais non pas les images). Une approche expliquée dans le rapport propose de remplacer le graphe de liens par un graphe basé sur la similitude des images et ainsi juger leur importance :
« Les gens ont tendance à naviguer depuis une image vers d’autres images similaires. En traitant les images comme des documents Web et leurs similitudes comme des hyperliens visuels probabilistes, nous estimons la probabilité des images vues par un utilisateur de servir de hyperliens visuels ».
Lors de la conférence, les ingénieurs ont confirmé que Google était en mesure de reconnaître le contenu des images (en 2008 !) et possédait des ressources suffisantes pour l’implémenter dans le moteur de recherche.
Le domaine de la compréhension des images est complexe et nécessite surtout des ressources conséquentes, humaines (entraîner les algorithmes d’apprentissage automatique) comme technologiques (traitement des visuels et calculs).
Les gros acteurs ont très vite compris que c’était un des chantiers sur lequel l’apport de la communauté peut être plus efficace que d’essayer de pousser le domaine juste avec ses ressources internes.
Ainsi, de multiples initiatives de crowdsourcing ont été entreprises pour favoriser son développement. Parmi les plus connues on peut se souvenir de la fameuse compétition ImageNet ILSVRC (2010 – 2017) ou encore le jeu Google Image Labeler (2006 – 2011, 2016).
Google Image Labeler est une plate-forme d’étiquetage d’images organisée sous forme de jeu. L’utilisateur entre sur le site et fait un choix : s’autoriser ou participer au jeu de manière anonyme. Ensuite la personne est associée à un autre utilisateur aléatoire en ligne sur le site. Les partenaires disposent de 90 secondes, pendant lesquelles le système leur montre le même set d’images de l’index de recherche Google Images. Chacune des paires doit spécifier autant de tags que possible pour l’image. Si au moins un des tags est le même pour les deux participants, ils gagnent des points et passent à l’image suivante.
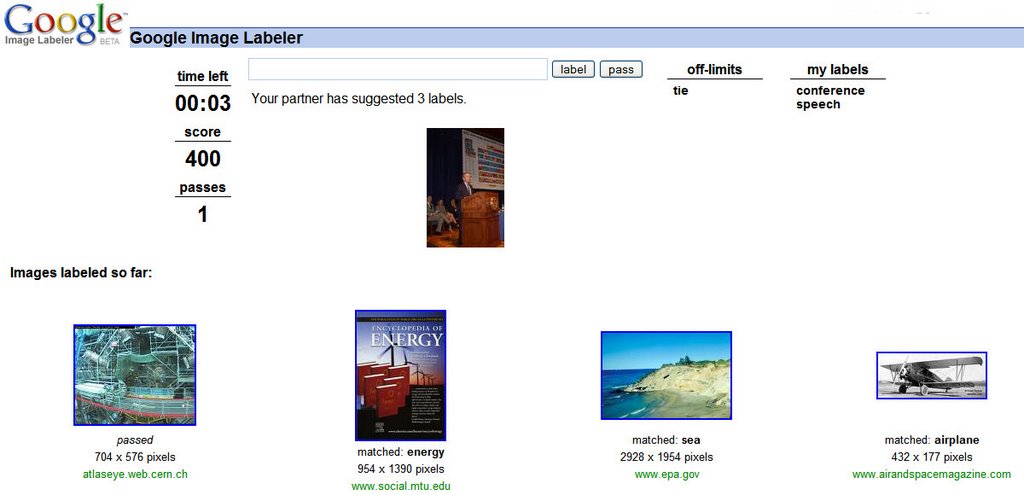
Exemple d’interface (d’époque) pour Google Image Labeler

Exemple d’interface (d’époque) pour Google Image Labeler
Aujourd’hui, Google utilise des technologies conçues et développées en interne par ses équipes, mais n’hésite pas non plus à faire des acquisitions d’entreprises avec des expertises appropriées comme ce fut le cas de DeepMind, DNNresearch, Pittpatt, NeverVision, JetPac etc.
Compréhension des images et le SEO
Du point de vue SEO classique, la compréhension d’images est un énorme pas en avant. Cela contribue à l’amélioration de la qualité des résultats de recherche, car il devient presque impossible de tromper un moteur de recherche en étiquetant mal des visuels ou les insérant dans un entourage non-approprié.
Mais une chose est de savoir ce que Google est capable de faire et une autre ce qu’il fait réellement notamment dans le domaine de la recherche.
Pour analyser cet aspect, nous avons mené une série de tests avec la recherche de Google.
Test #1 : Reconnaissance des numéros sur les plaques d’immatriculation
Déroulement :
Pour cette première expérience, nous avons généré une série de plaques d’immatriculation existantes, mais qui respectaient les formats agréés. Les images portaient des noms choisis au hasard sans mention de ce qui est affiché sur l’image. Les images des plaques ont été publié sur des pages web et soumis dans Google à travers la Search Console.
Résultats :
Le jour même, Google a indexé toutes les pages soumises via la Search Console. Deux jours plus tard, les images ont commencé à être trouvables dans Google Images sur les requêtes correspondant aux numéros des plaques d’immatriculation :
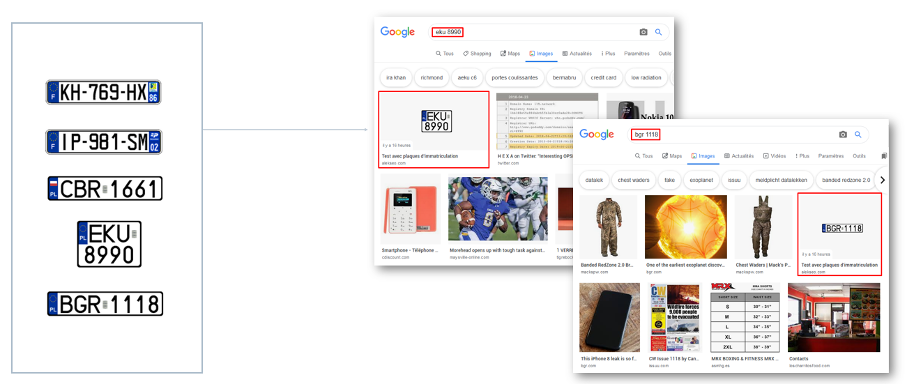
Résultat du test Google sur les plaques d’immatriculation
Ce test a démontré que Google était non seulement capable de reconnaître un texte simple sur les images, mais utilisait également ces capacités dans les résultats de recherche.
Test #2 : Reconnaissance de phrases par-dessus l’image
Pour la deuxième expérience, nous avons souhaité aller un peu plus loin et tester si Google arrivait à lire non seulement des courtes chaînes de caractères, mais aussi des séquences plus longues de type phrase.
Nous avons de nouveau généré une série d’images originales. Nous avons créé une série de phrases inexistantes (parfois avec des mots inventés, sans beaucoup de sens) qui ont été intégrées sur les images (police standard, texte blanc sur fond noir). La démarche était la même que dans le premier test : les images ont été intégrées dans des pages web, puis soumises via la Search Console.
Environ trois jours plus tard, les images sont devenues trouvables sur les phrases intégrées :
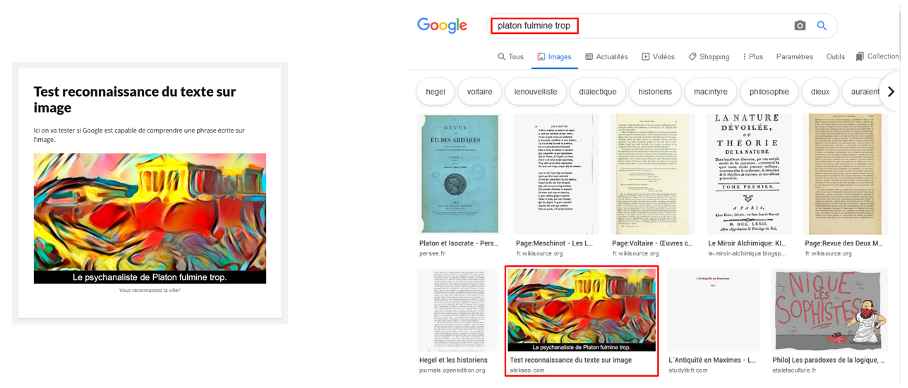
Résultat du test Google sur les phrases au sein d’images
Ce deuxième test a démontré que Google était capable de reconnaître des séquences de mots plus longues (au moins jusqu’à 7 mots) sur les images. En outre, le moteur de recherche utilise ces technologies aujourd’hui dans la recherche d’images.
De la recherche textuelle à la recherche sensorielle
Du point de vue d’objet de recherche, la recherche visuelle fait partie d’un domaine plus vaste appelée Sensory Search ou recherche sensorielle qui prévoit de nouveaux types d’entrée autres que les requêtes textuelles classiques, notamment des visuels et des commandes vocales.
Si auparavant pour savoir à quelle race appartenait un chien assis devant nous, on devait le décrire avec des mots dans Google et ensuite essayer de l’identifier sur des milliers de photos proposées. Depuis peu, on peut le capturer avec notre appareil photo et transférer directement l’image dans Google Images pour analyse.
Selon l’étude de Slyce.it en 2018, 74% d’acheteurs web ont affirmé que les recherches via les mots-clés ne permettaient pas d’avoir des résultats satisfaisants.
Ces résultats sont en fait tout à fait naturels : selon une étude du MIT, 90% de toutes les informations qui passent dans notre cerveau sont visuelles. Quand on retient les choses ou qu’on s’en souvient, on traite majoritairement des images. Et à quel point est-ce plus facile d’expliquer certaines choses avec une image qu’avec des mots ?
La recherche sensorielle est un domaine relativement récent, mais sur lequel les acteurs majeurs de l’IT mènent des combats acharnés principalement sur 2 axes :
- Utilisation d’image comme requête d’internaute ;
- Identification d’objets du monde qui entoure (réalité augmentée).
La compréhension des images est un domaine extrêmement complexe qui nécessite des ressources, des algorithmes particuliers et beaucoup d’apprentissage. Et pour arriver aux résultats qui nous sont proposés aujourd’hui, Google est passé par des chemins épineux.
En 2013 la reconnaissance du contenu sur les images et la recherche d’images similaires par Google s’effectuait en se basant sur la colorimétrie – une approche assez efficace en termes de ressources nécessaires, mais proposant des résultats assez controversés :
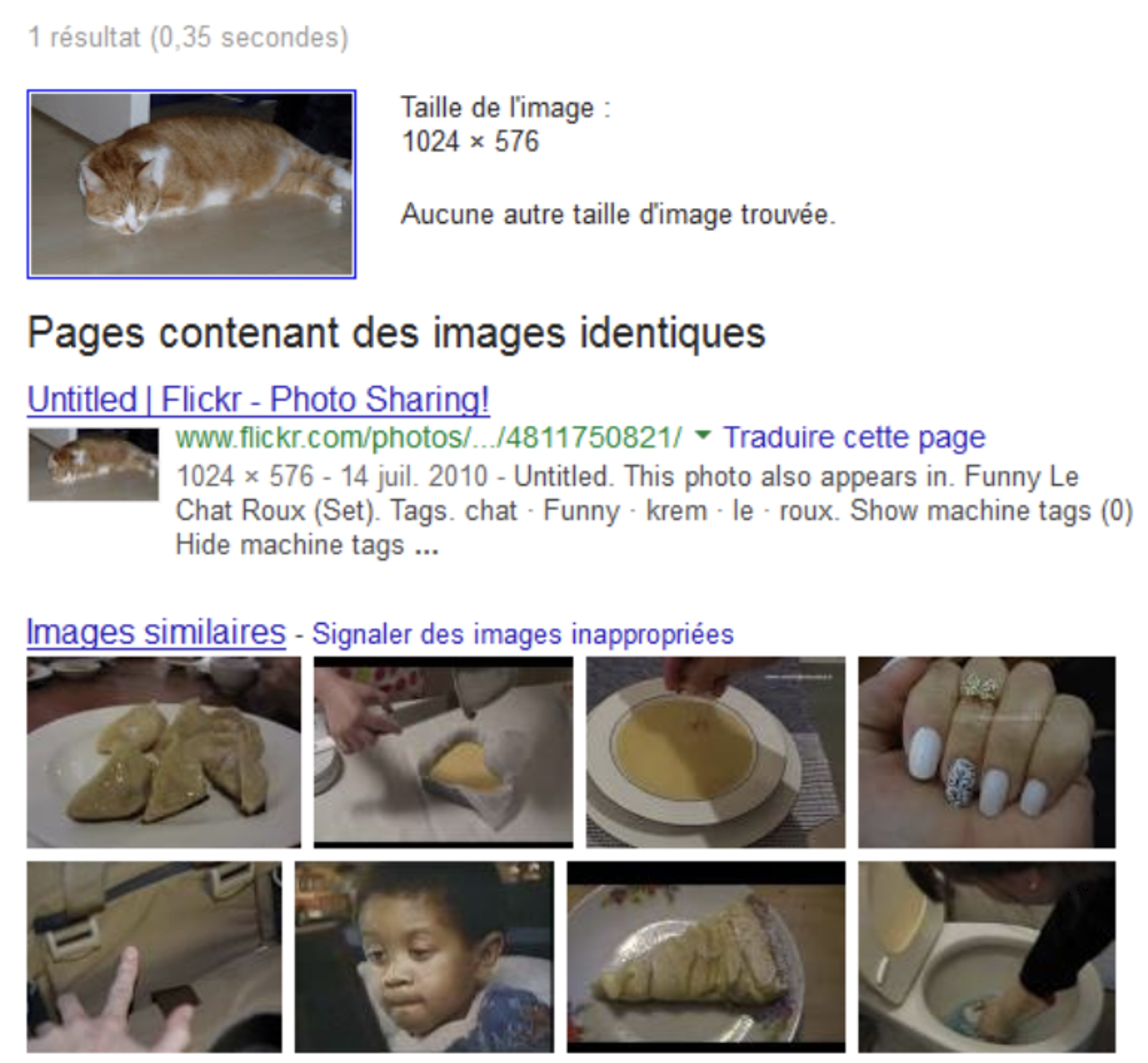
En soumettant dans Google Images une photo d’un chat roux en 2013, le moteur retournait
des résultats basés sur la colorimétrie : pertinent pour la couleur, mais complètement à la rue pour le sens.
Évidemment, Google ne pouvait pas laisser le problème tel quel, et depuis, beaucoup d’avancées ont été faites sur le sujet, ce qui a permis de passer de la reconnaissance basée sur la colorimétrie à la reconnaissance des objets. Voici les résultats pour la même image en 2019 :
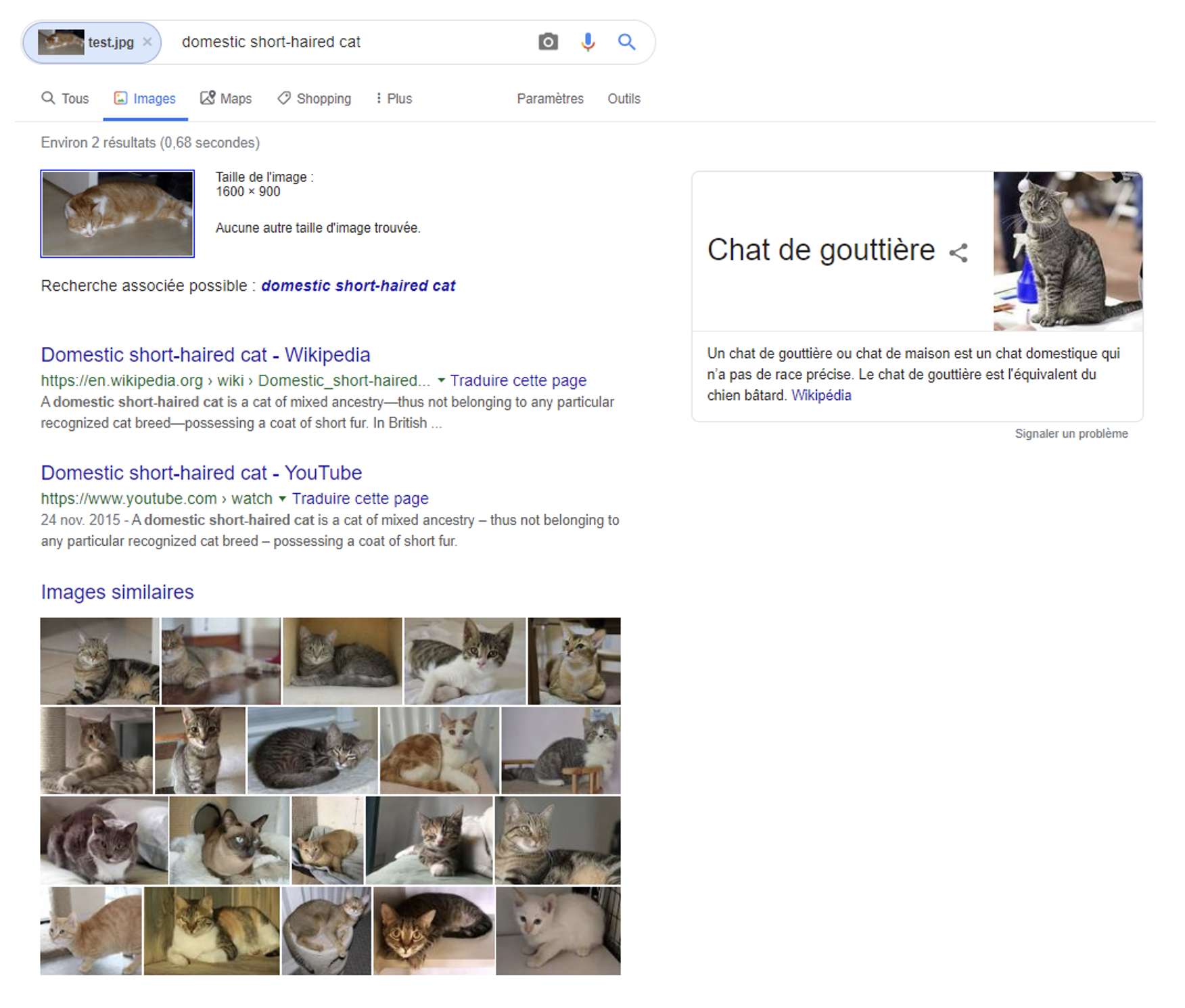
Avec la même image en 2019, l’objet (chat) devient plus important que la couleur.
Aujourd’hui, pour comprendre les capacités de compréhension des images par Google, il suffit de se rendre sur la page https://cloud.google.com/vision/ et soumettre ses propres visuels :
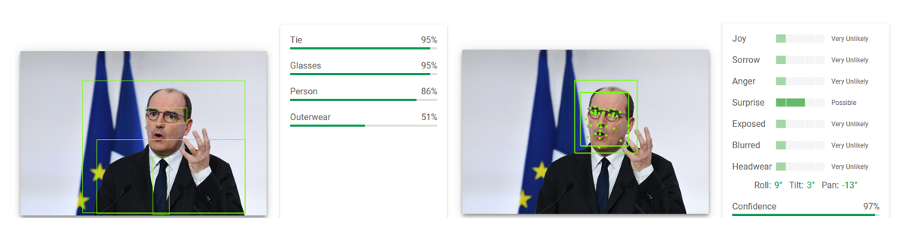
L’algorithme de Google est persuadé que lors de l’annonce du dernier confinement, le premier-ministre était surpris (confidence à 97%).
Un autre axe de la recherche sensorielle est la réalité augmentée ou l’interaction avec le monde qui entoure.
Même si Google et Microsoft ont aussi développé leurs propres moteurs de recherche visuels, c’est Pinterest (avec la technologie Pinterest Lens) qui mérite d’être considéré comme pionnier.
Du côté du géant de Mountain View, la détection des objets du monde réel est assurée par Google Lens annoncé en 2017 lors de la conférence annuelle Google I/O. Il propose de nouveaux moyens d’interaction avec le monde qui nous entoure en permettant d’en capturer ses éléments et de les envoyer directement dans Google.
Aujourd’hui, la technologie est présentée par l’application dédiée Google Lens et intégrée dans l’application de Google, Google Photos, sur les terminaux Android.
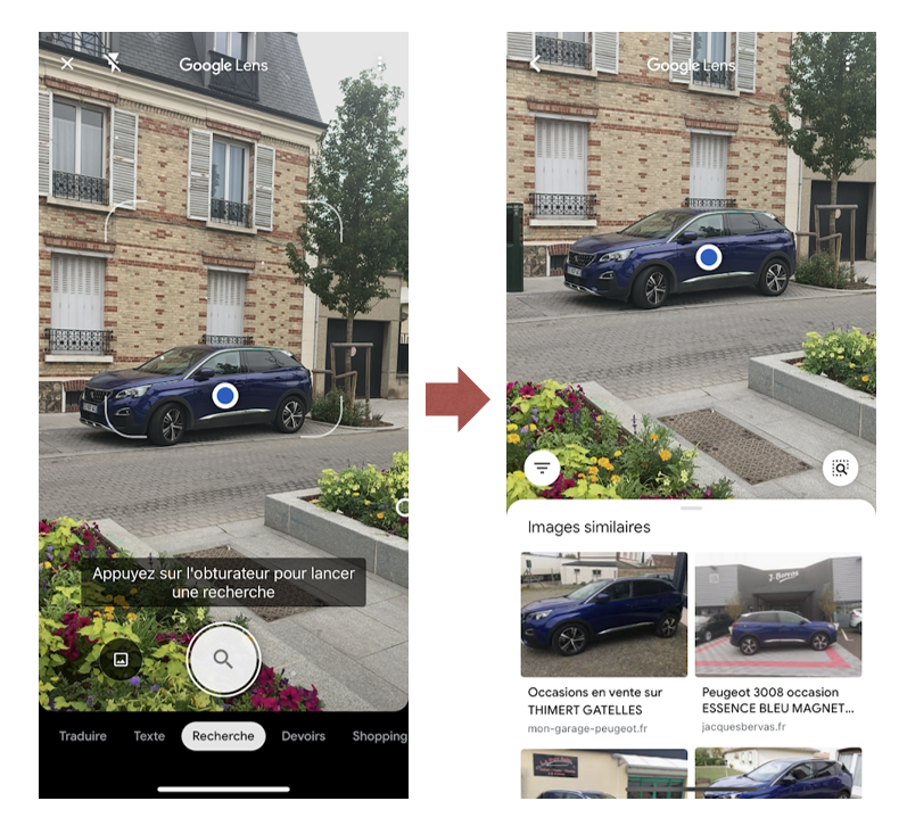
Google Lens identifie correctement la marque et le modèle de la voiture
(une Peugeot 3008) et propose des liens vers des sites où celle-ci est en vente.
La reconnaissance faciale comme critère de classement
La reconnaissance des contenus visuels étant un domaine vaste, elle trouve son utilité dans d’autres sous-domaines dont la reconnaissance faciale. Son application commence par des opérations banales comme le déverrouillage de téléphones mobiles, et va vers des implémentations complexes à large échelle comme des caméras capturant les expressions de visages et mesurant la satisfaction des gens, comme dans les transports en communs à Dubai.
Pour le SEO, ce qui peut nous intéresser est le brevet intitulé « Ranking Query Results Using Biometric Parameters » déposé par Google en 2016. Les auteurs du brevet y exposent la possibilité d’utiliser les données biométriques provenant de différents appareils personnels pour modifier les résultats de recherche.
En l’occurrence, il est proposé d’utiliser la caméra du téléphone mobile pour capturer les changements d’expressions du visage lors de la navigation sur les résultats de recherche de Google. En mesurant les critères comme dilatation de la pupille, les secousses oculaires, la rougeur du visage ou encore la diminution du taux de clignotement, le moteur peut supposer si l’internaute est satisfait des résultats de recherche qui lui sont proposés et de les modifier en temps réel :
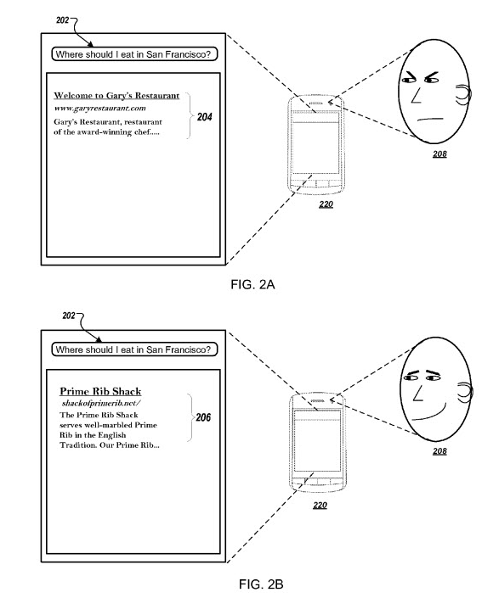
Brevet Google sur l’utilisation des données biométriques dans un moteur de recherche.
Mais pour le moment, rassurons-nous par le fait qu’un brevet n’est pas directement directement synonyme d’implémentation.
Conclusion
« L’avenir de la recherche sera axé sur les images plutôt que sur les mots-clés », a dit lors d’un de ses interview le CEO de Pinterest Ben Silbermann.
Il y a de la raison dans son point de vue, car les mots sont une abstraction créée et propre aux humains, mais les visuels sont innés et tout à fait naturels pour notre cerveau pour retenir les informations, s’en souvenir, expliquer, rechercher, comparer, etc.
De la même manière qu’il est souvent plus facile de faire une commande vocale que de taper la requête, prendre en photo une poussette bébé pour trouver tout de suite où en acheter une est plus facile que de regarder des centaines de pages web.
Mais toutes ces options demandent des technologies avancées de la part des moteurs de recherche, notamment dans le domaine de la reconnaissance des images.
Nos tests ont démontré que Google appliquait déjà certaines de ses technologies de compréhension d’images dans son moteur recherche. Notamment, il est capable de reconnaître du texte sur les images et de positionner les images dessus, même si leur entourage n’en parle pas. Et c’est ce qu’il fait déjà aujourd’hui.
On peut s’attendre à ce que Google se mette beaucoup plus à l’intégration de la recherche visuelle avec ses autres produits, comme Google Maps et Shopping. Avec un apprentissage en continu de plus en plus massif des algorithmes, la recherche d’images proposera à l’avenir des résultats plus pertinents, précis et variés.
Google Lens étant aujourd’hui un outil assez peu connu chez une grande partie d’utilisateurs mobiles, il sera certainement intégré à d’autres produits de manière plus intuitive, accompagné des campagnes de communication de Google.
En tout cas, on doit avouer qu’au niveau des usages, il reste un écart entre la technologie de recherche visuelle et les comportements des consommateurs. Ces derniers ne sont tout simplement pas habitués à utiliser l’appareil photo de leur smartphone comme entrée de recherche et, bien que cela change, les progrès prendront certainement du temps.





![Copyright Trolling en France : comprendre et contrôler les abus d’une pratique controversée [Partie 2] - Stéphanie Barge](https://www.reacteur.com/content/uploads/2024/05/2024-05-reacteur-stephanie-barge.png)
![Copyright Trolling en France : comprendre et contrôler les abus d’une pratique controversée [Partie 1]- Stéphanie Barge](https://www.reacteur.com/content/uploads/2024/04/2024-04-reacteur-stephanie-barge.png)


5