
 Le fichier robots.txt est une composante essentielle dans l’art de mettre en place sur son site web un crawl de qualité par les robots des moteurs de recherche. Mais sa syntaxe n’est pas toujours si simple que cela et les erreurs sont parfois fréquentes. Voici une petite revue d’effectif des bonnes pratiques à mettre en place pour avoir le moins de surprises possible…
Le fichier robots.txt est une composante essentielle dans l’art de mettre en place sur son site web un crawl de qualité par les robots des moteurs de recherche. Mais sa syntaxe n’est pas toujours si simple que cela et les erreurs sont parfois fréquentes. Voici une petite revue d’effectif des bonnes pratiques à mettre en place pour avoir le moins de surprises possible…
 Le fichier robots.txt est une composante essentielle dans l’art de mettre en place sur son site web un crawl de qualité par les robots des moteurs de recherche. Mais sa syntaxe n’est pas toujours si simple que cela et les erreurs sont parfois fréquentes. Voici une petite revue d’effectif des bonnes pratiques à mettre en place pour avoir le moins de surprises possible…
Le fichier robots.txt est une composante essentielle dans l’art de mettre en place sur son site web un crawl de qualité par les robots des moteurs de recherche. Mais sa syntaxe n’est pas toujours si simple que cela et les erreurs sont parfois fréquentes. Voici une petite revue d’effectif des bonnes pratiques à mettre en place pour avoir le moins de surprises possible…Le fichier robots.txt est un atout majeur pour maîtriser le crawl des moteurs et autres outils sur un site web. Placé à la racine d’un site (ex : www.monsite.com/robots.txt), il permet via différentes directives l’accès ou non à certaines ressources par les crawlers. Cela peut concerner des URL non pertinentes par exemple (filtres à facettes, URL techniques, URL liées à l’interface d’administration, etc.) afin d’améliorer la qualité des pages indexées, mais aussi le crawl budget pour les sites à forte volumétrie de pages.
Il est visité régulièrement par les robots d’exploration des moteurs de recherche, et certains outils (ex : aspirateurs de site web) ne les contrôlent que lorsqu’il y a appels spécifiques. Nous passerons en revue dans cet article les erreurs communes relatives au fichier robots.txt, ainsi que des astuces pour mieux optimiser ce fichier et en faciliter sa lecture et son maintien dans le temps. Mais revenons avant tout sur une notion importante relative au crawl et à l’indexation.
Crawl ne rime pas avec indexation
Ce fichier est souvent mal compris : il ne faut pas croire qu’il permette de désindexer des URL, mais plutôt de restreindre le crawl sur des URL, et donc de potentiellement d’empêcher l’indexation de pages spécifiques puisqu’elles ne peuvent pas être crawlées.
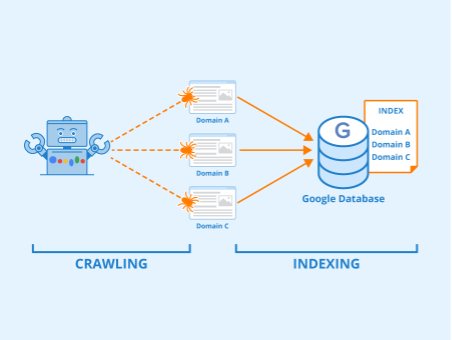
Différences entre crawl et indexation. Author: Indexing Seobility – License: CC BY-SA 4.0
Pour désindexer des pages, il est nécessaire de passer par la balise <meta name=robots content= »noindex »> (ou via les en-têtes HTTP avec la directive X-Robots-Tag). Il faut bien comprendre qu’une page crawlable ne sera pas forcement indexée (pertinence, duplication, problème technique ou directive noindex), et qu’à l’inverse une page non crawlable peut parfois être indexée (ex : restriction dans le robots.txt ultérieure à l’indexation, indexation malgré une restriction !)
Google et le robots.txt
Toujours efficace ?
Bien que Google soit censé respecter le fichier robots.txt, il est possible qu’il remonte malgré tout dans ses résultats, des pages bloquées dans le fichier robots.txt.
Il peut s’agir d’URLs qui reçoivent plusieurs liens externes, que Google indexera sans même les visiter, en utilisant le texte descriptif / ancre de lien comme information pour juger de sa thématique, et éventuellement renommer le titre de la page dans les résultats. Il indexera juste l’URL et non son contenu puisqu’il ne peut pas visiter la page, mais elle pourra malgré tout remonter sous cette forme dans les pages de résultats :

Page présente dans l’index malgré une restriction.


![Les étapes essentielles pour une refonte d’arborescence réussie [Le Point]](https://www.reacteur.com/content/uploads/2025/03/2025-02-reacteur-julien-ferras-527x297.png)
![Les étapes essentielles pour une refonte d’arborescence réussie [Le Point]](https://www.reacteur.com/content/uploads/2025/03/2025-02-reacteur-julien-ferras-190x190.png)





![Comment utiliser l'IA et la data pour augmenter vos études sémantiques ? [Partie 2] - Franck Mairot](https://www.reacteur.com/content/uploads/2024/09/2024-09-reacteur-franck-mairot.png)
5