 Les expressions régulières décrivent des sous-ensembles de chaînes de caractères. Souvent peu appréciées pour leur syntaxe parfois alambiquée, elles offrent pourtant de réelles possibilités pour les développeurs et les référenceurs. Les regex (mot-valise issu de regular expression) répondent à d’innombrables usages, notamment en matière d’extraction de contenus ou de reconnaissance de chaînes, souvent utiles dans les outils ou programmes préférés des SEO.
Les expressions régulières décrivent des sous-ensembles de chaînes de caractères. Souvent peu appréciées pour leur syntaxe parfois alambiquée, elles offrent pourtant de réelles possibilités pour les développeurs et les référenceurs. Les regex (mot-valise issu de regular expression) répondent à d’innombrables usages, notamment en matière d’extraction de contenus ou de reconnaissance de chaînes, souvent utiles dans les outils ou programmes préférés des SEO.
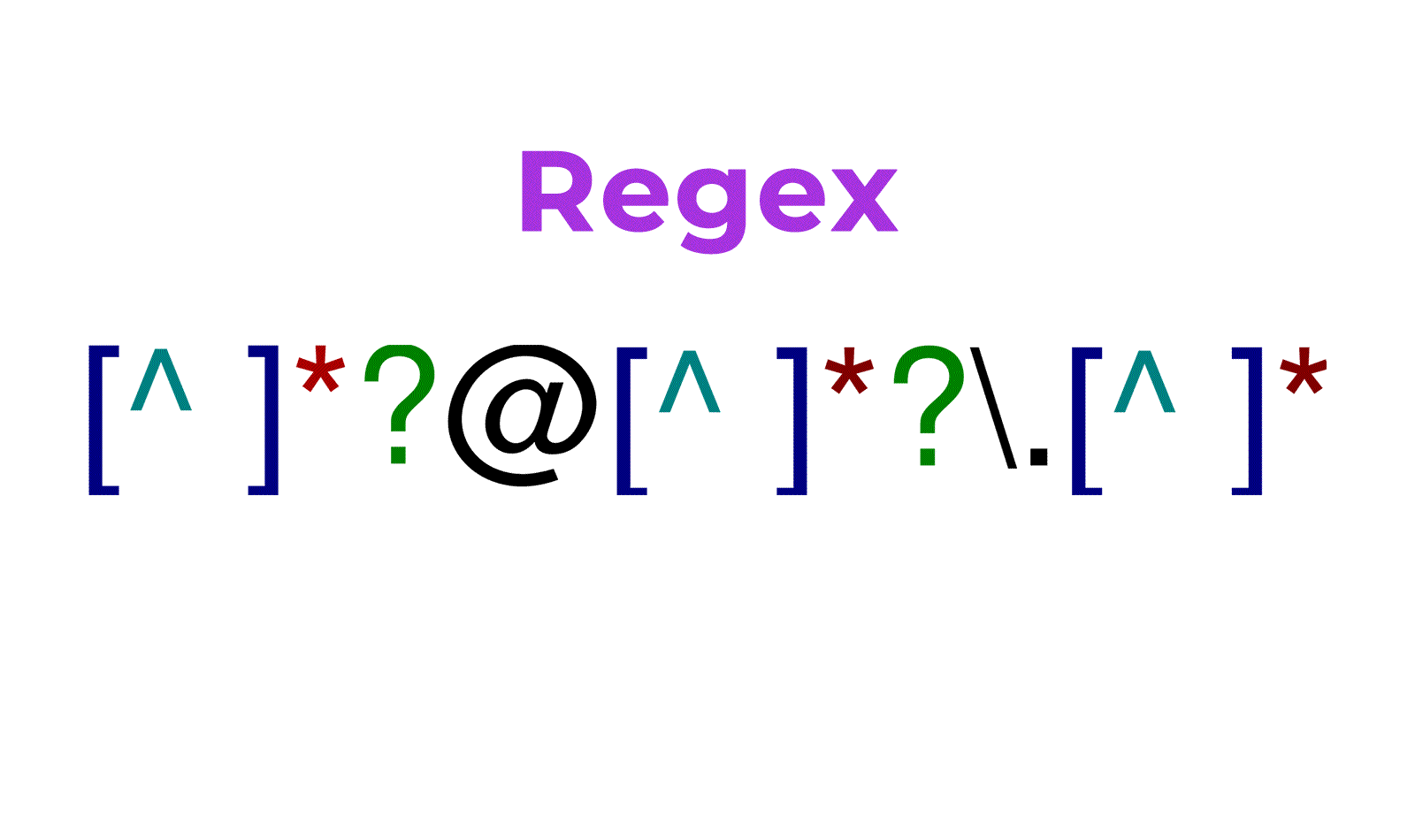 Les expressions régulières décrivent des sous-ensembles de chaînes de caractères. Souvent peu appréciées pour leur syntaxe parfois alambiquée, elles offrent pourtant de réelles possibilités pour les développeurs et les référenceurs. Les regex (mot-valise issu de regular expression) répondent à d’innombrables usages, notamment en matière d’extraction de contenus ou de reconnaissance de chaînes, souvent utiles dans les outils ou programmes préférés des SEO.
Les expressions régulières décrivent des sous-ensembles de chaînes de caractères. Souvent peu appréciées pour leur syntaxe parfois alambiquée, elles offrent pourtant de réelles possibilités pour les développeurs et les référenceurs. Les regex (mot-valise issu de regular expression) répondent à d’innombrables usages, notamment en matière d’extraction de contenus ou de reconnaissance de chaînes, souvent utiles dans les outils ou programmes préférés des SEO.La maîtrise des expressions régulières passe par une bonne connaissance de la syntaxe des motifs (modèles ou pattern en anglais). Chaque développeur ou référenceur doit être capable de lire et d’écrire des regex plus ou moins complexes pour atteindre ses objectifs ou aller plus loin dans les optimisations.
Comment aborder les expressions régulières ?
La complexité d’écriture de certaines expressions rationnelles (autre nom attribué aux regex) a plus tendance à rebuter les profanes qu’à les enjouer. Les exemples ci-dessous, qui décrivent le schéma typique d’une adresse email, ont de quoi faire peur au premier abord :
# Version longue :
^[A-Za-z0-9\'\._+-]+@([A-Za-z0-9_-]+\.)*+[A-Za-z]{2,}
# Variante en version « compressée » :
^[\w-\.]+@([\w-]+\.)+[\w-]{2,}$
Ces deux premiers exemples, équivalents, démontrent l’étendue des possibilités d’écriture mais aussi la complexité apparente de la syntaxe des motifs. Vous pouvez donc vous demander par où commencer, et comment arriver à atteindre des objectifs encore plus complexes que la description d’un schéma d’adresse email. En réalité, c’est sûrement bien plus simple qu’en apparence, car l’idée est avant tout de formaliser à l’oral ou à l’écrit ce dont on a besoin.
L’idée générale est de démarrer avec un objectif clair qui peut être facilement décrit. Ensuite, vous n’avez plus qu’à transcrire cette formalisation dans la syntaxe propre aux regex. Avant d’aborder la syntaxe en détail, prenez l’exemple d’un hashtag. Comment les réseaux sociaux ont-ils réussi à extraire ou intégrer ce type de chaîne dans les plateformes ? D’abord il a fallu décrire simplement ce à quoi ressemble un hashtag, puis développer l’extraction/intégration. Vous pouvez donc raisonner ainsi : un hashtag est un mot, précédé d’un hash (croisillon représenté par le caractère « dièse » en France), lui-même précédé par un espace ou une ponctuation (ou le début de la phrase), et conclut par un espace ou une ponctuation (selon que l’on est au milieu ou en fin de phrase).
Il ne reste qu’à développer, à l’aide de la syntaxe des regex, ce que vous venez de décrire, étape par étape :
// Étape 1 : le hashtag est avant tout un mot : [a-zA-Z0-9_-]+ // On prend toutes les lettres (minuscules et majuscules), les chiffres, l’underscore et le tiret. [\w-]+ // Variante équivalente pour décrire la même chaîne que précédemment. // Étape 2 : le mot est précédé d’un hash (« dièse ») : #[a-zA-Z0-9_-]+ // ou #[\w-]+ (la double syntaxe ne sera plus présentée mais vous avez compris le principe) // Étape 3 : le hashtag est précédé par un espace : [ ]+#[a-zA-Z0-9_-]+ // [ ] peut aussi être remplacé par [[:space:]] ou [\s] (sens plus large) // Étape 4 : le hashtag peut aussi être précédé par une ponctuation plutôt qu’un espace : [ !\?;:\(.]+#[a-zA-Z0-9_-]+ // En théorie, seuls l’espace et la parenthèse ouvrante devraient suffire. // Étape 5 : le hashtag est suivi par un espace ou un caractère de ponctuation : [ !\?;:\).]+#[a-zA-Z0-9_-]+[ !\?;:\).]+ // Étape 6 : le hashtag peut être encadré pour pouvoir l’extraire (si nécessaire) : [ !\?;:\).]+(#[a-zA-Z0-9_-]+)[ !\?;:\).]+
Ce développement point par point montre comment il est possible de réaliser des expressions régulières plus ou moins complexes. L’idée est toujours de partir du sous-ensemble commun, puis de décrire ce qui peut exister autour de lui. Dans la description d’un email, le dénominateur commun est le « @ » par exemple, qui est encadré par des suites de caractères précises en amont et en aval.
L’exemple du hashtag décrit ici est incomplet et n’est pas la meilleure forme possible en termes de regex. De plus, il faudrait forcer l’ajout d’un espace avant et après le texte analysé afin d’éviter les problèmes de début et de fin de chaîne. En effet, si le hashtag est placé en début de phrase par exemple, l’expression écrite ici attend soit un espace, soit une ponctuation, mais pas rien du tout. En ajoutant volontairement un espace en début et fin de chaîne, on évite ces cas problématiques.






![Copyright Trolling en France : comprendre et contrôler les abus d’une pratique controversée [Partie 2] - Stéphanie Barge](https://www.reacteur.com/content/uploads/2024/05/2024-05-reacteur-stephanie-barge.png)
![Copyright Trolling en France : comprendre et contrôler les abus d’une pratique controversée [Partie 1]- Stéphanie Barge](https://www.reacteur.com/content/uploads/2024/04/2024-04-reacteur-stephanie-barge.png)


5