
 Le « Budget crawl » représente les ressources de temps-machine allouées par un moteur de recherche à l’exploration de votre site. Cette notion, dont on parle très souvent depuis quelques temps, doit être prise en compte dans certains cas. Alors, comment Google calcule-t-il ce « crawl budget » et surtout, votre site est-il concerné ?
Le « Budget crawl » représente les ressources de temps-machine allouées par un moteur de recherche à l’exploration de votre site. Cette notion, dont on parle très souvent depuis quelques temps, doit être prise en compte dans certains cas. Alors, comment Google calcule-t-il ce « crawl budget » et surtout, votre site est-il concerné ?
On entend régulièrement parler du « crawl budget » (ou budget de crawl) dans le monde du référencement naturel. Ce terme représente le temps-machine à allouer à un site par les robots d’exploration lors du crawl. Avec une augmentation exponentielle des pages à crawler par Google et les autres moteurs, il est nécessaire d’améliorer le budget de crawl afin que les moteurs se concentrent sur l’essentiel. Ils doivent non seulement découvrir de nouvelles pages, mais également actualiser celles qui sont connues dans son index.
Plusieurs leviers sont à notre disposition pour améliorer ce « budget d’exploration », comme le nomme Google (limiter l’exploration aux pages pertinentes, améliorer son temps de chargement, etc.), pour ensuite suivre le crawl des robots d’exploration et s’assurer de l’efficacité des optimisations effectuées.
Nous casserons certains mythes dans cet article, et verrons que tous les sites Web ne sont pas concernés par des problématiques de « crawl budget ». Mais avant tout, rappelons en quoi consiste le crawl de Google.
Pour aller plus loin :
➜ Découvrez la formation Crawl et indexation par Olivier Andrieu
Rappel sur le fonctionnement du moteur
Afin de proposer des résultats pertinents dans ses pages de résultats, Google doit visiter et actualiser un très grand nombre de pages qu’il stockera dans son index, afin de répondre au besoin informationnel des internautes via ses pages de résultats. La recherche Google fonctionne donc en 3 étapes :
- Exploration (téléchargement de fichiers texte, image, ou autres) ;
- Indexation (analyse des données téléchargées pour les stocker dans son index) ;
- Classement dans les pages de résultats (grâce aux divers algorithmes de classement).
C’est la phase d’exploration qui sera détaillée dans cet article (en rouge ci-dessous) : Google doit visiter de nouvelles URL et les ajouter à l’ensemble des pages déjà connues.
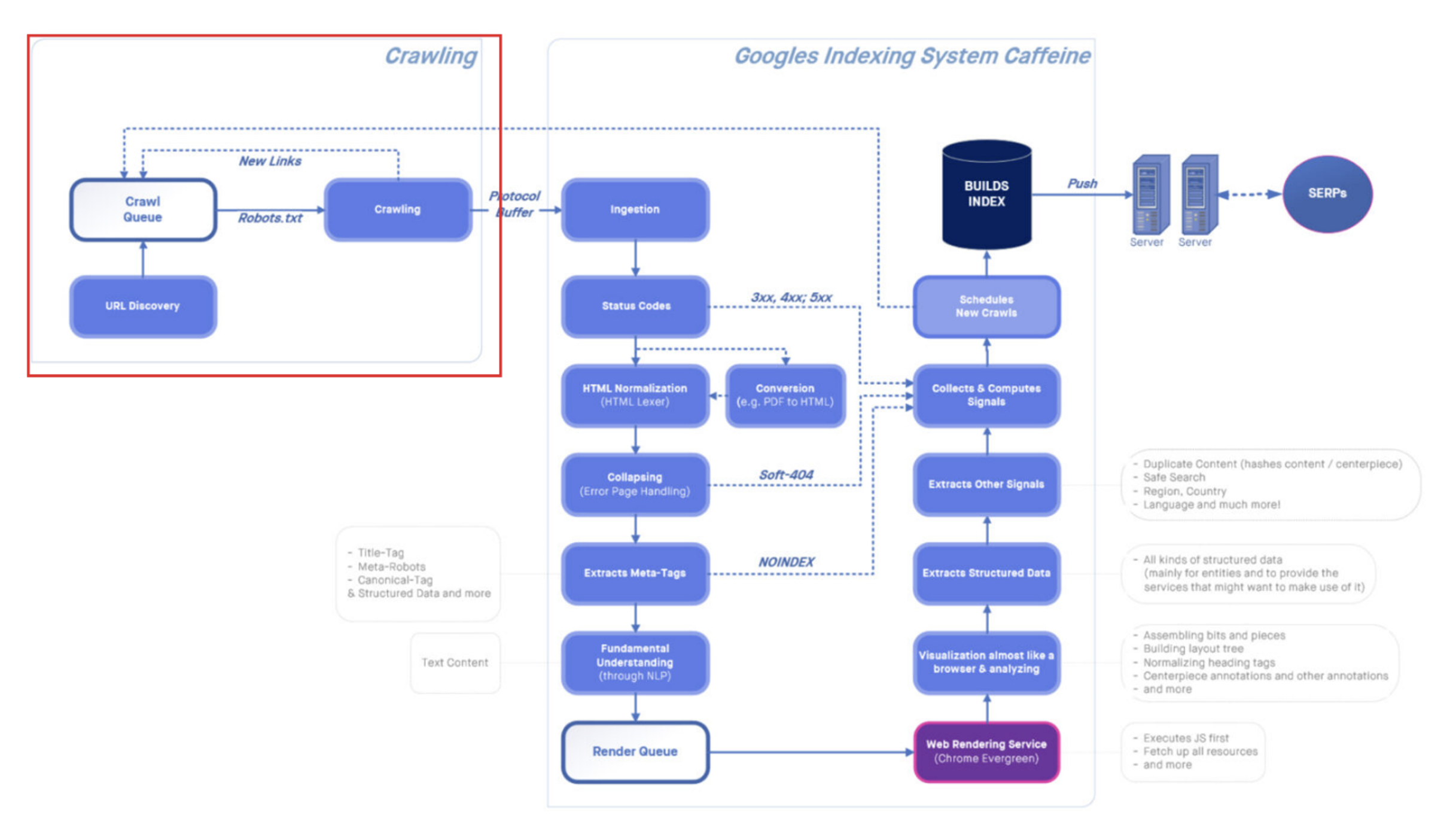
Processus d’exploration, d’indexation et de classement.
Source : https://www.abondance.com/20211112-46544-infographie-le-processus-de-crawl-et-dindexation-de-google.html
Nous savons que Google utilise les liens sous la forme <a href= »/url »>Ancre</a> pour découvrir de nouvelles URL, qui seront ajoutées à sa file d’attente pour être crawlées à leur tour. Mais le crawl est loin de se limiter qu’à des pages Web…
En effet, le crawl peut concerner différents types de fichiers comme les images, les fichiers PDF, mais également les feuilles de style CSS ou encore les fichiers Javascript. Google a besoin de ces fichiers JS et CSS pour être au plus proche de ce que verra l’utilisateur : il faut donc garder à l’esprit que le moteur ne se limite pas qu’aux liens qu’il découvrira via les balises <a href= »/url »> lors de sa phase d’exploration, mais qu’ils visite également des ressources complémentaires.
Bien que cette découverte d’URL se fasse en théorie au travers des balises standardisées (<a><link><script><img>, etc.), le robot d’exploration de Google (Googlebot) peut également suivre des URL sans qu’elles soient incluses dans des balises HTML. Ainsi, une URL sans lien dans le corps d’un texte sera également visitée par ses robots : tout ce qui ressemble à une URL dans le code source d’une page peut potentiellement être crawlé par Googlebot (ce qui peut parfois causer des effets de bord, notamment lors de la découverte d’URL partielles dans un segment de code Javascript).
Le moteur de rendu WRS
Le moteur souhaite être au plus près de ce que voient les utilisateurs finaux, il passe donc par un processus de rendu (WRS = Web Rendering Service) en interprétant les feuilles de styles et les fichiers Javascript, ce qui implique qu’il doit également visiter ces fichiers.
En réalité Google procède d’abord à une première phase de crawl, puis procède au rendu de la page après avoir exploré les ressources qui la compose :
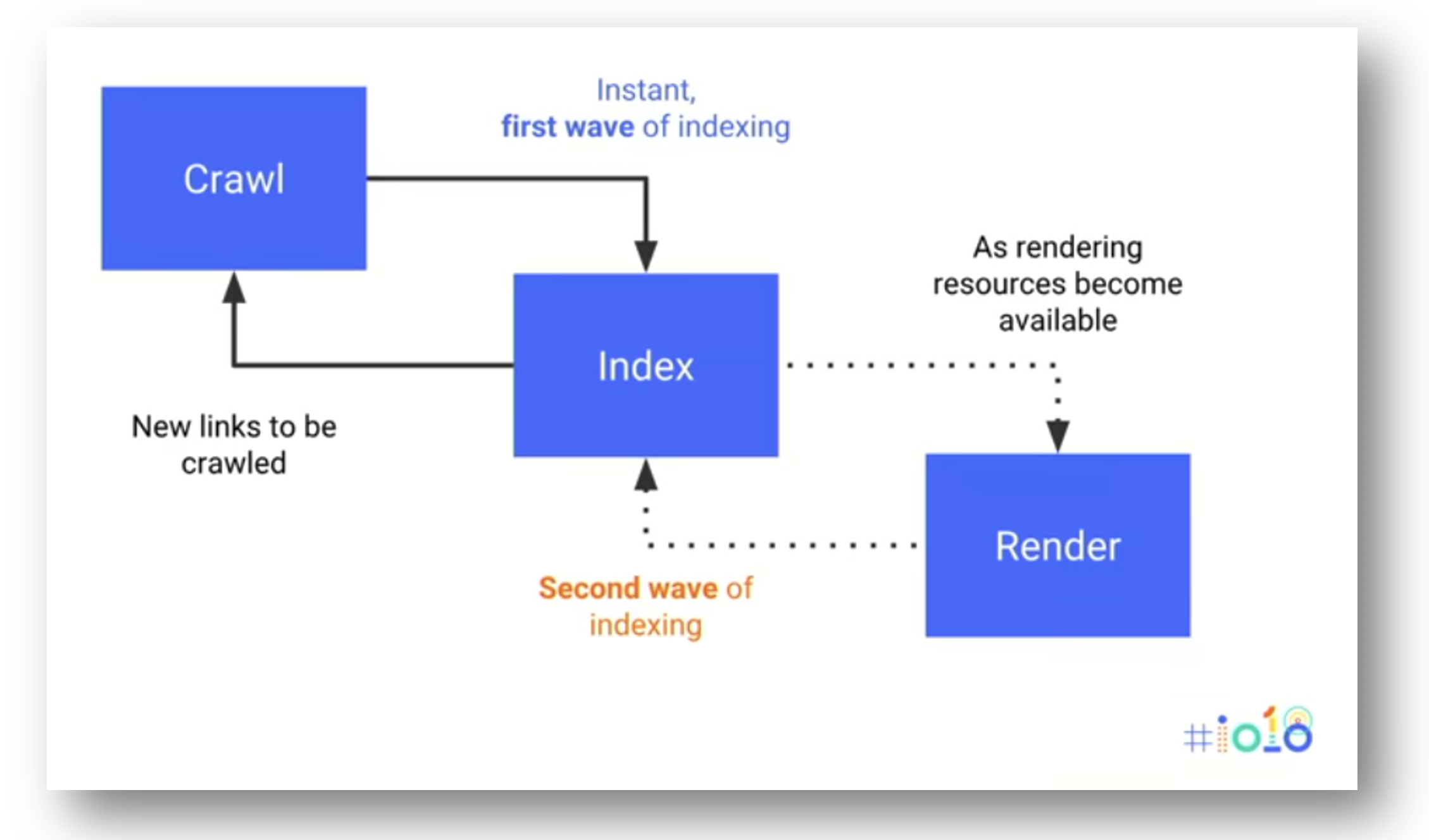
Web Rendering Service et crawl en deux phases
- Google ajoute une URL dans sa file d’attente ;
- Googlebot envoie une requête HTTP vers l’URL ;
- Le HTML brut est traité, et les liens découverts sont extraits ;
- Les nouvelles URL sont ajoutées à la file d’attente ;
- Une fois que les ressources d’une page ont été crawlées, l’URL de la page est dans la file d’attente du moteur de rendu WRS ;
- Le moteur de rendu exécute le Javascript et génère le rendu HTML ;
- Le rendu HTML final est indexé (ou non) et traité par la base d’indexation ;
- Les nouveaux liens découverts dans le rendu HTML sont ajoutés à la file d’attente.
Toutes ces ressources complémentaires (js, css), ainsi que les polices entre autres entrent en ligne de compte dans le calcul du budget d’exploration d’un site : plus vos pages feront appel à un nombre important d’éléments composant la page, plus votre budget d’exploration sera impacté…
Crawl budget : oui, mais pour qui ?
L’exploration de ces différents éléments est consommateur de ressources pour les serveurs de Google, d’autant plus pour les gros sites Web. Les plus gros sites médias français ont plusieurs millions d’URL qui sont crawlées chaque jour par le moteur ! Le Web est si vaste que le processus de découverte de nouvelles URL et d’actualisation des URL déjà connues doit être cadré. Googlebot ne peut pas explorer indéfiniment un site : c’est pour cela que le budget de crawl a été élaboré, mais il ne concerne pas tous les sites Web.
Ainsi, Google indique dans sa documentation que le budget de crawl concerne :
- Les sites très volumineux (plus d’un million de pages uniques) dont le contenu change assez souvent, soit une fois par semaine.
- Les sites de moyenne ou grande taille (plus de 10 000 pages uniques) dont le contenu change quotidiennement.
- Les sites dont une proportion importante d’URL est classifiée comme « Détectée, actuellement non indexée » dans l’outil de Google Search Console.

Crawl budget sur un site important? Source : https://backlinko.com/hub/seo/crawl-budget
Si votre site ne comporte que quelques centaines, voire quelques milliers d’URL, et que le contenu ne change pas souvent, vous n’êtes pas concernés par les problématiques de budget de crawl. Google pourra allouer suffisamment de ressources pour découvrir les nouvelles URL et mettre à jour vos pages déjà connues, sans que vous ayez à vous soucier de sa capacité d’exploration.
La phrase « pendant que Google crawle ces URL, il ne crawle pas d’autres URL plus pertinentes » n’est pas si vraie pour vous : le crawl d’URL non pertinentes ne ralentira pas pour autant le crawl d’URL stratégiques si vous exploitez un site de petite ou moyenne taille (moins de 10 000 URL avec peu de mises à jour).
Deux facteurs clés : besoin d’exploration et capacité d’exploration
Pour déterminer le budget de crawl d’un site, le moteur doit trouver un équilibre entre 2 facteurs qui sont le besoin d’exploration d’un site et la capacité d’exploration de Google de ce site. En combinant ces deux critères, Google définit son budget d’exploration pour un site (ensemble d’URL que Google peut et veut crawler).
Besoins d’exploration
Il existe trois critères qui jouent un rôle crucial pour déterminer les besoins d’exploration que Google va avoir vis-à-vis d’un site Web.
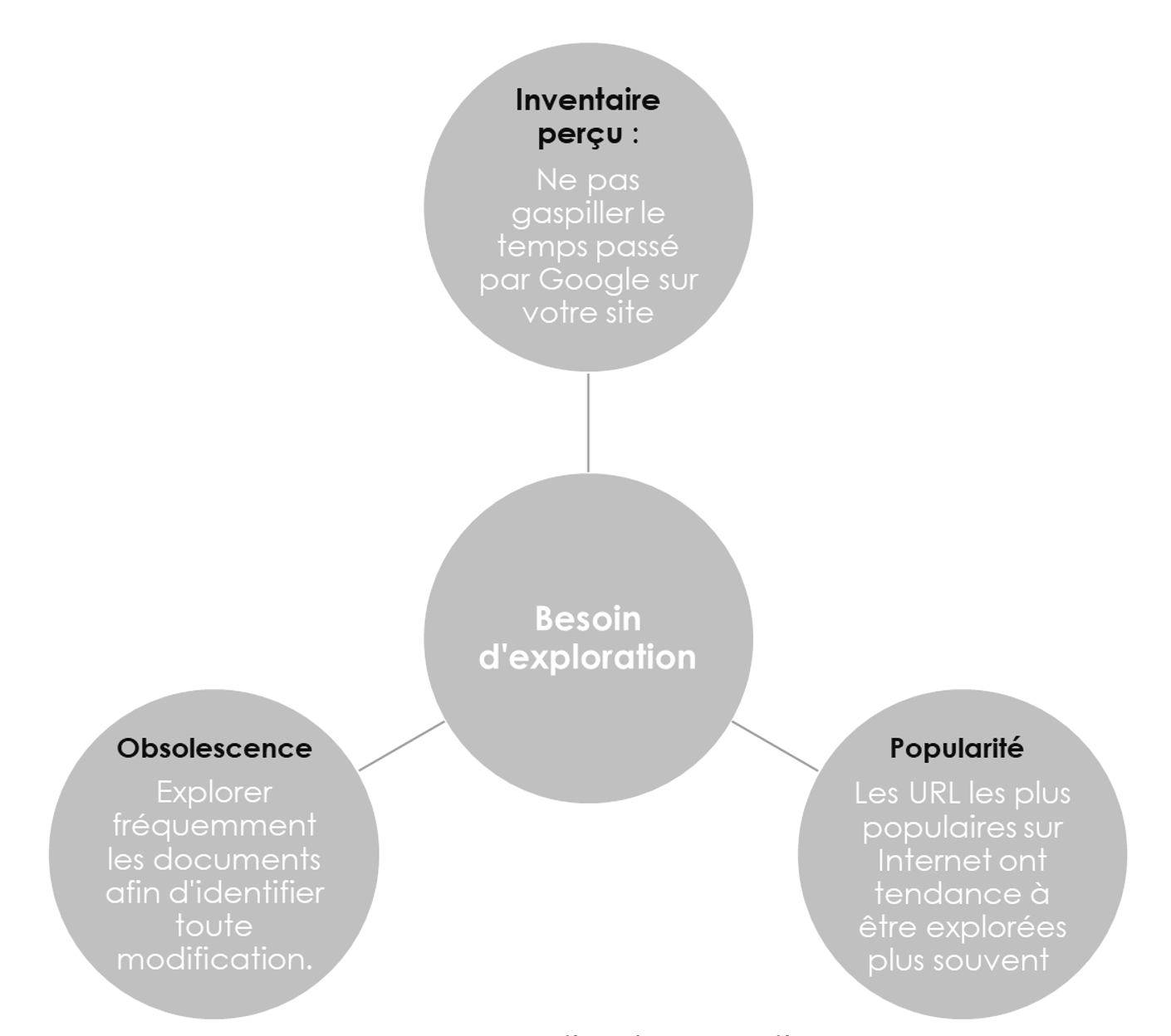
Besoin d’exploration d’un site
Inventaire perçu : Google va effectuer un inventaire de votre site web, en explorant la totalité ou la plupart des URL de votre site dont il a pris connaissance lors de son processus d’exploration. Une part des URL peuvent ne pas être explorées immédiatement : « Détectée, actuellement non explorée » ou « Détectée, actuellement non indexée » dans la Search Console. Dans le premier cas, il est probable que l’URL soit encore dans la file d’attente de Googlebot, et dans le second cas, il est possible que les signaux soient trop faibles pour inciter Google à explorer l’URL pour l’ajouter à son index.
Si aucune consigne n’a été donnée, Googlebot risque d’explorer des URL en doublons, des URL peu pertinentes ou sans importance pour votre SEO : cela gaspillera une partie du temps passé par Google à explorer votre site, et grossira l’inventaire perçu de façon inutile (thin content, duplicate content, etc.). Ce critère est parmi les plus faciles à maîtriser, grâce à l’utilisation des directives du fichier robots.txt, et à la structure du maillage interne de votre site.
Popularité : Plus vos URL recevront de liens, plus elles se retrouveront régulièrement dans la file d’attente des URL à explorer : la fréquence de crawl d’une URL est intimement liée à sa popularité. Google explore plus souvent les URL populaires afin qu’elles soient le plus à jour possible dans son index, pour satisfaire l’internaute.
Obsolescence : L’un des objectifs des systèmes de Google est d’explorer fréquemment les documents pour détecter toute modification, afin de présenter des résultats à jour aux internautes dans ses pages de résultats. En effet, une page qui n’a pas été explorée depuis un certain laps de temps pourrait avoir subi des modifications, Google risquerait donc de présenter des contenus qui ne sont pas en phase avec la dernière version de la page connue… Il a d’ailleurs été constaté par des confrères qu’une page qui n’aurait pas été crawlée depuis plusieurs semaines rencontrerait des difficultés à se positionner, des vérifications sont à faire en ce sens.
L’algorithme de crawl de Google effectue donc un juste équilibre pour chaque site à partir de ces 3 critères, afin de déterminer son besoin d’exploration. Mais un autre facteur rentre en ligne de compte pour l’exploration de votre site : sa capacité d’exploration qui dépend de plusieurs critères également.
Capacité d’exploration
Google doit explorer votre site, tout en évitant de surcharger vos serveurs (c’est le discours officiel, mais on peut se douter que c’est également lié à la forte consommation d’énergie de ses datacenters).

Google datacenter –
Source : https://en.wikipedia.org/wiki/Google_data_centers#/media/File:Google_Mayes_County_P0004991a.jpg
C’est en cela qu’il limite la capacité d’exploration d’un site : il évalue le nombre maximal de connexions simultanées en parallèle que Googlebot peut utiliser pour explorer un site, ainsi que le temps qu’il doit attendre entre deux explorations pour éviter toute surcharge. Si Google détecte un ralentissement du serveur avec un nombre trop élevé de connexions simultanées, il réduira cette valeur afin de pouvoir explorer l’ensemble de vos URL, sans pour autant surcharger vos serveurs.
Certains sites peuvent recevoir plus 50 connexions simultanées, et tant le besoin d’exploration est élevé et que le serveur arrive à supporter la charge, Googlebot n’hésitera pas à garder ce rythme.
Cette capacité d’exploration varie également en fonction de deux autres critères:
Limite définie par le propriétaire du site dans la Search Console
Il est toujours possible via l’ancienne interface de la Search Console (Google Webmaster Tools) de réduire la fréquence de crawl d’un site, dans le cas où le crawl de Google sera trop important et créerait d’autres ralentissement sur les serveurs, qui ne seraient pas détectés par Google. C’est via cette URL qu’on pourra accéder à ce réglage : https://www.google.com/webmasters/tools/settings

Gestion de la fréquence d’exploration dans les outils de Google
Il n’est pas recommandé de modifier ce paramètre, mais dans le cas où Google aurait un comportement anormal et impacterait les performances de votre serveur, cela peut s’avérer utile.
Limites d’exploration de Google
Google dispose d’un nombre extrêmement important de ressources, mais elles ne sont pas infinies… Il doit donc effectuer des arbitrages pour pouvoir traiter l’ensemble des URL qu’il a découvert. A noter que la capacité d’exploration sera plus importante sur des sites d’autorité (et donc populaires). Ça n’est pas parce qu’un site reçoit peu de hits de la part de Google qu’il souffre forcément d’un problème de crawl budget. Tant que les besoins d’exploration sont couverts, Google n’essayera pas de crawler jusqu’à sa capacité maximale d’exploration. Il faut voir ce seuil comme une limite haute de son crawl, et non comme un seuil à franchir à tout prix.
Un juste équilibre
En fonction de l’évolution de votre site dans le temps, mais également de sa typologie, la fréquence du crawl pour avoir des URL fraîches dans l’index est variable, et sera adaptée au fil du temps via différentes méthodes d’apprentissage. Google effectuera l’exploration de votre site tout en dosant le besoin d’exploration versus sa capacité d’exploration.
Nous constatons malgré tout que Googlebot peut augmenter sa fréquence exploration en fonction des besoins : lors d’une migration, ou de la modification d’un grand nombre de pages, le crawl de Googlebot va augmenter de façon temporaire afin d’accélérer la prise en compte des modifications, tout en respectant les limites définies par sa capacité d’exploration du site.
Compréhension des données dans la Search Console
Statistiques sur l’exploration
L’ensemble des données relatives à l’exploration du moteur est disponible dans la Search Console via le menu « Paramètres », puis « Statistiques sur l’exploration » : https://search.google.com/u/1/search-console/settings/crawl-stats
Impact du temps de chargement sur le budget de crawl
Voici quelques exemples afin d’illustrer l’impact d’un serveur rapide sur le budget d’exploration :
Augmentation du temps de réponse du serveur :
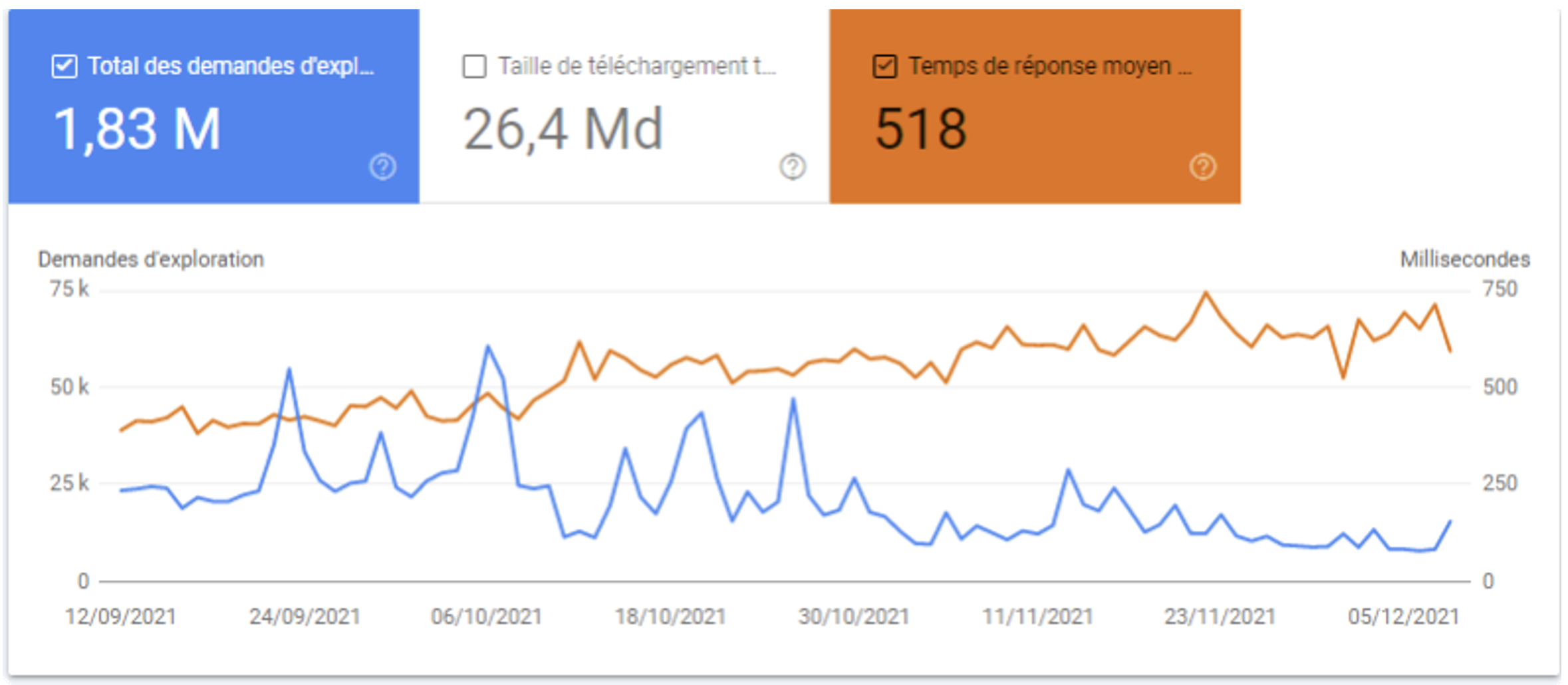
Baisse du budget crawl
Nous constatons ci-dessus une érosion lente et progressive du nombre total des demandes d’exploration. Au-delà de 500ms en temps de réponse, le crawl ralentit de façon assez visible.
Légère augmentation du temps de réponse du serveur :
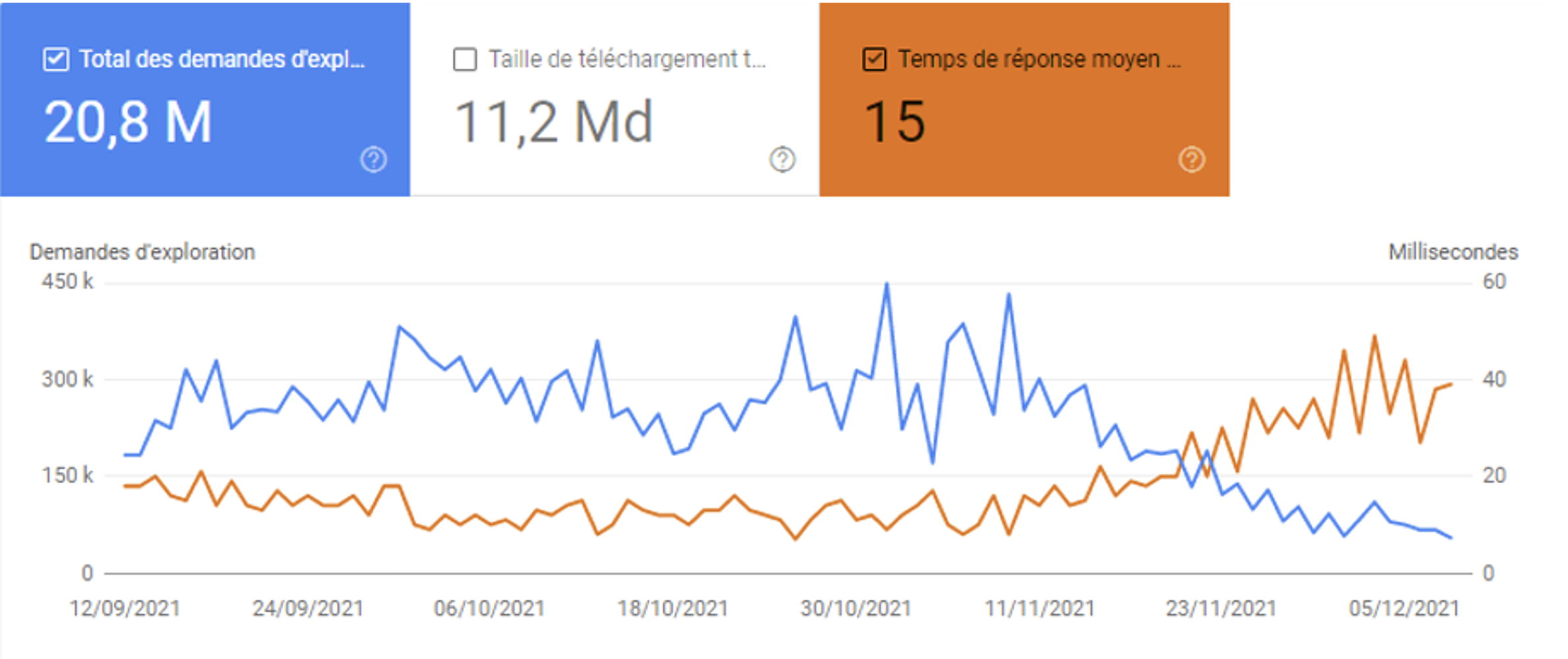
Augmentation du budget de crawl
Dans cet autre exemple, nous constatons un temps de réponse plus que correct (environ 20ms, qui passe à 40 ms en moins d’un mois). L’impact est sans appel : le budget d’exploration est quasiment divisé par deux.
Le comportement n’est pas le même pour tous les sites, car pour un site équivalent en nombre de pages, une augmentation de 20ms n’aurait pas eu le même impact : plusieurs critères rentrent en ligne de compte dans le calcul du budget d’exploration, et Google évalue sa fréquence de crawl en fonction des multiples critères cités précédemment.
Erreurs d’interprétation
Dans certains cas, il ne faut pas faire de conclusions trop hâtives non plus : la Search Console et une mauvaise connaissance d’un site peuvent mener à des interprétations erronées.
Dans l’exemple ci-dessous, on pourrait croire qu’une baisse du temps de réponse (en orange) a augmenté le budget de crawl de façon conséquente (en bleu). En réalité, il s’agit du suivi temporaire de nombreuses redirections 301 à un instant T, qui ont répondu plus rapidement que l’ensemble des URL du site. Cela donne une fausse impression d’amélioration du budget d’exploration, alors qu’en réalité il s’agit d’URL rapides que Google a eu besoin de mettre à jour.
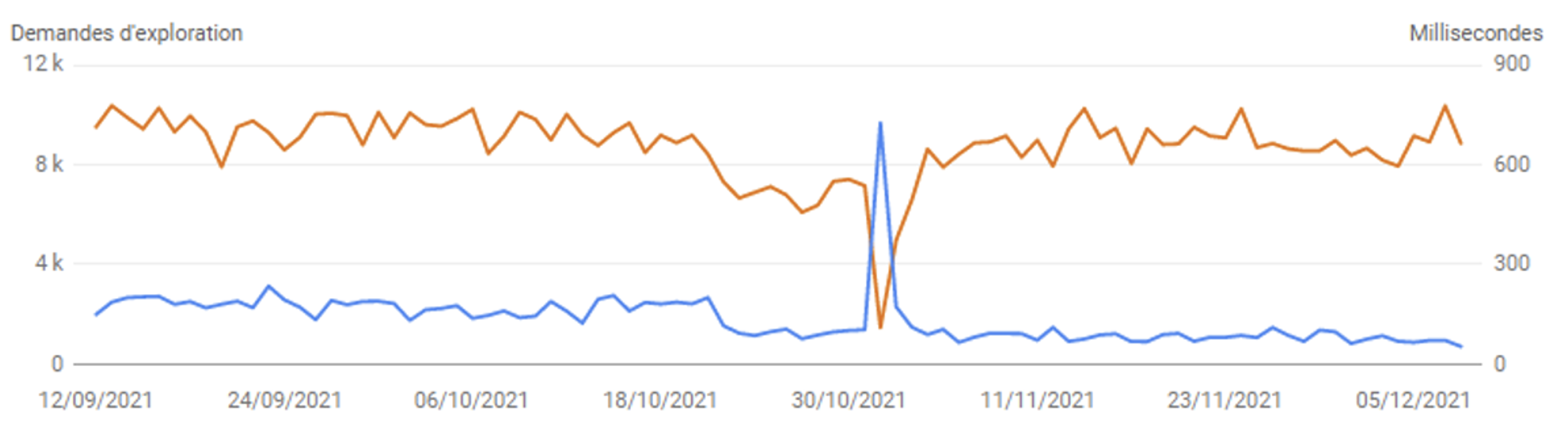
Temps de réponse faible lors de la prise en compte de redirections 301
Optimiser son crawl budget
Il est clair que le budget de crawl est très impactant sur des sites ayant une importante volumétrie de page, ou des sites intermédiaires avec un besoin de mise à jour important. Mais il faut garder en tête que pour des petits sites, vous n’avez pas à vous soucier de son optimisation, car Google arrivera à s’en sortir sans problèmes.
Nous verrons dans un prochain article comment mieux utiliser la Search console pour comprendre l’impact du budget de crawl et verrons comment optimiser celui-ci. À très bientôt !
Pour en savoir plus :
https://developers.google.com/search/docs/fundamentals/how-search-works

![Les étapes essentielles pour une refonte d’arborescence réussie [Le Point]](https://www.reacteur.com/content/uploads/2025/03/2025-02-reacteur-julien-ferras-527x297.png)
![Les étapes essentielles pour une refonte d’arborescence réussie [Le Point]](https://www.reacteur.com/content/uploads/2025/03/2025-02-reacteur-julien-ferras-190x190.png)





![Comment utiliser l'IA et la data pour augmenter vos études sémantiques ? [Partie 2] - Franck Mairot](https://www.reacteur.com/content/uploads/2024/09/2024-09-reacteur-franck-mairot.png)
5
4.5