
 Le « Budget crawl » représente les ressources de temps-machine allouées par un moteur de recherche à l’exploration de votre site. Cette notion, dont on parle très souvent depuis quelques temps, doit être prise en compte dans certains cas. Alors, comment Google calcule-t-il ce « crawl budget » et surtout, votre site est-il concerné ? Après les définitions le mois dernier, il est temps de voir ce mois-ci les différents points à prendre en compte pour améliorer ce budget d’exploration de votre site par les robots.
Le « Budget crawl » représente les ressources de temps-machine allouées par un moteur de recherche à l’exploration de votre site. Cette notion, dont on parle très souvent depuis quelques temps, doit être prise en compte dans certains cas. Alors, comment Google calcule-t-il ce « crawl budget » et surtout, votre site est-il concerné ? Après les définitions le mois dernier, il est temps de voir ce mois-ci les différents points à prendre en compte pour améliorer ce budget d’exploration de votre site par les robots.
 Le « Budget crawl » représente les ressources de temps-machine allouées par un moteur de recherche à l’exploration de votre site. Cette notion, dont on parle très souvent depuis quelques temps, doit être prise en compte dans certains cas. Alors, comment Google calcule-t-il ce « crawl budget » et surtout, votre site est-il concerné ? Après les définitions le mois dernier, il est temps de voir ce mois-ci les différents points à prendre en compte pour améliorer ce budget d’exploration de votre site par les robots.
Le « Budget crawl » représente les ressources de temps-machine allouées par un moteur de recherche à l’exploration de votre site. Cette notion, dont on parle très souvent depuis quelques temps, doit être prise en compte dans certains cas. Alors, comment Google calcule-t-il ce « crawl budget » et surtout, votre site est-il concerné ? Après les définitions le mois dernier, il est temps de voir ce mois-ci les différents points à prendre en compte pour améliorer ce budget d’exploration de votre site par les robots.Le budget d’exploration ou budget crawl (décrit dans la newsletter du mois de Novembre 2022) concerne essentiellement deux types de site :
- les sites avec une grosse volumétrie de page (> 100.000 URL).
- les sites avec un nombre plus restreint d’URL (minimum 10 000 URL) dont le contenu de la majeure partie des pages change quotidiennement. En complément, cela peut également concerner votre site si ce dernier comporte un nombre non négligeable d’URL qui sont considérées comme « Détectées, actuellement non indexées » dans la section « Pages » de l’outil Search Console de Google. Cela signifie qu’il a détecté un certain nombre d’URL pour lesquelles il ne disposait de pas suffisamment de ressources pour les explorer.
Nous traiterons donc ces derniers sites dans cet article.
Afin qu’il n’impacte pas la façon dont Google doit crawler votre site, plusieurs corrections et optimisations sont nécessaires afin de limiter au maximum le crawl d’URL non pertinentes. Mais avant tout, il est important d’avoir des données sur son crawl.
[box type= »info »] Pour aller plus loin :
➜ Découvrez la formation Crawl et indexation par Olivier Andrieu
[/box]
Les outils pour surveiller l’exploration de Google
La Search Console
Les statistiques sur l’exploration de la Search Console, qui se trouvent dans la section « Paramètres » de l’outil donnent des indications importantes sur la façon dont Google crawle votre site. Une baisse des demandes d’exploration peut signifier plusieurs choses, notamment le fait que le site répond trop lentement, ou qu’il rencontre des difficultés d’exploration.
Suivi des codes réponses
Le bloc « Par réponse » donne notamment des indications sur les codes réponses renvoyés par le serveur.
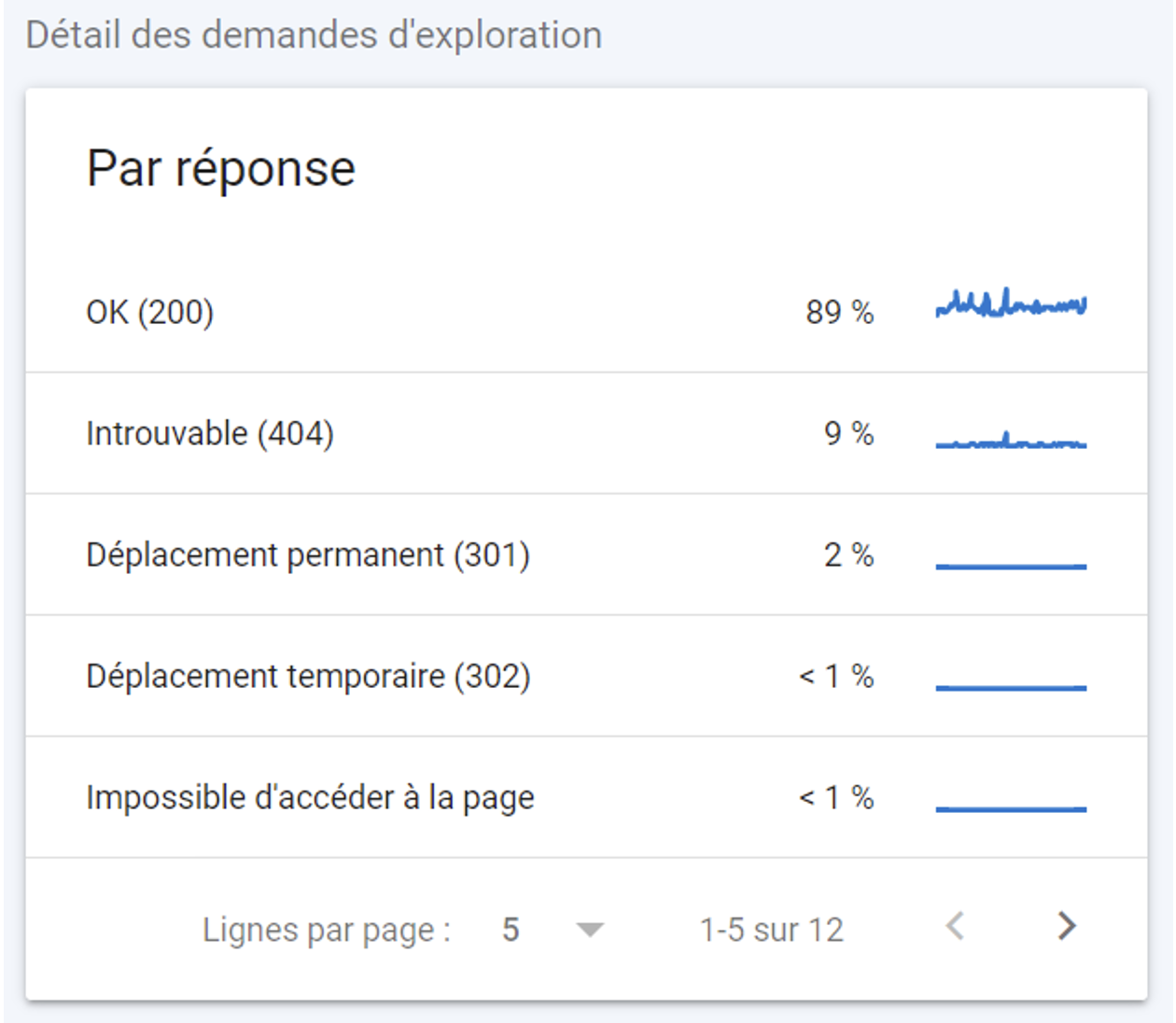
Codes réponses reçus par Google lors de son crawl













![Les étapes essentielles pour une refonte d’arborescence réussie [Le Point]](https://www.reacteur.com/content/uploads/2025/03/2025-02-reacteur-julien-ferras-527x297.png)
![Les étapes essentielles pour une refonte d’arborescence réussie [Le Point]](https://www.reacteur.com/content/uploads/2025/03/2025-02-reacteur-julien-ferras-190x190.png)
5
Merci pour cet excellent article!
Petite question, concernant les URL non pertinentes, peuvent elles être des URL à très faible potentiel par exemple? l’idée est de réduire de manière importante le nombre de pages à crawler tout en laissant ces url accessibles via le moteur interne.
Merci
Charles